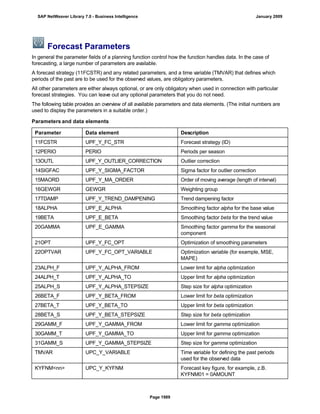
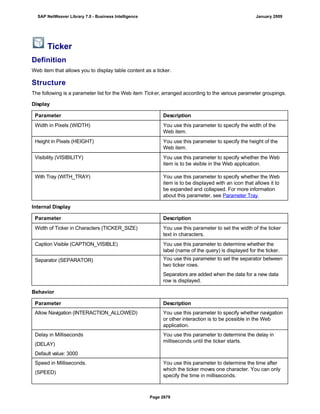
Downloaded 82 times





















































































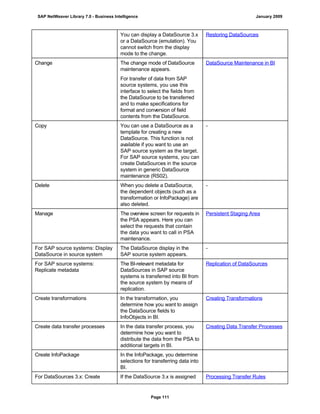


















































































































































































































































































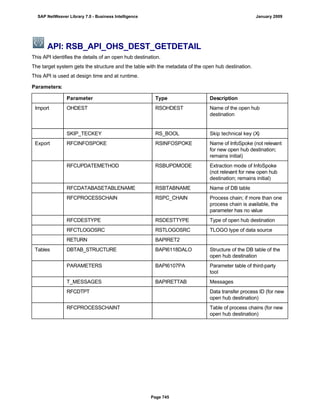
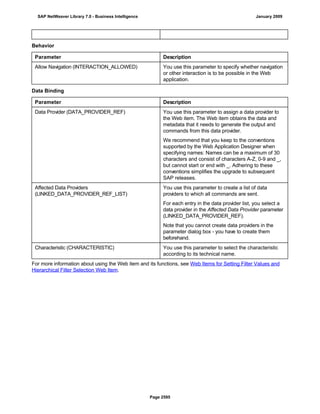
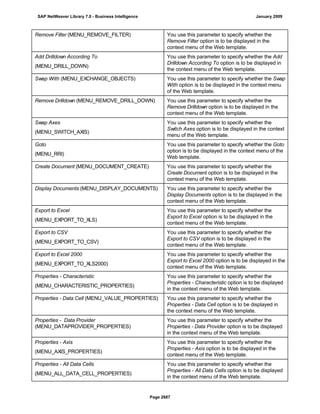
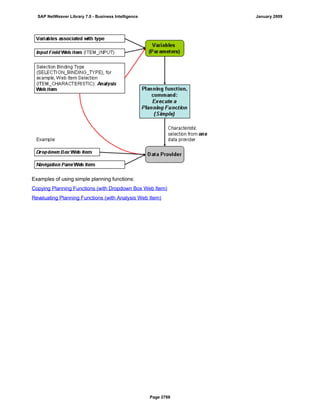
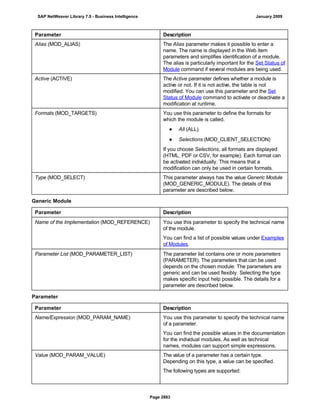
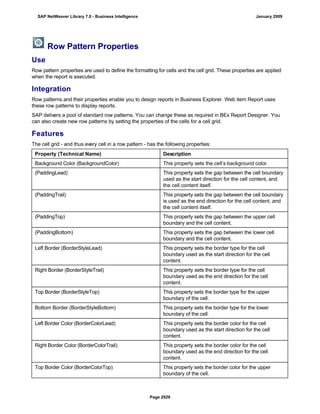
![● AS4_HOST: Host name for the Remote DB Server. You have to enter the host name in the
same format as is used under TCP/IP or OptiConnect, according the connection type you
are using.
You have to specify the AS4_HOST parameter.
● AS4_DB_LIBRARY: Library that the DB server job needs to use as the current library on
the remote DB server.
You have to enter parameter AS4_DB_LIBRARY.
● AS4_CON_TYPE: Connection type; permitted values are OPTICONNECT and SOCKETS.
SOCKETS means that a connection is used using TCP/IP sockets.
Parameter AS4_CON_TYPE is optional. If you do not enter a value for this parameter, the
system uses connection type SOCKETS.
For a connection to the remote DB server as0001 on the RMTLIB library using
TCP/IP sockets, you have to enter:
AS4_HOST=as0001;AS4_DB_LIBRARY=RMTLIB;AS4_CON_TYPE=SOCKETS;
The syntax must be exactly as described above. You cannot have any additional blank spaces
between the entries and each entry has to end with a semicolon. Only the optional parameter
AS4_CON_TYPE=SOCKETS can be omitted.
(See SAP Note 146624 - AS/400: Database MultiConnect with EXEC SQL)
(For DB MultiConnect from Windows AS to iSeries, see Note 445872)
DB2 UDB
(db6)
DB6_DB_NAME=<db_name>
, where <db_name> is the name of the DB2 UDB database on which you want to run Connect.
You want to establish a connection to the ‘mydb’ database. Enter
DB6_DB_NAME=mydb as the connection information.
(See SAP Note 200164 - DB6: Database MultiConnect with EXEC SQL)
7. Specify whether your database connection needs to be permanent or not.
If you set this indicator, losing an open database connection (for example due to a breakdown in the
database itself or in the database connection [network]) has a negative impact.
Regardless of whether this indicator is set, the SAP work process tries to reinstate the lost connection. If
this fails, the system responds as follows:
a. The database connection is not permanent, which means that the indicator is not set:
The system ignores the connection failure and starts the requested transaction. However, if this
transaction accesses the connection that is no longer available, the transaction terminates.
b. The database connection is permanent, which means that the indicator is set:
After the connection terminates for the first time, each transaction is checked to see if the
connection can be reinstated. If this is not possible, the transaction is not started – independently
of whether the current transaction would access this special connection or not. The SAP system
can only be used again once all the permanent DB connections have been reestablished.
We recommend setting the indicator if an open DB connection is essential or if it is accessed often.
SAP NetWeaver Library 7.0 - Business Intelligence January 2009
Page 401](https://image.slidesharecdn.com/sapbi7-141218085854-conversion-gate02/85/SAP-BI-7-0-Info-Providers-404-320.jpg)


















































































































