Download as PDF, PPTX









![Basics
reitit.core/router to create a router
Matching by path or by name (reverse routing)
Functions to browse the route trees
(defprotocol Router
(router-name [this])
(routes [this])
(compiled-routes [this])
(options [this])
(route-names [this])
(match-by-path [this path])
(match-by-name [this name] [this name path-params]))](https://image.slidesharecdn.com/reitit-190420201046/75/Reitit-Clojure-North-2019-10-2048.jpg)
![(require '[reitit.core :as r])
(def router
(r/router
[["/ping" ::ping]
["/users/:id" ::user]]))
(r/match-by-path router "/ping")
;#Match{:template "/ping"
; :data {:name :user/ping}
; :result nil
; :path-params {}
; :path "/ping"}
(r/match-by-name router ::ping)
;#Match{:template "/ping"
; :data {:name :user/ping}
; :result nil
; :path-params {}
; :path "/ping"}](https://image.slidesharecdn.com/reitit-190420201046/75/Reitit-Clojure-North-2019-11-2048.jpg)
![Route Syntax (~hiccup)
Paths are concatenated, route data meta-merged
(r/router
["/api" {:interceptors [::api]}
["/ping" ::ping]
["/admin" {:roles #{:admin}}
["/users" ::users]
["/db" {:interceptors [::db]
:roles ^:replace #{:db-admin}}]]]))
(r/router
[["/api/ping" {:interceptors [::api]
:name ::ping}]
["/api/admin/users" {:interceptors [::api]
:roles #{:admin}
:name ::users}]
["/api/admin/db" {:interceptors [::api ::db]
:roles #{:db-admin}}]])](https://image.slidesharecdn.com/reitit-190420201046/75/Reitit-Clojure-North-2019-12-2048.jpg)
![Programming routes
nil s and nested sequences are flattened
(defn router [dev?]
(r/router
[["/command/"
(for [mutation [:olipa :kerran :avaruus]]
[(name mutation) mutation])]
(if dev? ["/dev-tools" :dev-tools])]))
(-> (router true) (r/routes))
;[["/command/olipa" {:name :olipa}]
; ["/command/kerran" {:name :kerran}]
; ["/command/avaruus" {:name :avaruus}]
; ["/dev-tools" {:name :dev-tools}]]](https://image.slidesharecdn.com/reitit-190420201046/75/Reitit-Clojure-North-2019-13-2048.jpg)
![Composing routes
It's just data, merge trees
Single route tree allows to optimize the whole
Merging & nesting routers
Empty route fragments, e.g. :<> in Reagent
(-> (r/router
[["" {:interceptors [::cors]}
["/api" ::api]
["/ipa" ::ipa]]
["/ping" ::ping]])
(r/routes))
;[["/api" {:interceptors [::cors], :name ::api}]
; ["/ipa" {:interceptors [::cors], :name ::ipa}]
; ["/ping" {:name ::ping}]]](https://image.slidesharecdn.com/reitit-190420201046/75/Reitit-Clojure-North-2019-14-2048.jpg)
![Route Conflict Resolution
Multiple sources (code/EDN/DB) for routes?
Are all routes still reachable?
Reitit fails-fast by default on path & name conflicts
(require '[reitit.core :as r])
(require '[reitit.dev.pretty :as pretty])
(r/router
[["/ping"]
["/:user-id/orders"]
["/bulk/:bulk-id"]
["/public/*path"]
["/:version/status"]]
{:exception pretty/exception})](https://image.slidesharecdn.com/reitit-190420201046/75/Reitit-Clojure-North-2019-15-2048.jpg)
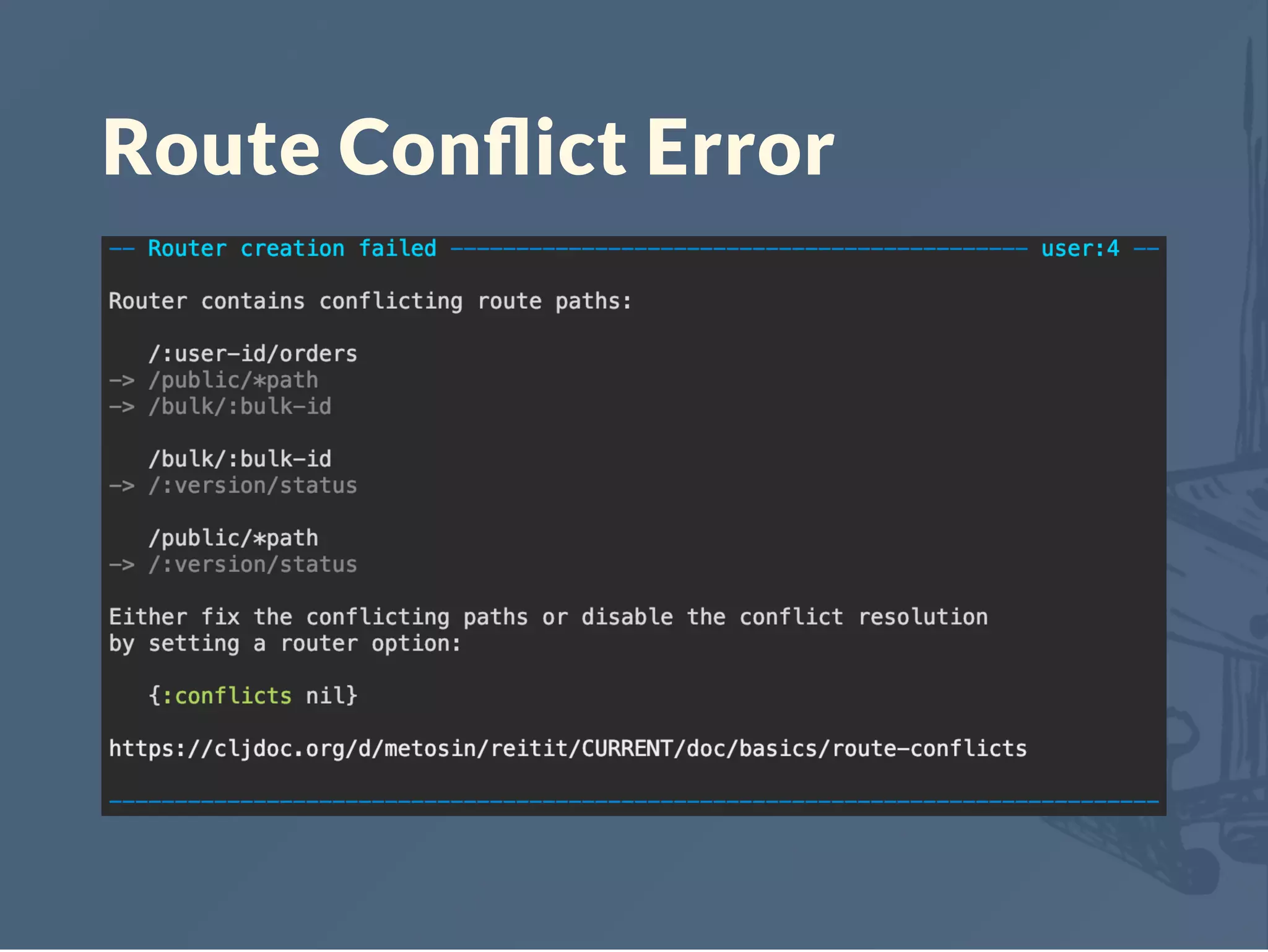

