












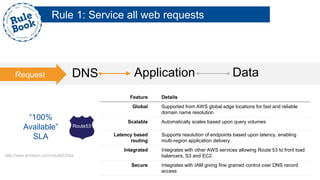

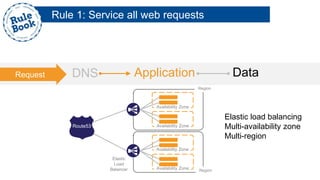
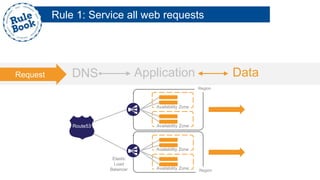
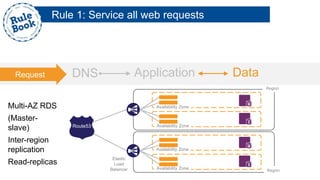


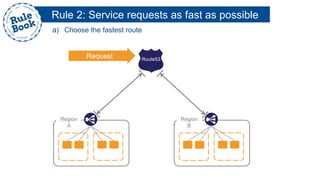
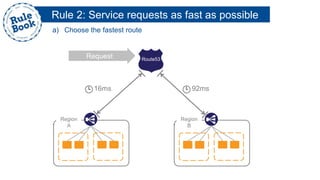
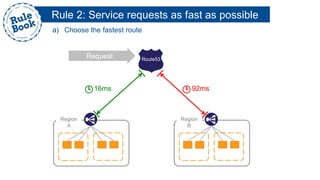
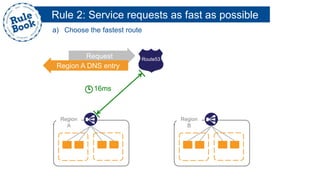
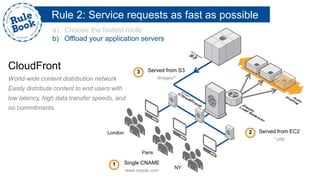
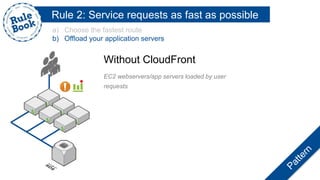
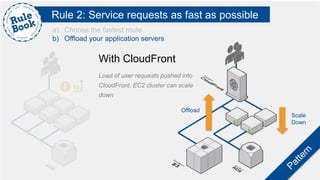
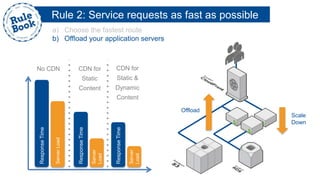
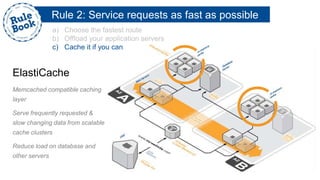

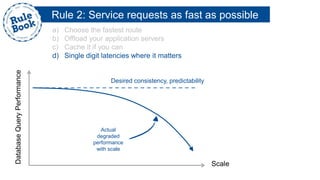
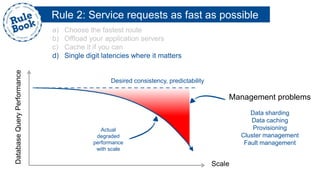
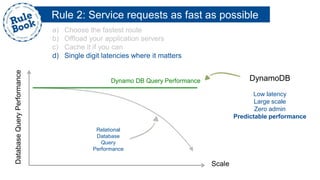
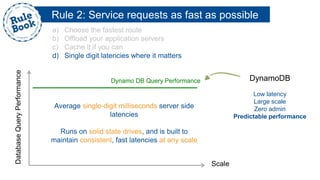

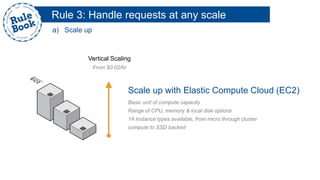
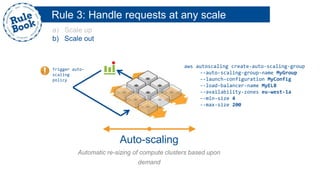






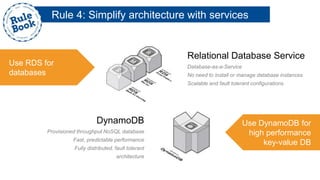
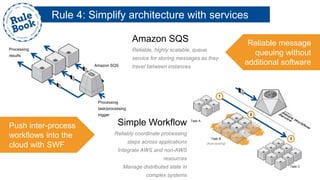
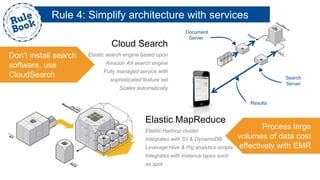

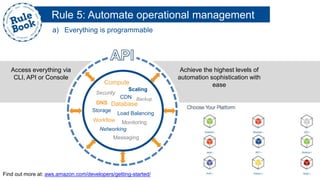




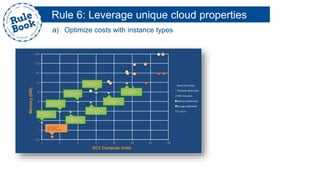
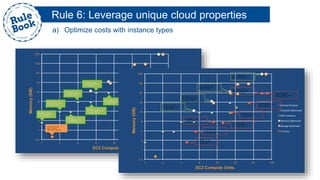

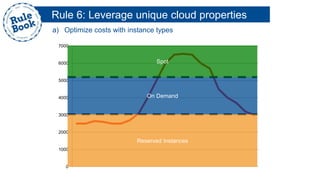
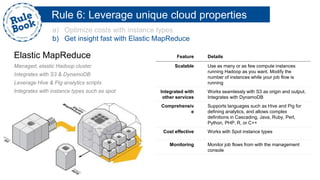
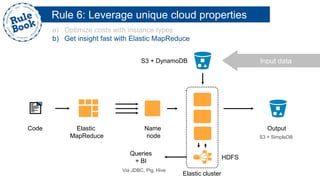
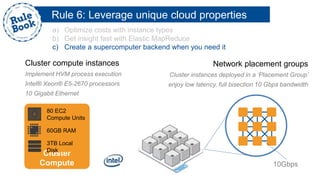







The document outlines the advantages of using AWS for scalable web applications, highlighting key use cases such as Reddit and Expedia that demonstrate the platform's capability to manage significant traffic and improve operational efficiency. It provides a 'rule book' with best practices for optimizing performance, handling requests at scale, and automating management tasks. Additionally, it discusses various AWS services and tools that facilitate the development of resilient and cost-effective cloud-based architectures.























