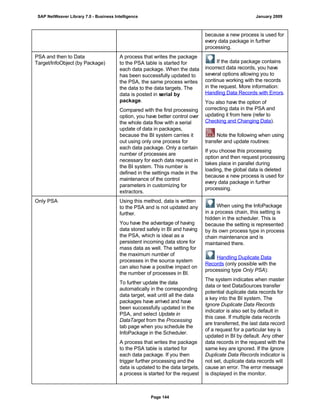
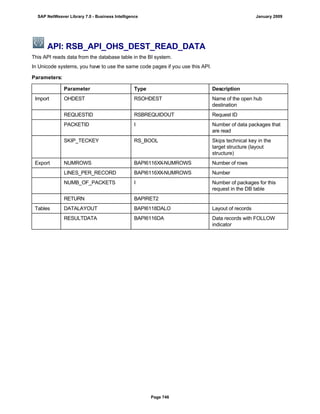
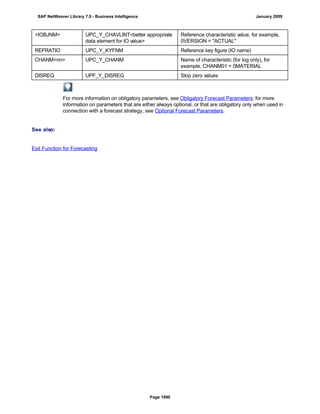
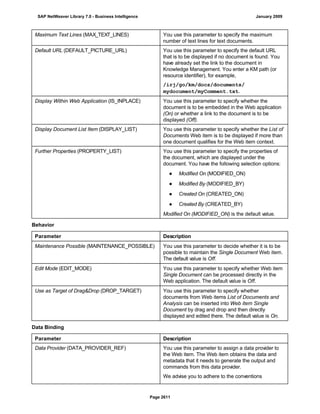
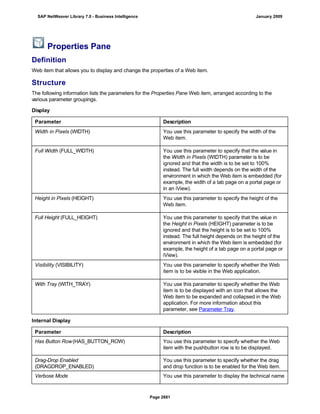
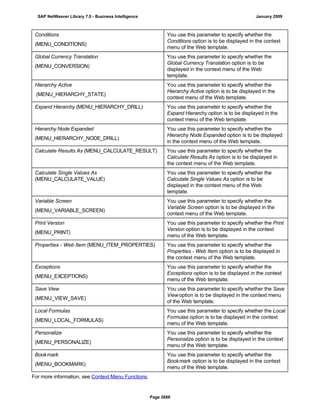
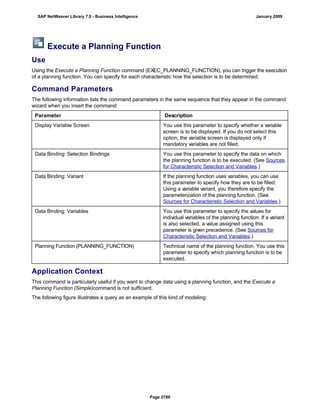
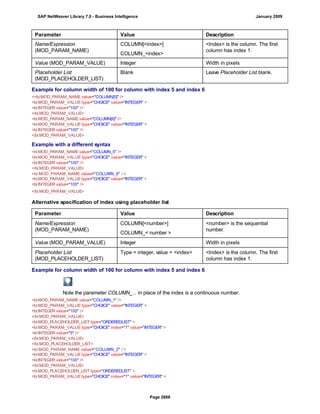
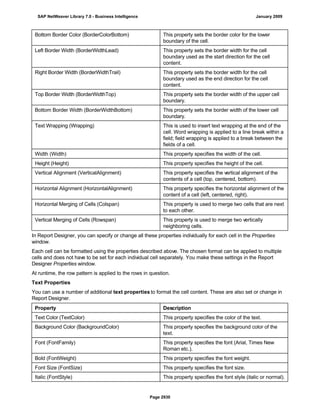
![● AS4_HOST: Host name for the Remote DB Server. You have to enter the host name in the
same format as is used under TCP/IP or OptiConnect, according the connection type you
are using.
You have to specify the AS4_HOST parameter.
● AS4_DB_LIBRARY: Library that the DB server job needs to use as the current library on
the remote DB server.
You have to enter parameter AS4_DB_LIBRARY.
● AS4_CON_TYPE: Connection type; permitted values are OPTICONNECT and SOCKETS.
SOCKETS means that a connection is used using TCP/IP sockets.
Parameter AS4_CON_TYPE is optional. If you do not enter a value for this parameter, the
system uses connection type SOCKETS.
For a connection to the remote DB server as0001 on the RMTLIB library using
TCP/IP sockets, you have to enter:
AS4_HOST=as0001;AS4_DB_LIBRARY=RMTLIB;AS4_CON_TYPE=SOCKETS;
The syntax must be exactly as described above. You cannot have any additional blank spaces
between the entries and each entry has to end with a semicolon. Only the optional parameter
AS4_CON_TYPE=SOCKETS can be omitted.
(See SAP Note 146624 - AS/400: Database MultiConnect with EXEC SQL)
(For DB MultiConnect from Windows AS to iSeries, see Note 445872)
DB2 UDB
(db6)
DB6_DB_NAME=<db_name>
, where <db_name> is the name of the DB2 UDB database on which you want to run Connect.
You want to establish a connection to the ‘mydb’ database. Enter
DB6_DB_NAME=mydb as the connection information.
(See SAP Note 200164 - DB6: Database MultiConnect with EXEC SQL)
7. Specify whether your database connection needs to be permanent or not.
If you set this indicator, losing an open database connection (for example due to a breakdown in the
database itself or in the database connection [network]) has a negative impact.
Regardless of whether this indicator is set, the SAP work process tries to reinstate the lost connection. If
this fails, the system responds as follows:
a. The database connection is not permanent, which means that the indicator is not set:
The system ignores the connection failure and starts the requested transaction. However, if this
transaction accesses the connection that is no longer available, the transaction terminates.
b. The database connection is permanent, which means that the indicator is set:
After the connection terminates for the first time, each transaction is checked to see if the
connection can be reinstated. If this is not possible, the transaction is not started – independently
of whether the current transaction would access this special connection or not. The SAP system
can only be used again once all the permanent DB connections have been reestablished.
We recommend setting the indicator if an open DB connection is essential or if it is accessed often.
SAP NetWeaver Library 7.0 - Business Intelligence January 2009
Page 525](https://image.slidesharecdn.com/sapbi7-141218085854-conversion-gate02/85/SAP-BI-7-0-Info-Providers-528-320.jpg)