![What is in the route data?
Can be anything, the Router doesn't care.
Returned on successful Match
Can be queried from a Router
Build your own interpreters for the data
A Route First Architecture: Match -> Data -> React
(r/match-by-path router "/api/admin/db")
;#Match{:template "/api/admin/db",
; :data {:interceptors [::api ::db]
; :roles #{:db-admin}},
; :result nil,
; :path-params {},
; :path "/api/admin/db"}](https://image.slidesharecdn.com/reitit-190420201046/75/Reitit-Clojure-North-2019-18-2048.jpg)

![Frontend Example
https://router.vuejs.org/guide/essentials/nested-routes.html
(require '[reitit.frontend :as rf])
(require '[reitit.frontend.easy :as rfe])
(defn frontpage-view [match] ...)
(defn topics-view [match] ... (rf/nested-view match)
(defn topic-view [match] ...)
(def router
(rf/router
[["/" {:name :frontpage
:views [frontpage-view]}]
["/topics"
{:controllers [load-topics]
:views [topics-view]}
["" {:name :topics}]
["/:id"
{:name :topic
:parameters {:path {:id int?}}
:controllers [load-topic]
:views [topic-view]}]]]))
(rfe/start! router ...)](https://image.slidesharecdn.com/reitit-190420201046/75/Reitit-Clojure-North-2019-20-2048.jpg)

