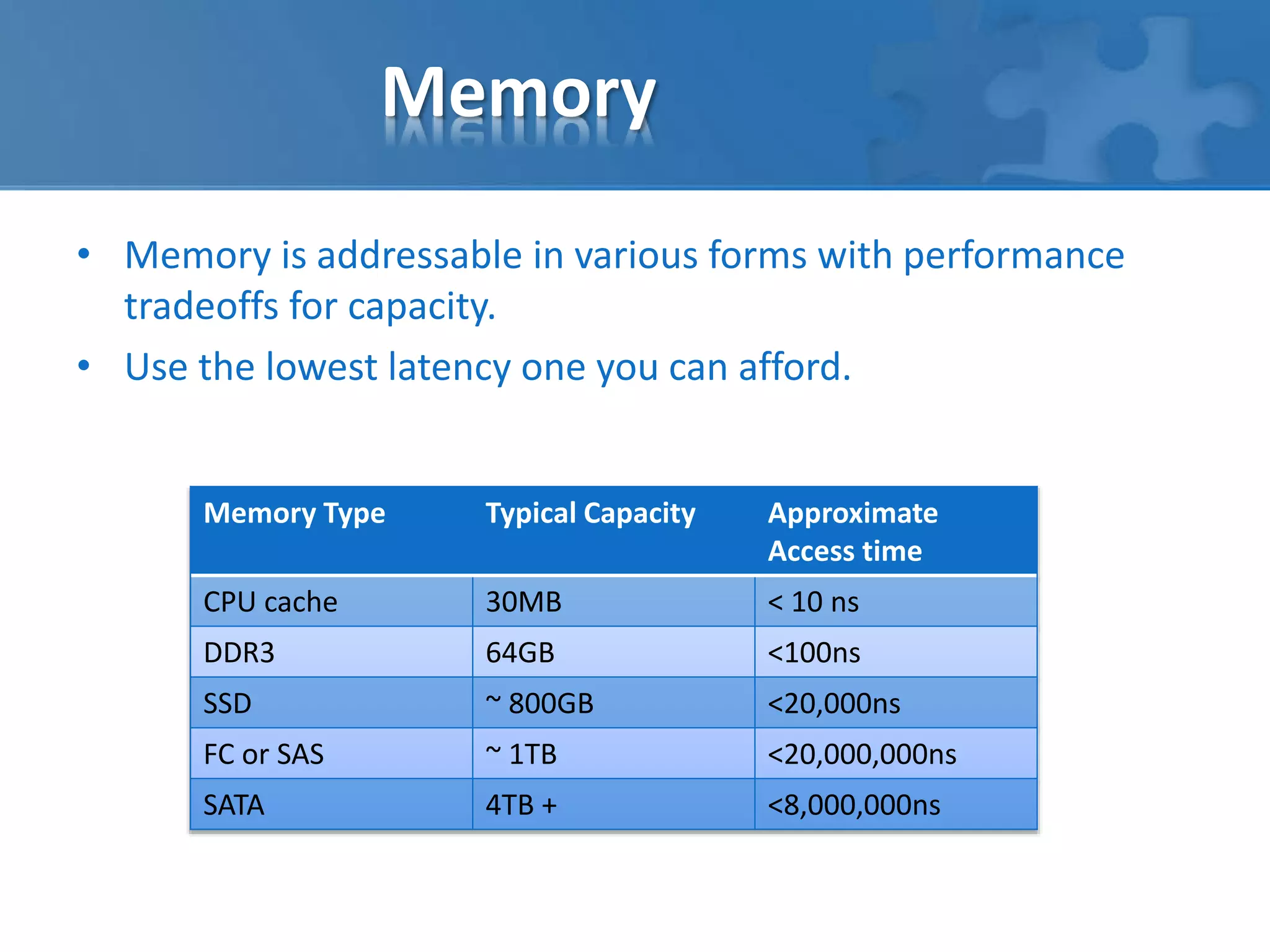
The document discusses the challenges faced by applications as they scale, including performance and reliability issues due to growing data sets and operational inefficiencies. It emphasizes the importance of understanding workload differences, modern storage technologies, and the necessity of optimizing memory, network, and SQL database performance, while suggesting best practices for backups and reporting. It also highlights the need to adapt to evolving technologies and methodologies to ensure sustained app functionality and performance.