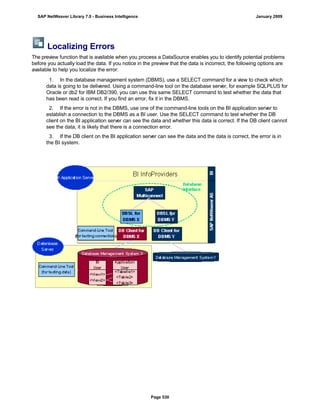

























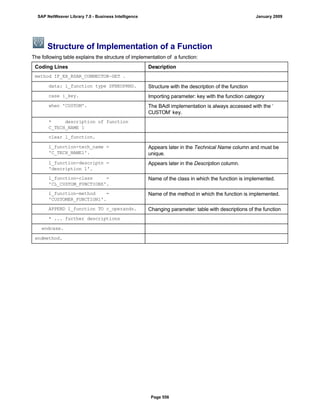

































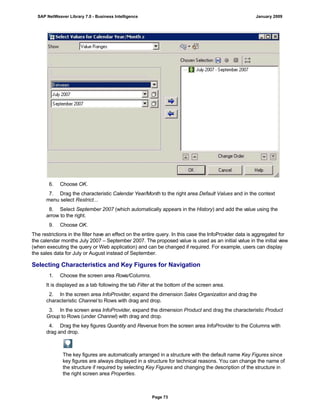
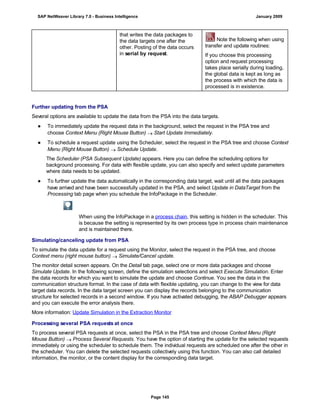
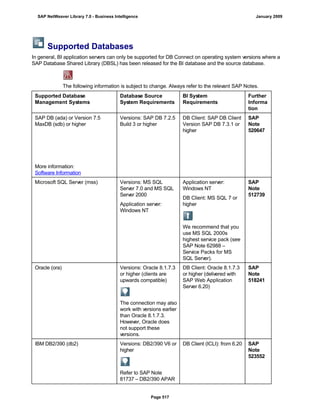
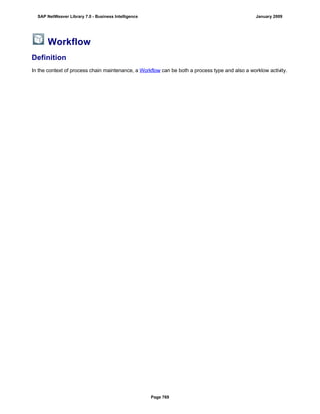
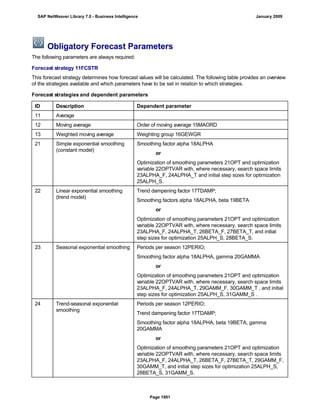
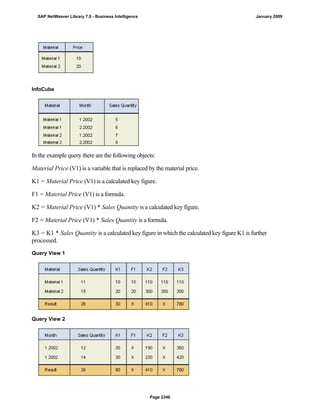
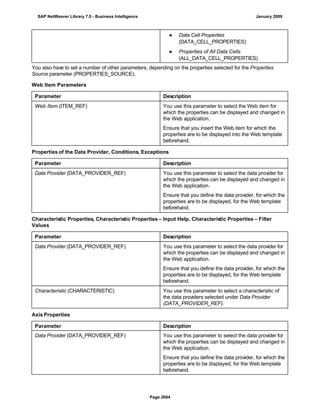
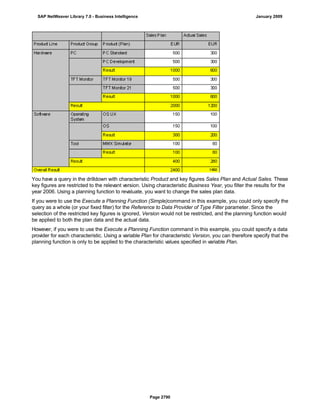
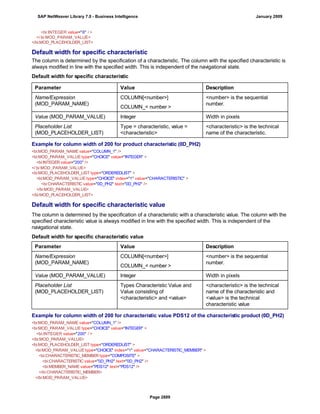
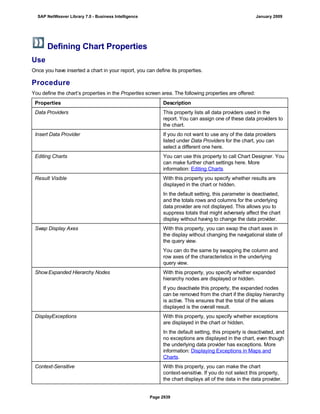
![Regular Expressions in Routines
Use
You can use regular expressions in routines.
A regular expression (abbreviation: RegExp or Regex) is a pattern of literal and special characters which
describes a set of character strings. In ABAP, you can use regular expressions in the FIND and REPLACE
statements, and in classes CL_ABAP_REGEXand CL_ABAP_MATCHER. For more information, see the ABAP
key word documentation in the ABAP Editor. This documentation describes the syntax of regular expressions
and you can test regular expressions in the ABAP Editor.
Example
This section provides sample code to illustrate how you can use regular expressions in routines.
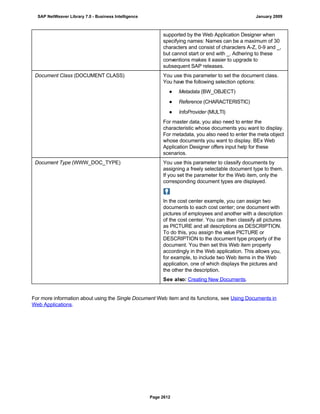