![Invalid Route Data Example
(require '[reitit.spec :as spec])
(require '[clojure.spec.alpha :as s])
(s/def ::role #{:admin :user})
(s/def ::roles (s/coll-of ::role :into #{}))
(r/router
["/api/admin" {::roles #{:adminz}}]
{:validate spec/validate
:exception pretty/exception})](https://image.slidesharecdn.com/reitit-190420201046/75/Reitit-Clojure-North-2019-22-2048.jpg)
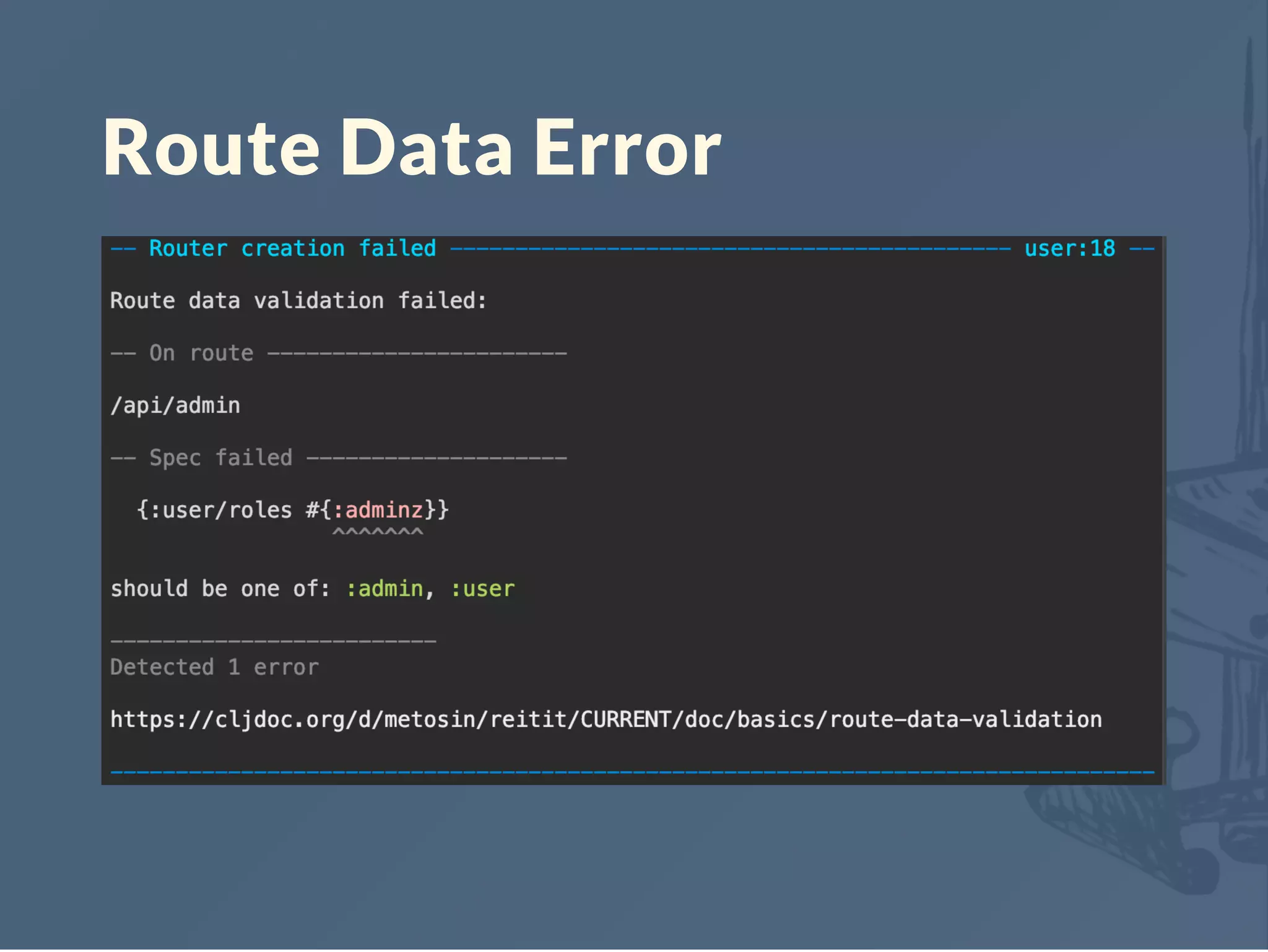


![Coercion (Déjà-vu)
Coercion is a process of transforming values between
domain (e.g. JSON->EDN, String->EDN)
Route data keys :parameters & :coercion
Utilities to apply coercion in reitit.coercion
Implementation for Schema & clojure.spec <-- !!!
(defprotocol Coercion
"Pluggable coercion protocol"
(-get-name [this])
(-get-options [this])
(-get-apidocs [this specification data])
(-compile-model [this model name])
(-open-model [this model])
(-encode-error [this error])
(-request-coercer [this type model])
(-response-coercer [this model]))](https://image.slidesharecdn.com/reitit-190420201046/75/Reitit-Clojure-North-2019-26-2048.jpg)




