Download to read offline













![Import using Flume
1. FileSystem fs = FileSystem.get(URI.create(uriPath), conf);
2. Configuration conf = fs.getConf();
3. FileStatus[] status = fs.listStatus(new Path(dirPath));
4. SequenceFile.Reader.Option opt = SequenceFile.Reader.file(status[i].getPath());
5. for (int i = 0; i < status.length; i++) {
6. SequenceFile.Reader reader = new SequenceFile.Reader(conf, opt);
7. Writable key = (Writable) ReflectionUtils.newInstance(
reader.getKeyClass(), conf);
8. Writable value = (Writable) ReflectionUtils.newInstance(
reader.getValueClass(), conf);
9. while (reader.next(key, value)) {
10. Map<String, Object> parsedEvent = parseEvent(key.toString(),
value.toString());
11. if (parsedEvent != null) {
12. eventQueue.add(parsedEvent);
}
}
}
18](https://image.slidesharecdn.com/realtimestream-fastcatsearch-censored-141121044409-conversion-gate02/75/Realtimestream-and-realtime-fastcatsearch-18-2048.jpg)




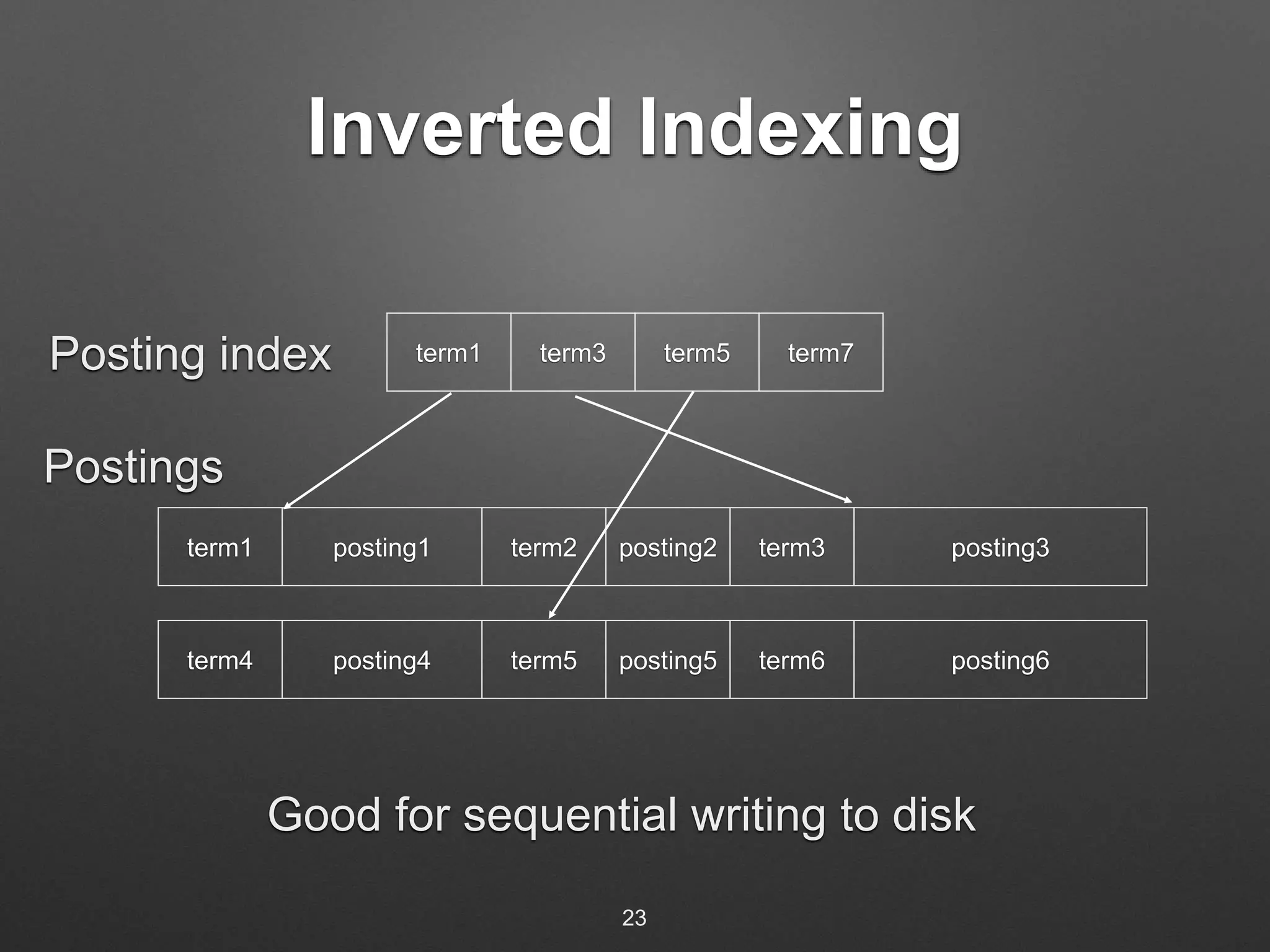
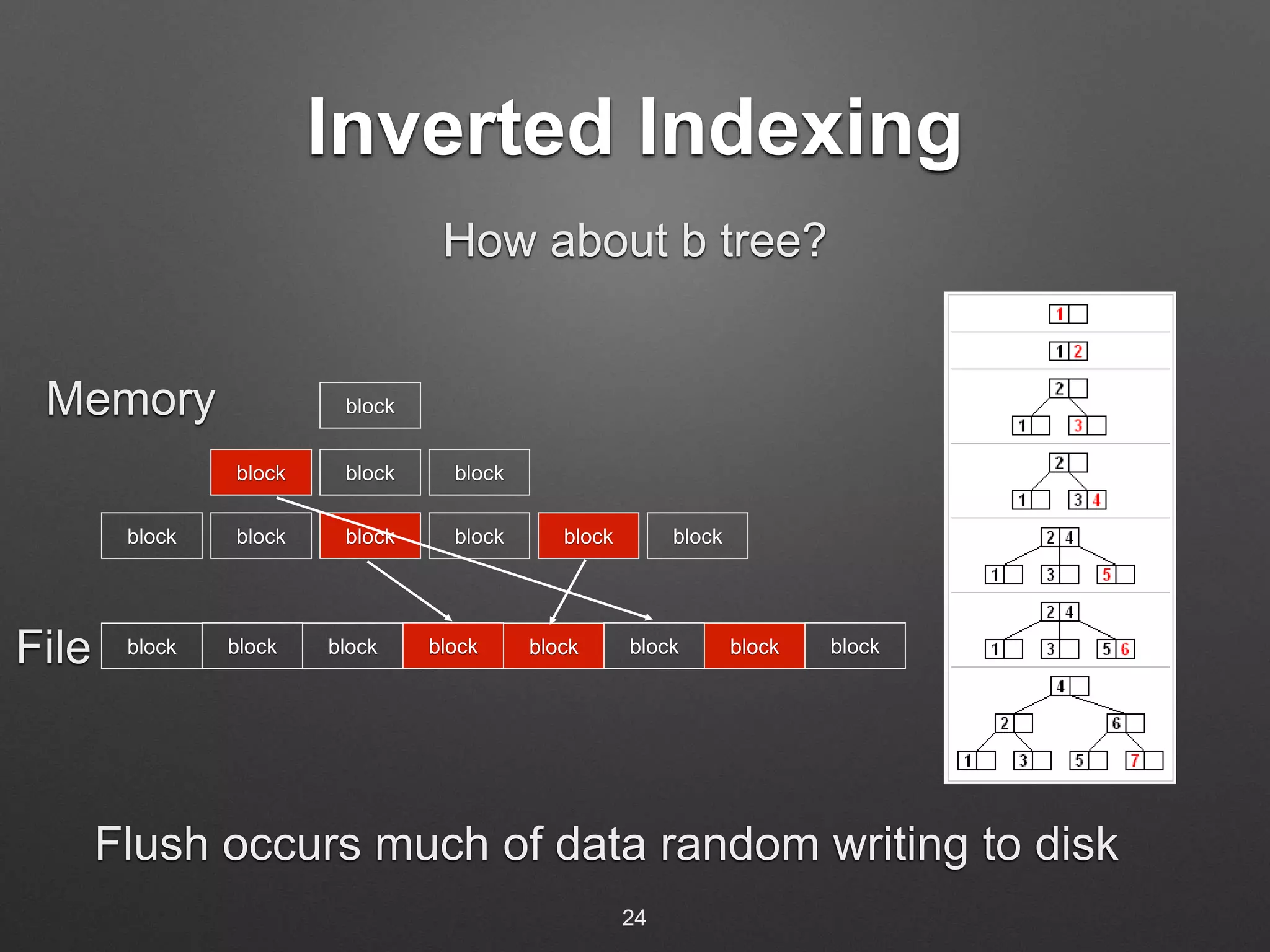




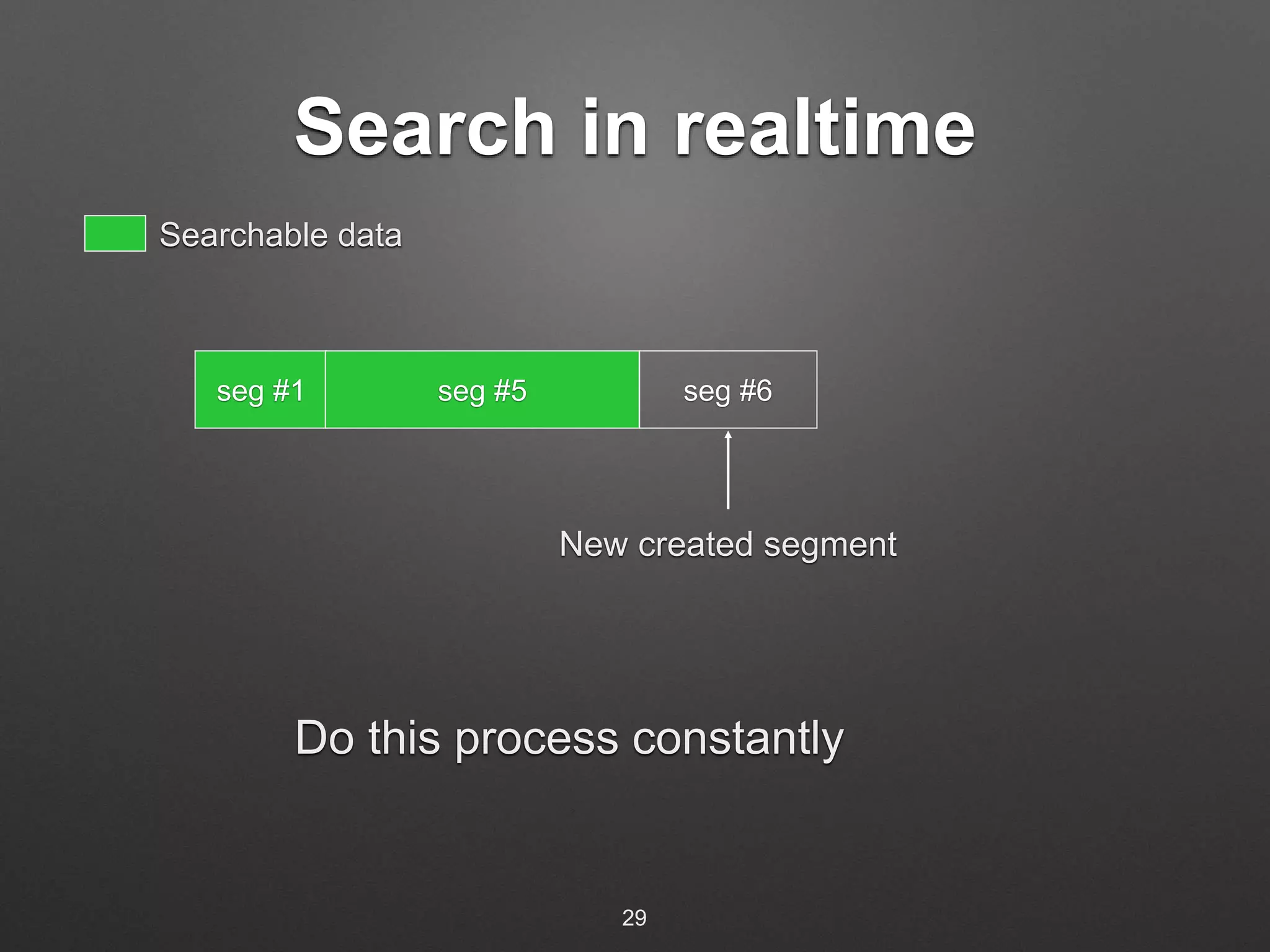