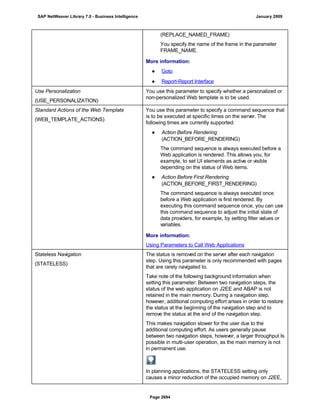
REPORT z_regex.
DATA: l_input TYPE string,
l_regex TYPE string,
l_new TYPE string.
* Example 1: Insert thousand separator
l_input = '12345678'.
l_regex = '([0-9])(?=([0-9]{3})+(?![0-9]))'.
l_new = '$1,'.
WRITE: / 'Before:', l_input. "12345678
REPLACE
ALL OCCURRENCES OF
REGEX l_regex
IN l_input WITH l_new.
WRITE: / 'After:', l_input. "12,345,678
* Example 2: Convert date in US format to German format
l_input = '6/30/2005'.
l_regex = '([01]?[0-9])/([0-3]?[0-9])/'.
l_new = '$2.$1.'.
WRITE: / 'Before:', l_input. "6/30/2005
REPLACE
ALL OCCURRENCES OF
REGEX l_regex
IN l_input WITH l_new.
WRITE: / 'After:', l_input. "30.6.2005
* Example 3: Convert external date in US format to internal date
DATA: matcher TYPE REF TO cl_abap_matcher,
submatch1 TYPE string,
submatch2 TYPE string,
SAP NetWeaver Library 7.0 - Business Intelligence January 2009
Page 592](https://image.slidesharecdn.com/sapbi7-141218085854-conversion-gate02/85/SAP-BI-7-0-Info-Providers-595-320.jpg)
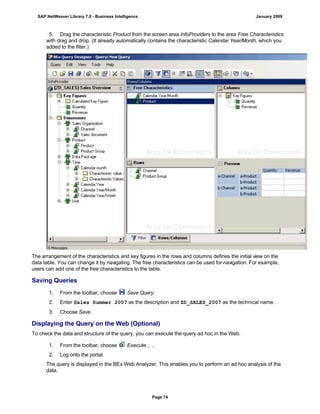
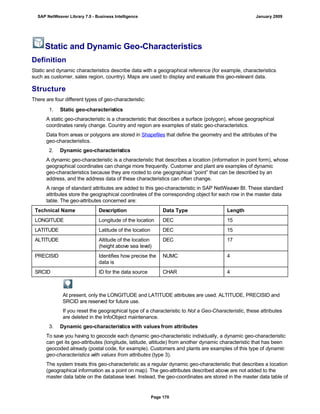
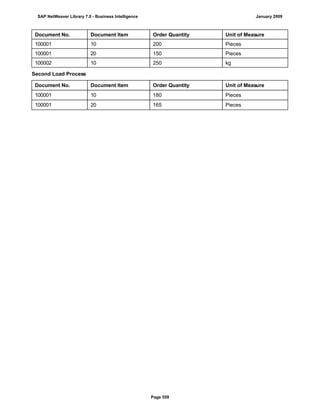
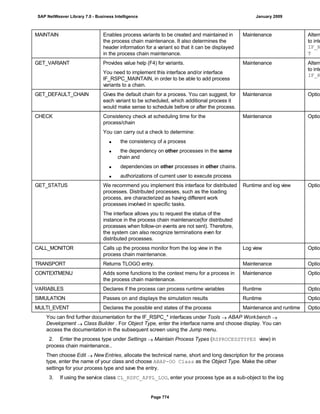
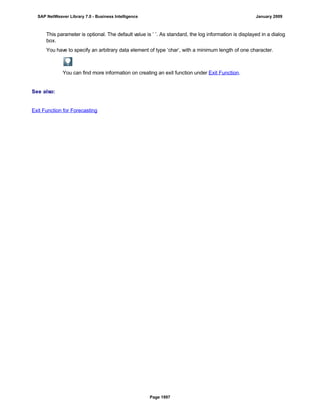