![Ring Application
(require '[reitit.ring :as ring])
(def app
(ring/ring-handler
(ring/router
["/api" {:middleware [wrap-api wrap-roles]}
["/ping" {:get ping-handler]}
["/users" {:middleware [db-middleware]
:roles #{:admin} ;; who reads this?
:get get-users
:post add-user}]])
(ring/create-default-handler)))
(app {:uri "/api/ping" :request-method :get})
; {:status 200, :body "pong"}](https://image.slidesharecdn.com/reitit-190420201046/75/Reitit-Clojure-North-2019-31-2048.jpg)
![Accessing route data
Match and Router are injected into the request
Components can read these at request time and
do what ever they want, "Ad-hoc extensions"
Pattern used in Kekkonen and in Yada
(defn wrap-roles [handler]
;; roles injected via session-middleware
(fn [{:keys [roles] :as request}]
;; read the route-data at request-time
(let [required (-> request (ring/get-match) :data :roles)]
(if (and (seq required)
(not (set/subset? required roles)))
{:status 403, :body "forbidden"}
(handler request)))))](https://image.slidesharecdn.com/reitit-190420201046/75/Reitit-Clojure-North-2019-32-2048.jpg)
![Middleware as data
Ring middleware are opaque functions
Reitit adds a first class values, Middleware records
Recursive IntoMiddleware protocol to expand to
Attach documentation, specs, requirements, ...
Can be used in place of middleware functions
Zero runtime penalty
(defn roles-middleware []
{:name ::roles-middleware
:description "Middleware to enforce roles"
:requires #{::session-middleware}
:spec (s/keys :opt-un [::roles])
:wrap wrap-roles})](https://image.slidesharecdn.com/reitit-190420201046/75/Reitit-Clojure-North-2019-33-2048.jpg)
![Compiling middleware
Each middleware knows the endpoint it's mounted to
We can pass the route data in at router creation time
Big win for optimizing chains
(def roles-middleware
{:name ::roles-middleware
:description "Middleware to enforce roles"
:requires #{::session-middleware}
:spec (s/keys :opt-un [::roles])
:compile (fn [{required :roles} _]
;; unmount if there are no roles required
(if (seq required)
(fn [handler]
(fn [{:keys [roles] :as request}]
(if (not (set/subset? required roles))
{:status 403, :body "forbidden"}
(handler request))))))})](https://image.slidesharecdn.com/reitit-190420201046/75/Reitit-Clojure-North-2019-34-2048.jpg)
![Partial Specs Example
"All routes under /account should require a role"
;; look ma, not part of request processing!
(def roles-defined
{:name ::roles-defined
:description "requires a ::role for the routes"
:spec (s/keys :req-un [::roles])})
["/api" {:middleware [roles-middleware]} ;; behavior
["/ping"] ;; unmounted
["/account" {:middleware [roles-defined]} ;; :roles mandatory
["/admin" {:roles #{:admin}}] ;; ok
["/user" {:roles #{:user}}] ;; ok
["/manager"]]] ;; fail!](https://image.slidesharecdn.com/reitit-190420201046/75/Reitit-Clojure-North-2019-35-2048.jpg)

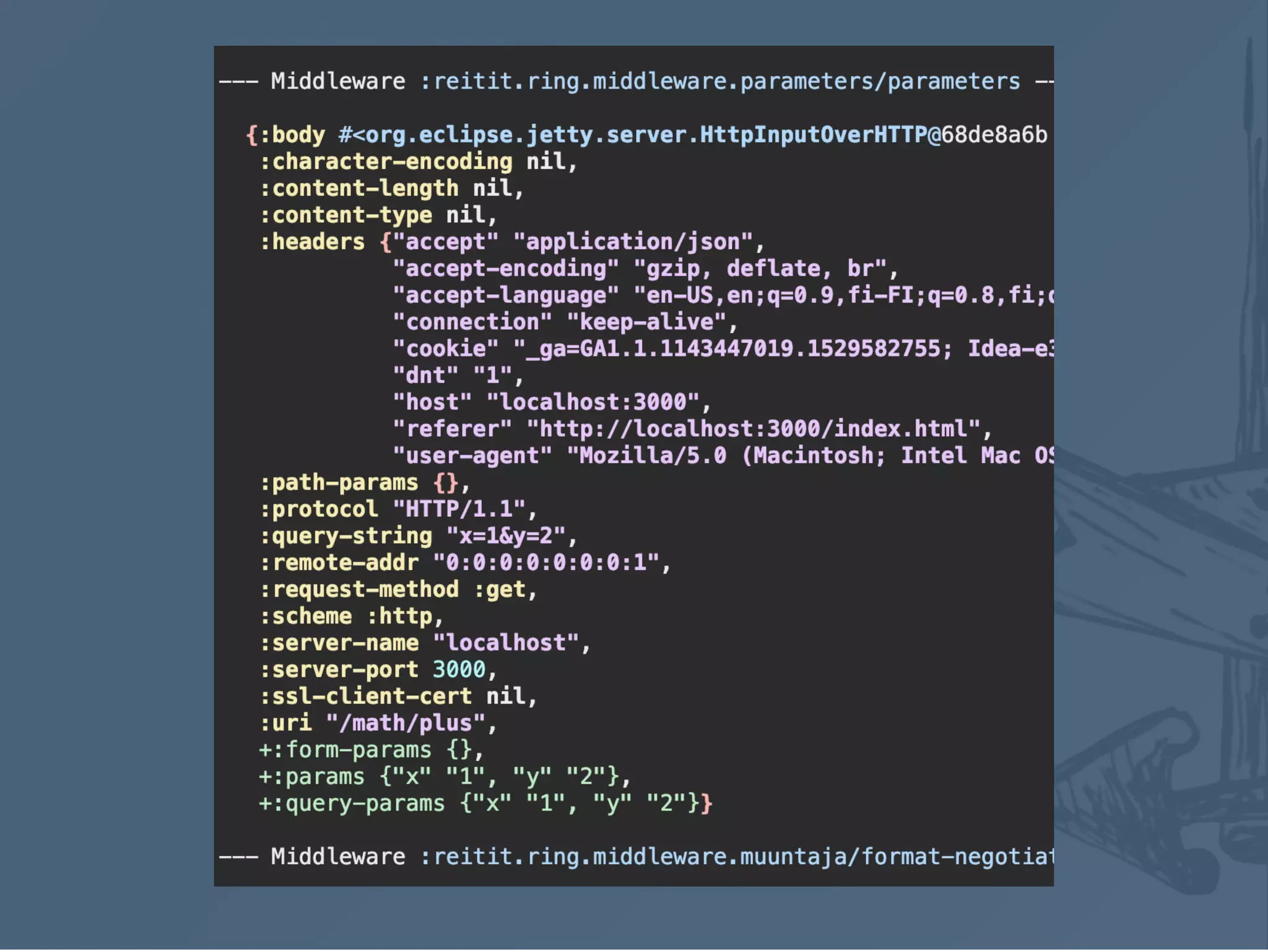
![Data definitions (as data)
The core coercion for all (OpenAPI) paramerer &
response types ( :query , :body , header , :path etc)
Separerate Middleware to apply request & response
coercion and format coercion errors
Separate modules, spec coercion via spec-tools
["/plus/:y"
{:get {:parameters {:query {:x int?},
:path {:y int?}}
:responses {200 {:body {:total pos-int?}}}
:handler (fn [{:keys [parameters]}]
;; parameters are coerced
(let [x (-> parameters :query :x)
y (-> parameters :path :y)]
{:status 200
:body {:total (+ x y)}}))}}]](https://image.slidesharecdn.com/reitit-190420201046/75/Reitit-Clojure-North-2019-38-2048.jpg)