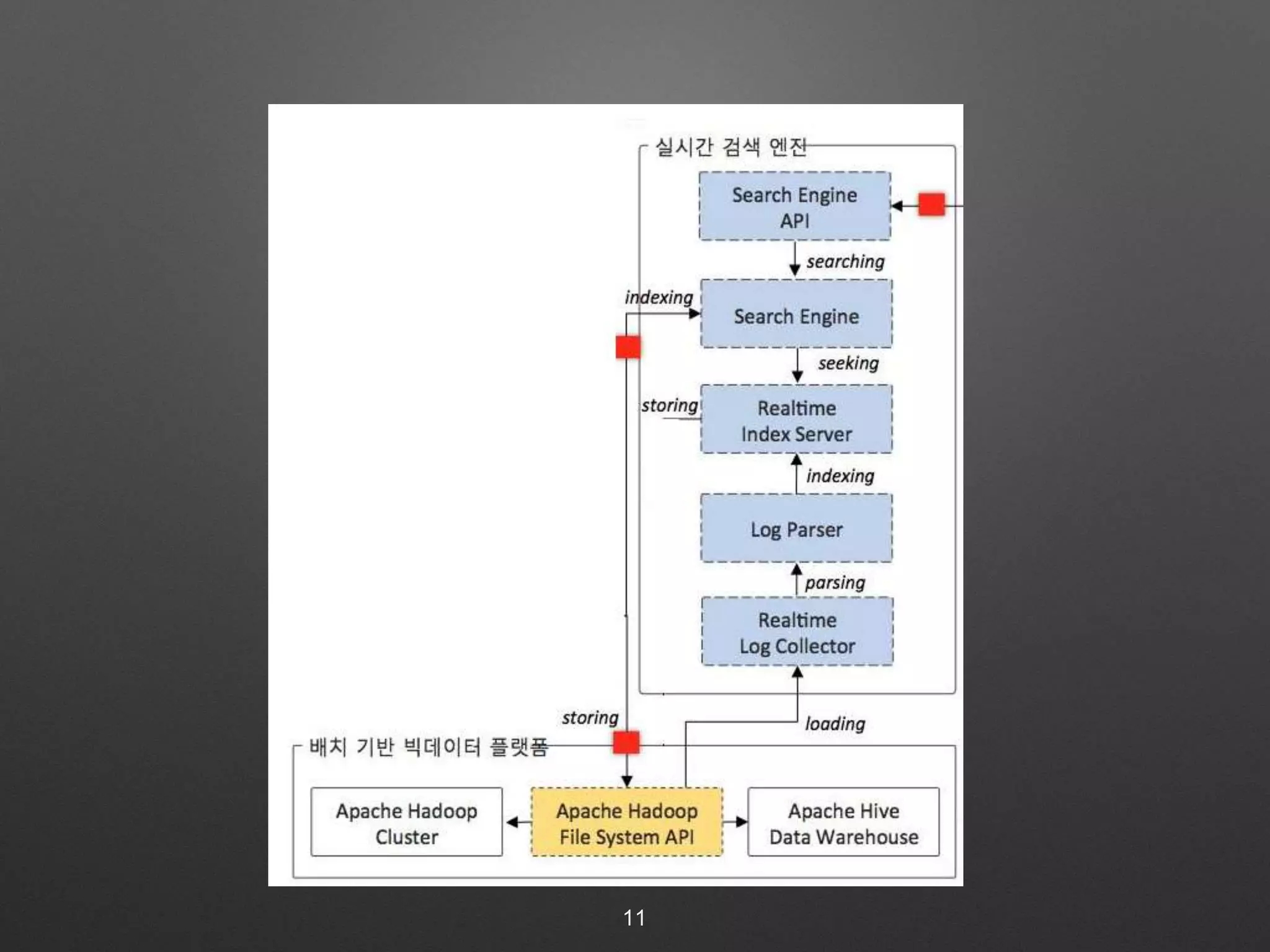
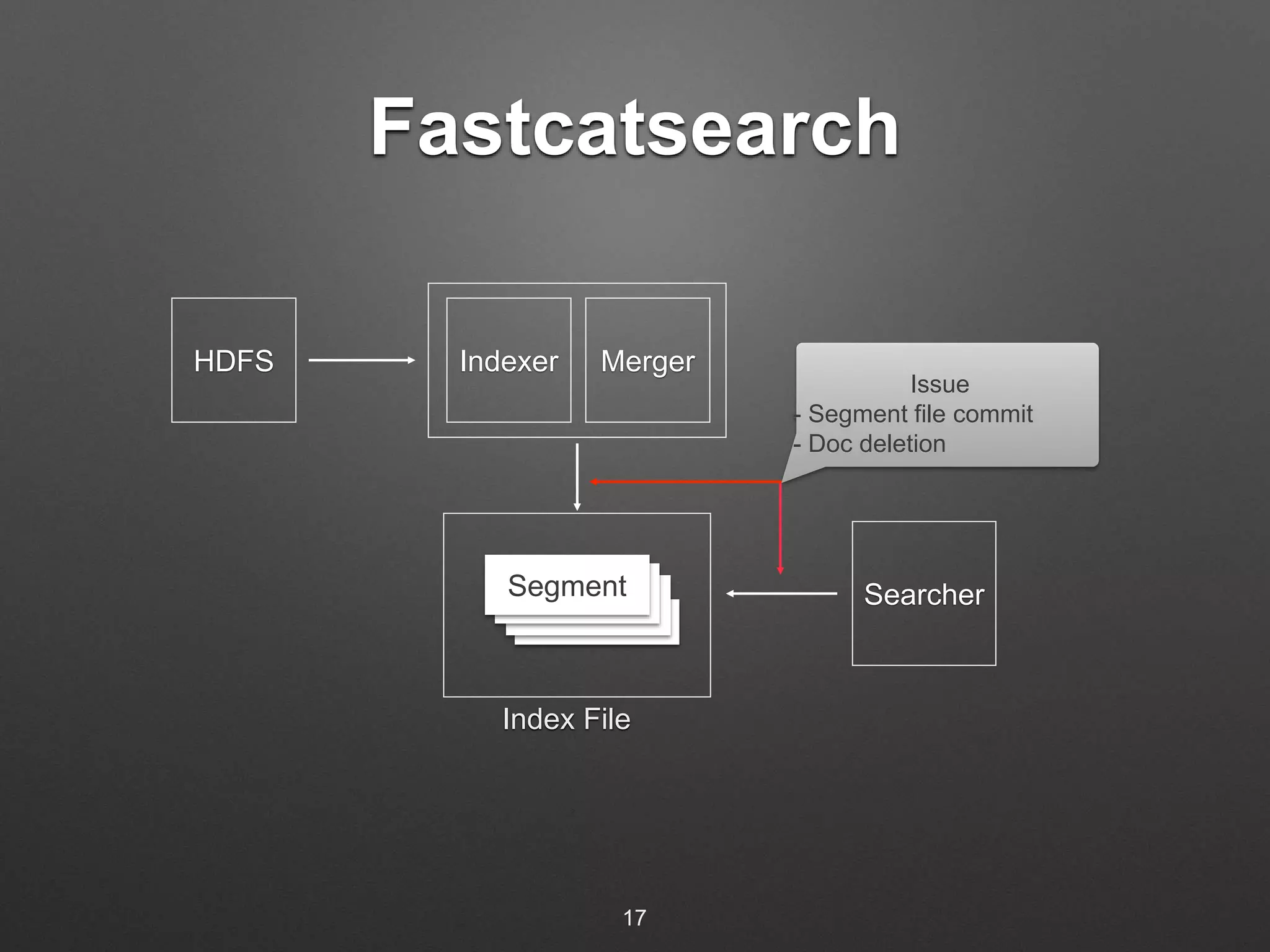
The document discusses building a real-time search engine for log data. It describes using Flume to collect streaming log data and write it to HDFS files. Fastcatsearch indexes the HDFS files in real-time by creating index segments, merging segments, and removing outdated segments to make data searchable in real-time. The system aims to provide fast indexing and querying of large and continuous log data streams like Splunk.

































![[D2 CAMPUS] 2016 한양대학교 프로그래밍 경시대회 문제풀이](https://cdn.slidesharecdn.com/ss_thumbnails/random-161228045003-thumbnail.jpg?width=640&height=640&fit=bounds)


