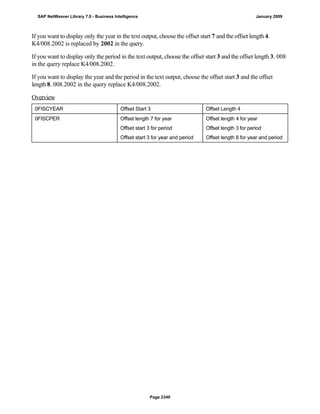
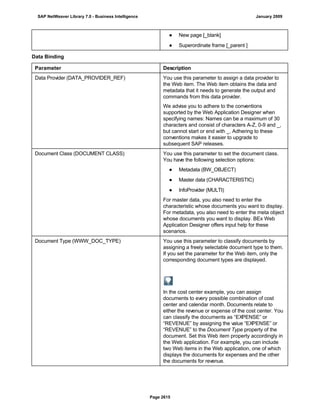
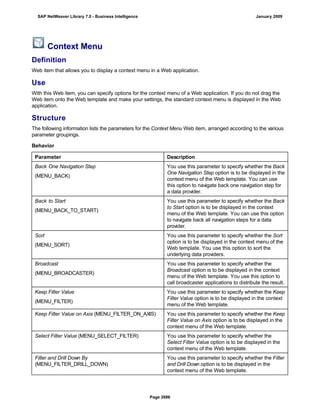
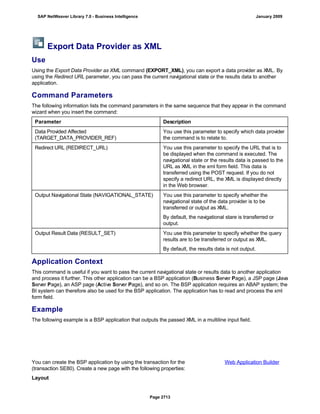
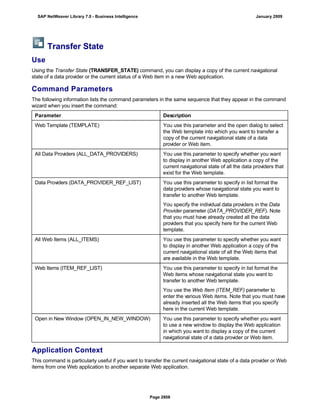
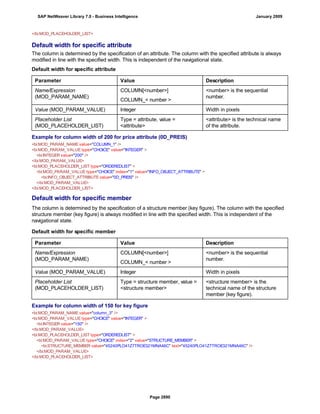
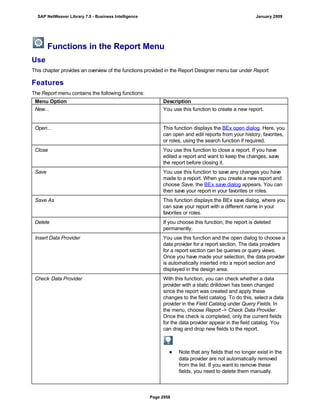
![match TYPE c.
l_input = '6/30/2005'.
l_regex = '([01]?)([0-9])/([0-3]?)([0-9])/([0-9]{4})'.
matcher = cl_abap_matcher=>create( pattern = l_regex
text = l_input ).
match = matcher->match( ).
TRY.
CALL METHOD matcher->get_submatch
EXPORTING
index = 1
RECEIVING
submatch = submatch1.
CATCH cx_sy_matcher.
ENDTRY.
TRY.
CALL METHOD matcher->get_submatch
EXPORTING
index = 3
RECEIVING
submatch = submatch2.
CATCH cx_sy_matcher.
ENDTRY.
IF submatch1 IS INITIAL.
IF submatch2 IS INITIAL.
l_new = '$50$20$4'.
ELSE.
l_new = '$50$2$3$4'.
ENDIF.
ELSE.
IF submatch2 IS INITIAL.
l_new = '$5$1$20$4'.
ELSE.
l_new = '$5$1$2$3$4'.
ENDIF.
ENDIF.
WRITE: / 'Before:', l_input. "6/30/2005
REPLACE
ALL OCCURRENCES OF
REGEX l_regex
IN l_input WITH l_new.
WRITE: / 'After:', l_input. "20050630
SAP NetWeaver Library 7.0 - Business Intelligence January 2009
Page 593](https://image.slidesharecdn.com/sapbi7-141218085854-conversion-gate02/85/SAP-BI-7-0-Info-Providers-596-320.jpg)