![Http Application
(require '[reitit.http :as http])
(require '[reitit.interceptor.sieppari :as sieppari]
(def app
(http/ring-handler
(http/router
["/api" {:interceptors [api-interceptor
roles-interceptor]}
["/ping" ping-handler]
["/users" {:interceptors [db-interceptor]
:roles #{:admin}
:get get-users
:post add-user}]])
(ring/create-default-handler)
{:executor sieppari/executor}))
(app {:uri "/api/ping" :request-method :get})
; {:status 200, :body "pong"}](https://image.slidesharecdn.com/reitit-190420201046/75/Reitit-Clojure-North-2019-42-2048.jpg)
![Example Interceptor
(defn coerce-request-interceptor
"Interceptor for pluggable request coercion.
Expects a :coercion of type `reitit.coercion/Coercion`
and :parameters from route data, otherwise does not mount."
[]
{:name ::coerce-request
:spec ::rs/parameters
:compile (fn [{:keys [coercion parameters]} opts]
(cond
;; no coercion, skip
(not coercion) nil
;; just coercion, don't mount
(not parameters) {}
;; mount
:else
(let [coercers (coercion/request-coercers coercion parameters opts)]
{:enter (fn [ctx]
(let [request (:request ctx)
coerced (coercion/coerce-request coercers request)
request (impl/fast-assoc request :parameters coerced)]
(assoc ctx :request request)))})))})](https://image.slidesharecdn.com/reitit-190420201046/75/Reitit-Clojure-North-2019-43-2048.jpg)



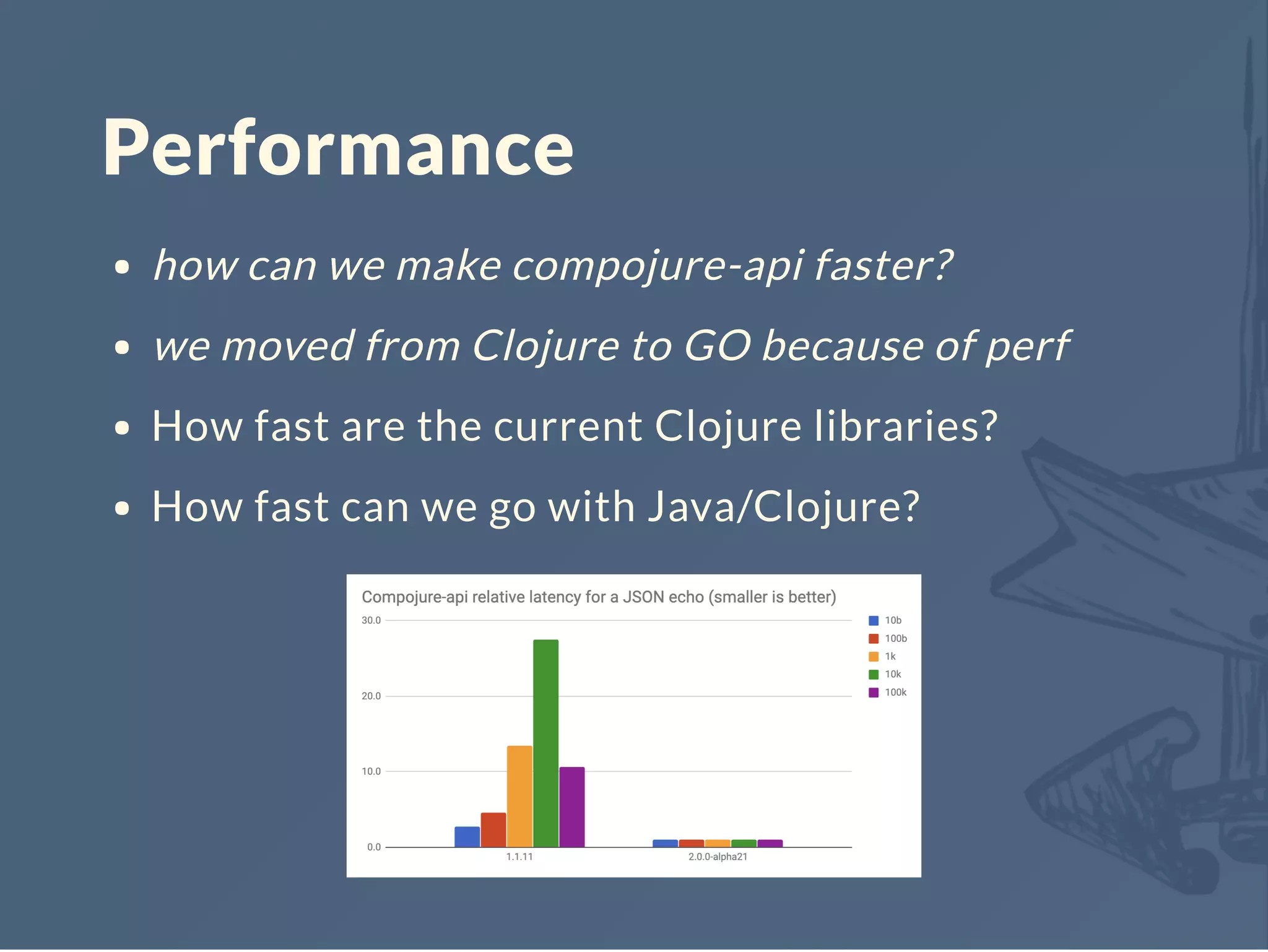

![(def defaults {:keywords? true})
(time
(dotimes [_ 10000]
(merge defaults {})))
; "Elapsed time: 4.413803 msecs"
(require '[criterium.core :as cc])
(cc/quick-bench
(merge defaults {}))
; Evaluation count : 2691372 in 6 samples of 448562 calls.
; Execution time mean : 230.346208 ns
; Execution time std-deviation : 10.355077 ns
; Execution time lower quantile : 221.101397 ns ( 2.5%)
; Execution time upper quantile : 245.331388 ns (97.5%)
; Overhead used : 1.881561 ns](https://image.slidesharecdn.com/reitit-190420201046/75/Reitit-Clojure-North-2019-49-2048.jpg)
![(require '[clj-async-profiler.core :as prof])
(prof/serve-files 8080) ;; serve the svgs here
(prof/profile
(dotimes [_ 40000000] ;; ~10sec period
(merge defaults {})))](https://image.slidesharecdn.com/reitit-190420201046/75/Reitit-Clojure-North-2019-50-2048.jpg)


![(require '[reitit.trie :as trie])
(-> [["/v2/whoami" 1]
["/v2/users/:user-id/datasets" 2]
["/v2/public/projects/:project-id/datasets" 3]
["/v1/public/topics/:topic" 4]
["/v1/users/:user-id/orgs/:org-id" 5]
["/v1/search/topics/:term" 6]
["/v1/users/:user-id/invitations" 7]
["/v1/users/:user-id/topics" 9]
["/v1/users/:user-id/bookmarks/followers" 10]
["/v2/datasets/:dataset-id" 11]
["/v1/orgs/:org-id/usage-stats" 12]
["/v1/orgs/:org-id/devices/:client-id" 13]
["/v1/messages/user/:user-id" 14]
["/v1/users/:user-id/devices" 15]
["/v1/public/users/:user-id" 16]
["/v1/orgs/:org-id/errors" 17]
["/v1/public/orgs/:org-id" 18]
["/v1/orgs/:org-id/invitations" 19]
["/v1/users/:user-id/device-errors" 22]]
(trie/insert)
(trie/compile)
(trie/pretty))](https://image.slidesharecdn.com/reitit-190420201046/75/Reitit-Clojure-North-2019-54-2048.jpg)
![["/v"
[["1/"
[["users/" [:user-id ["/" [["device" [["-errors" 22]
["s" 15]]]
["orgs/" [:org-id 5]]
["bookmarks/followers" 10]
["invitations" 7]
["topics" 9]]]]]
["orgs/" [:org-id ["/" [["devices/" [:client-id 13]]
["usage-stats" 12]
["invitations" 19]
["errors" 17]]]]]
["public/" [["topics/" [:topic 4]]
["users/" [:user-id 16]]
["orgs/" [:org-id 18]]]]
["search/topics/" [:term 6]]
["messages/user/" [:user-id 14]]]]
["2/"
[["public/projects/" [:project-id ["/datasets" 3]]]
["users/" [:user-id ["/datasets" 2]]]
["datasets/" [:dataset-id 11]]
["whoami" 1]]]]]](https://image.slidesharecdn.com/reitit-190420201046/75/Reitit-Clojure-North-2019-55-2048.jpg)