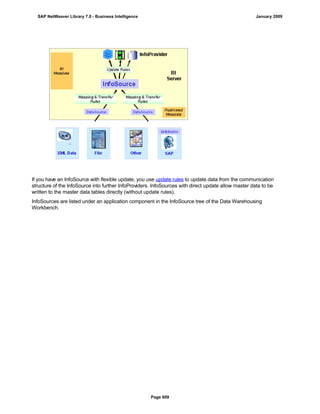





































































































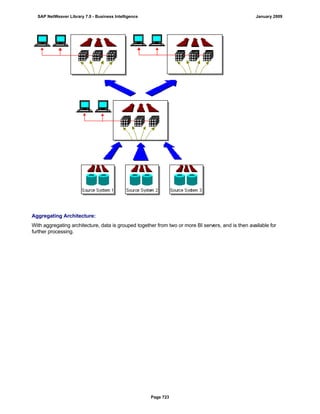
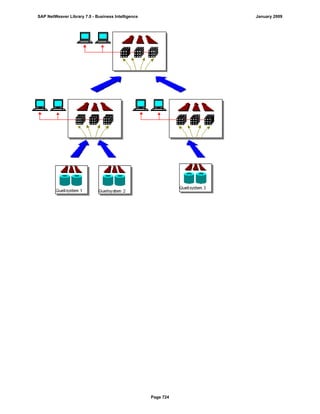












































































































































































































































































