![Initial Segment Trie
(defn- segment
([] (segment {} #{} nil nil))
([children wilds catch-all match]
(let [children' (impl/fast-map children)
wilds? (seq wilds)]
^{:type ::segment}
(reify
Segment
(-insert [_ [p & ps] d]
(if-not p
(segment children wilds catch-all d)
(let [[w c] ((juxt impl/wild-param impl/catch-all-param) p)
wilds (if w (conj wilds w) wilds)
catch-all (or c catch-all)
children (update children (or w c p) #(-insert (or % (segment)) ps d))]
(segment children wilds catch-all match))))
(-lookup [_ [p & ps] path-params]
(if (nil? p)
(when match (assoc match :path-params path-params))
(or (-lookup (impl/fast-get children' p) ps path-params)
(if (and wilds? (not (str/blank? p))) (some #(-lookup (impl/fast-get children' %) ps
(if catch-all (-catch-all children' catch-all path-params p ps)))))))))](https://image.slidesharecdn.com/reitit-190420201046/75/Reitit-Clojure-North-2019-57-2048.jpg)

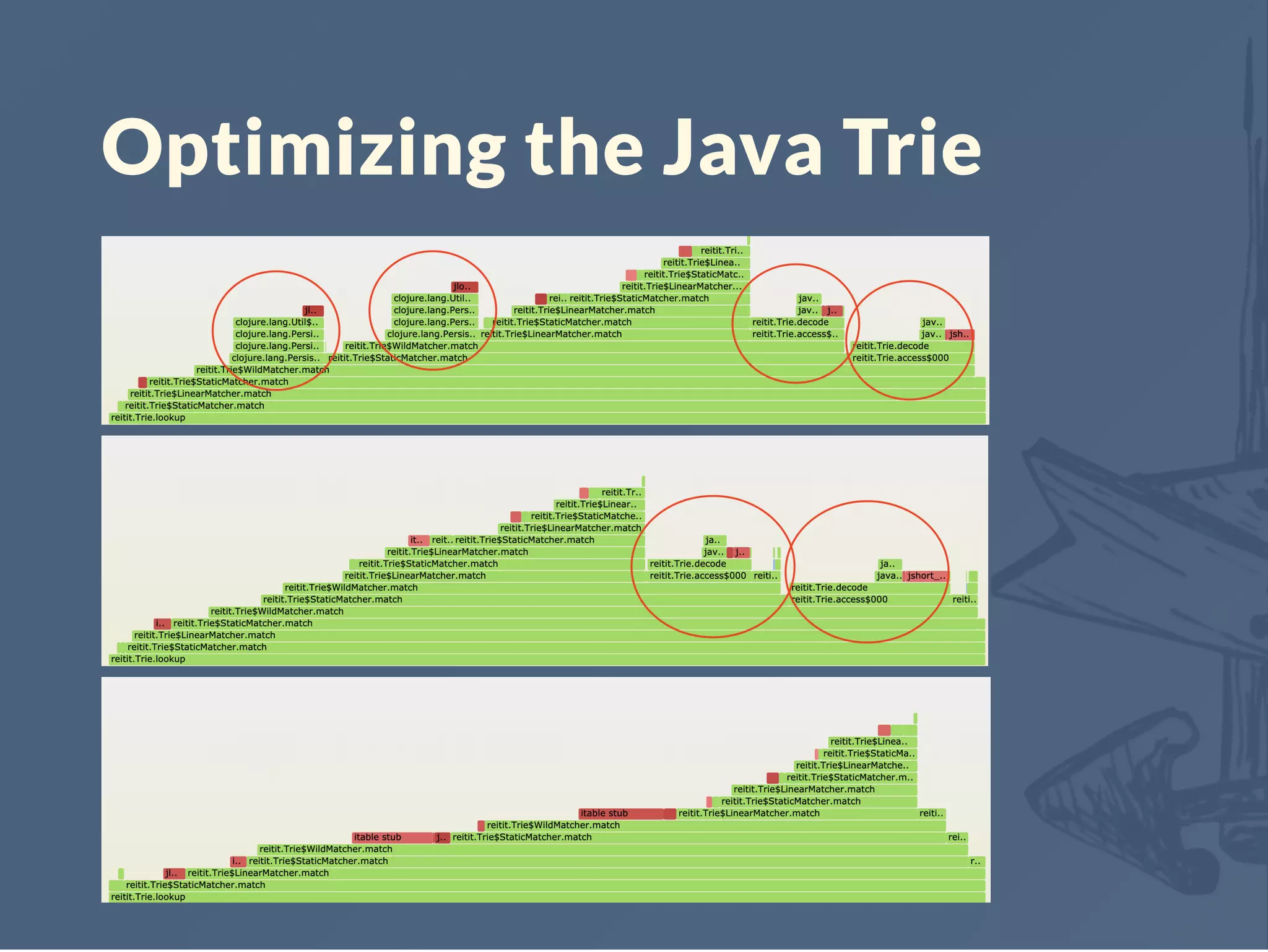
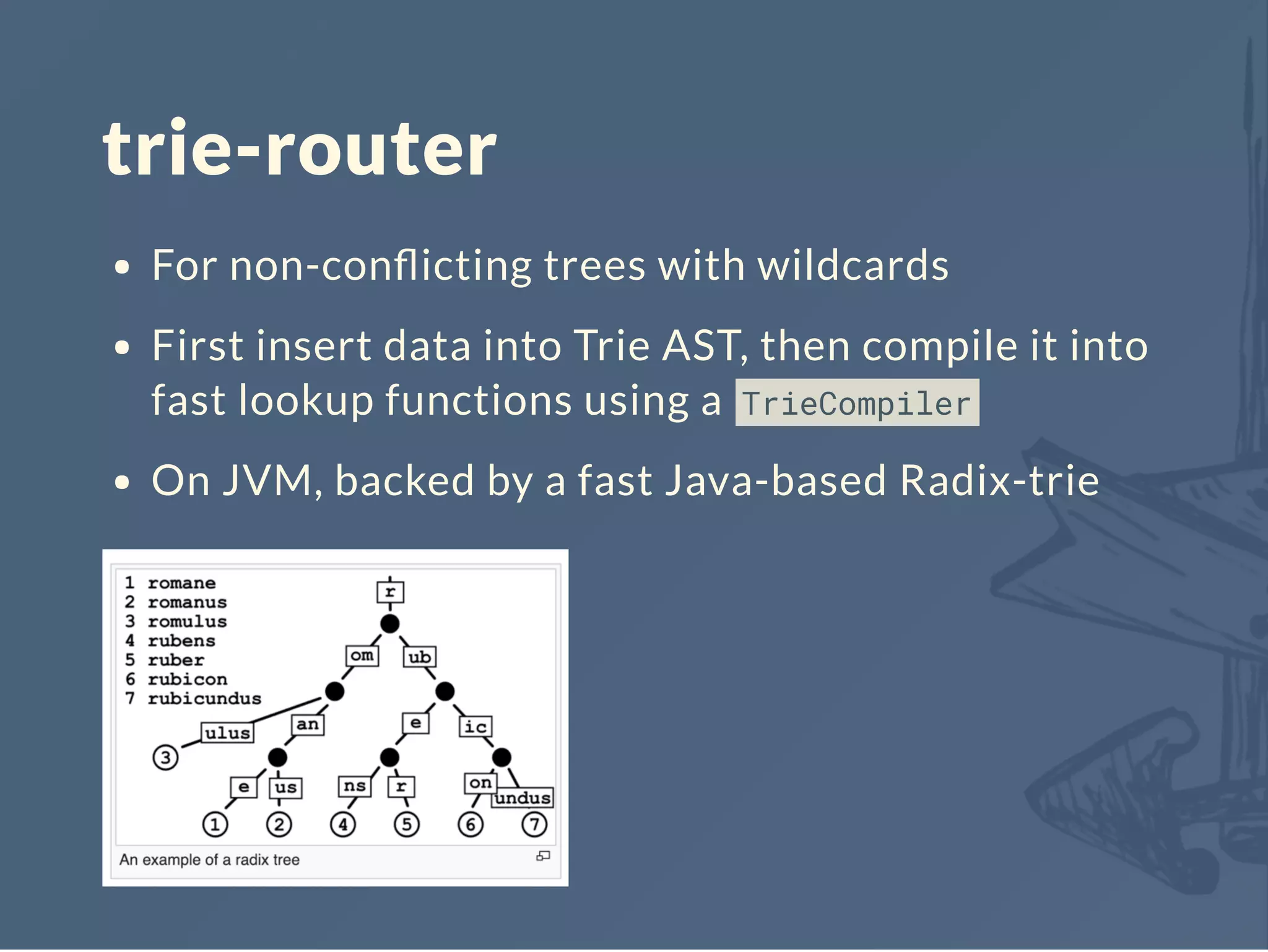
![Java Trie
Set of matchers defined by the TrieCompiler
Order of magnitude faster than the original impl
@Override
public Match match(int i, int max, char[] path) {
boolean hasPercent = false;
boolean hasPlus = false;
if (i < max && path[i] != end) {
int stop = max;
for (int j = i; j < max; j++) {
final char c = path[j];
hasPercent = hasPercent || c == '%';
hasPlus = hasPlus || c == '+';
if (c == end) {
stop = j;
break;
}
}
final Match m = child.match(stop, max, path);
if (m != null) {
m.params = m.params.assoc(key, decode(new String(path, i, stop - i), hasPercent, hasPlus));
}
return m;
}
return null;
}](https://image.slidesharecdn.com/reitit-190420201046/75/Reitit-Clojure-North-2019-60-2048.jpg)















The document provides an overview of Reitit, a routing library and framework for Clojure and ClojureScript, focusing on its performance, routing capabilities, and middleware integration. It discusses features like data-driven routing, access control through roles, and tools for performance measurement. Additionally, it outlines examples of router configuration, interceptor usage, and the benefits of separating routing from dispatching for improved optimization and correctness.




































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)