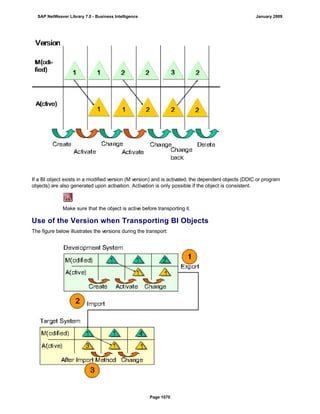



































































































































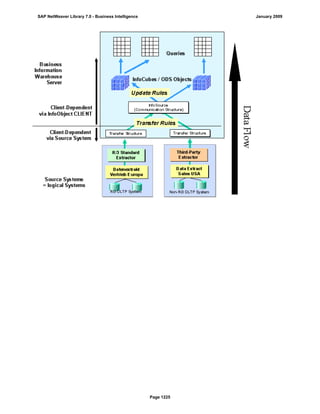





















































































































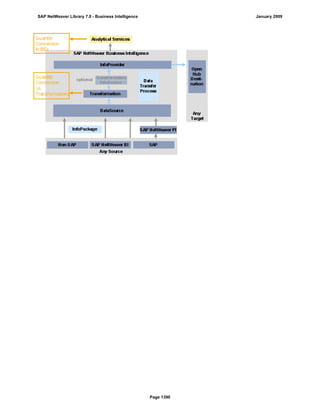

































































































































































































































































































































































































































































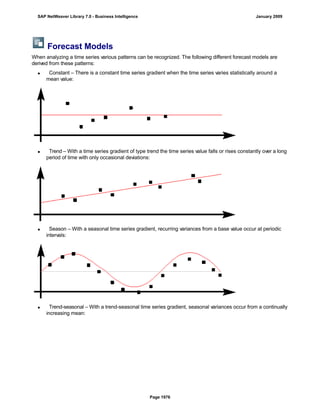
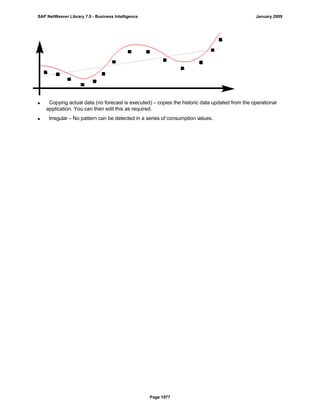
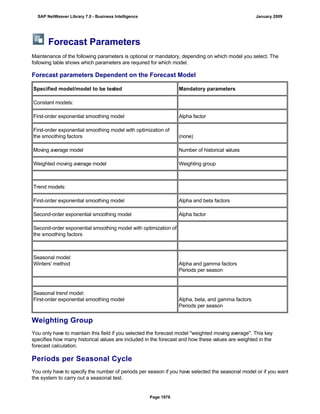
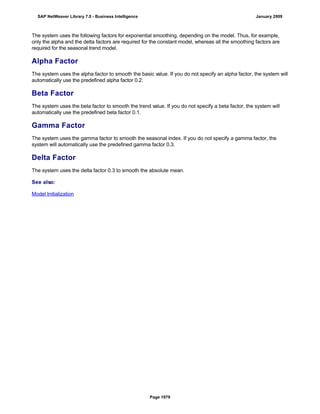

























































































































































































































































































































































































































































































































































































































































































































































































































































































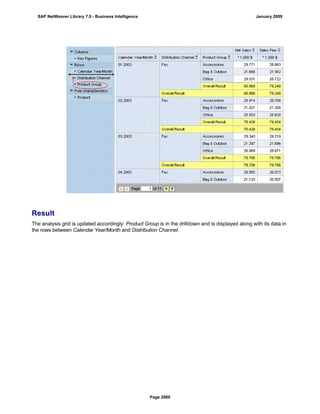
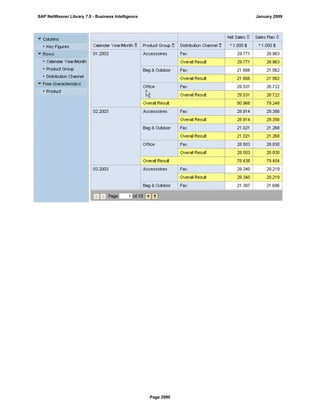
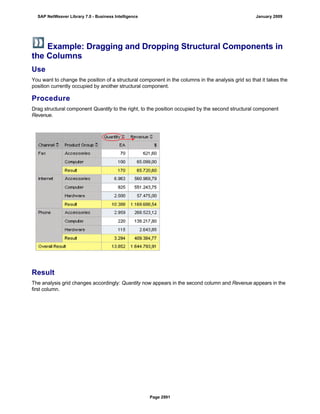
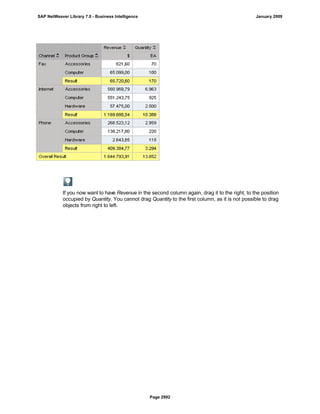
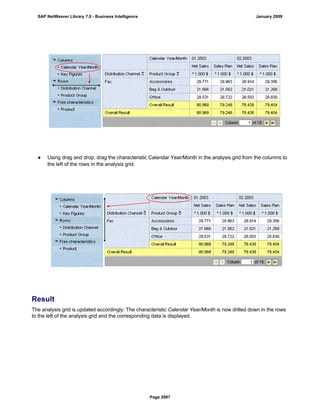
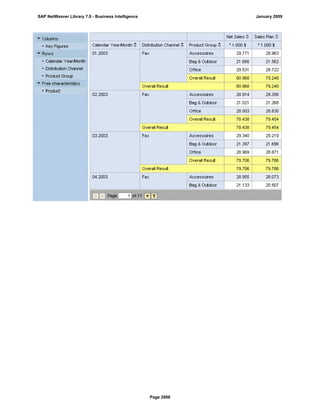

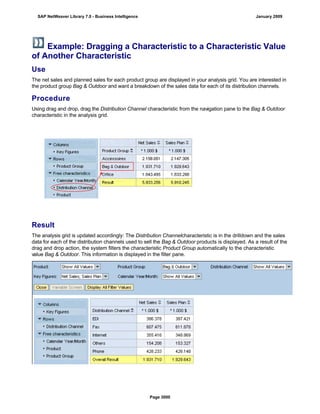
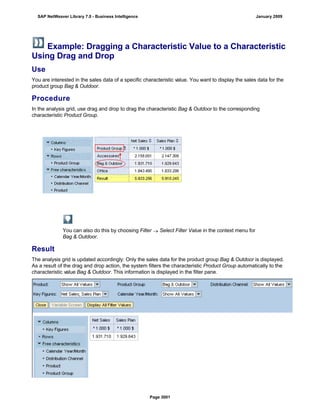
















































































































































































































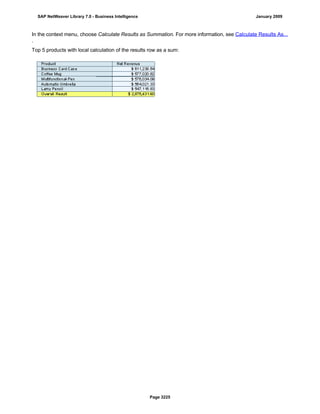


























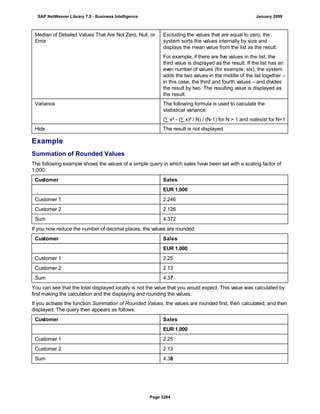
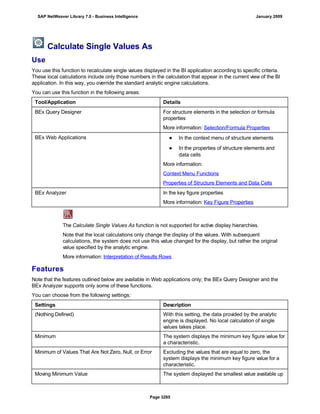
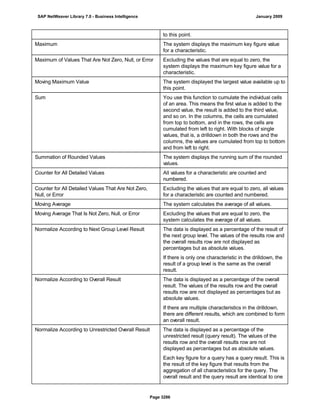

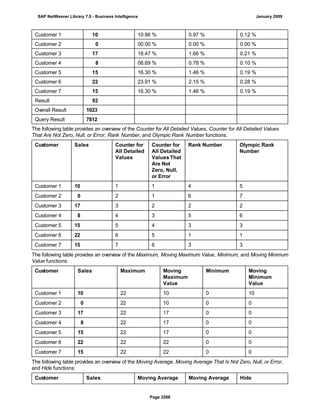



































































































































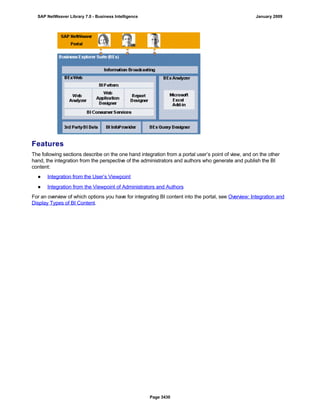
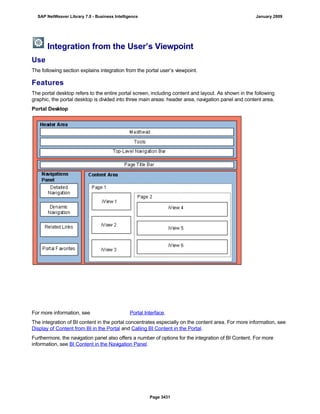
































































































































































































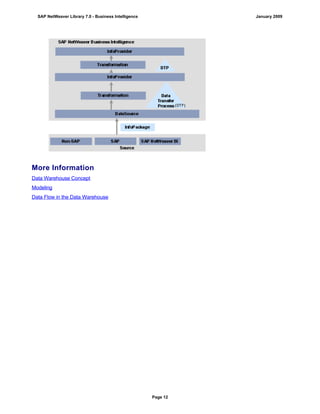
SAP NetWeaver provides Business Intelligence (BI) functionality including data warehousing, a BI platform, and business intelligence tools. BI allows businesses to integrate data from various sources, transform and consolidate it in the data warehouse, and perform flexible reporting, analysis, and planning to support evaluation and interpretation of data for well-founded decision making. Key components of BI include the Data Warehousing Workbench, BI Platform, Business Explorer suite, and additional development technologies like the BI Java SDK.


































































































