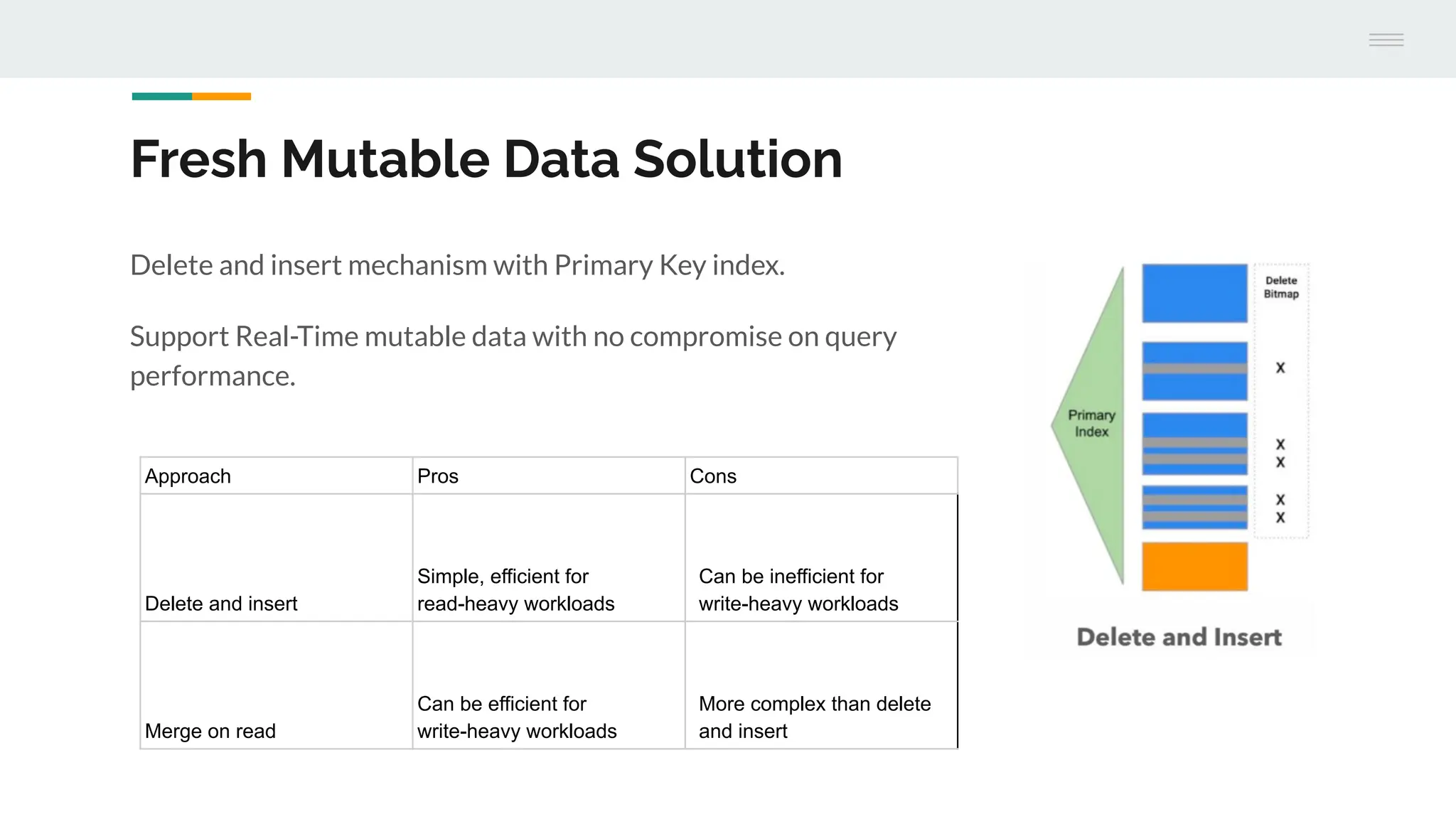
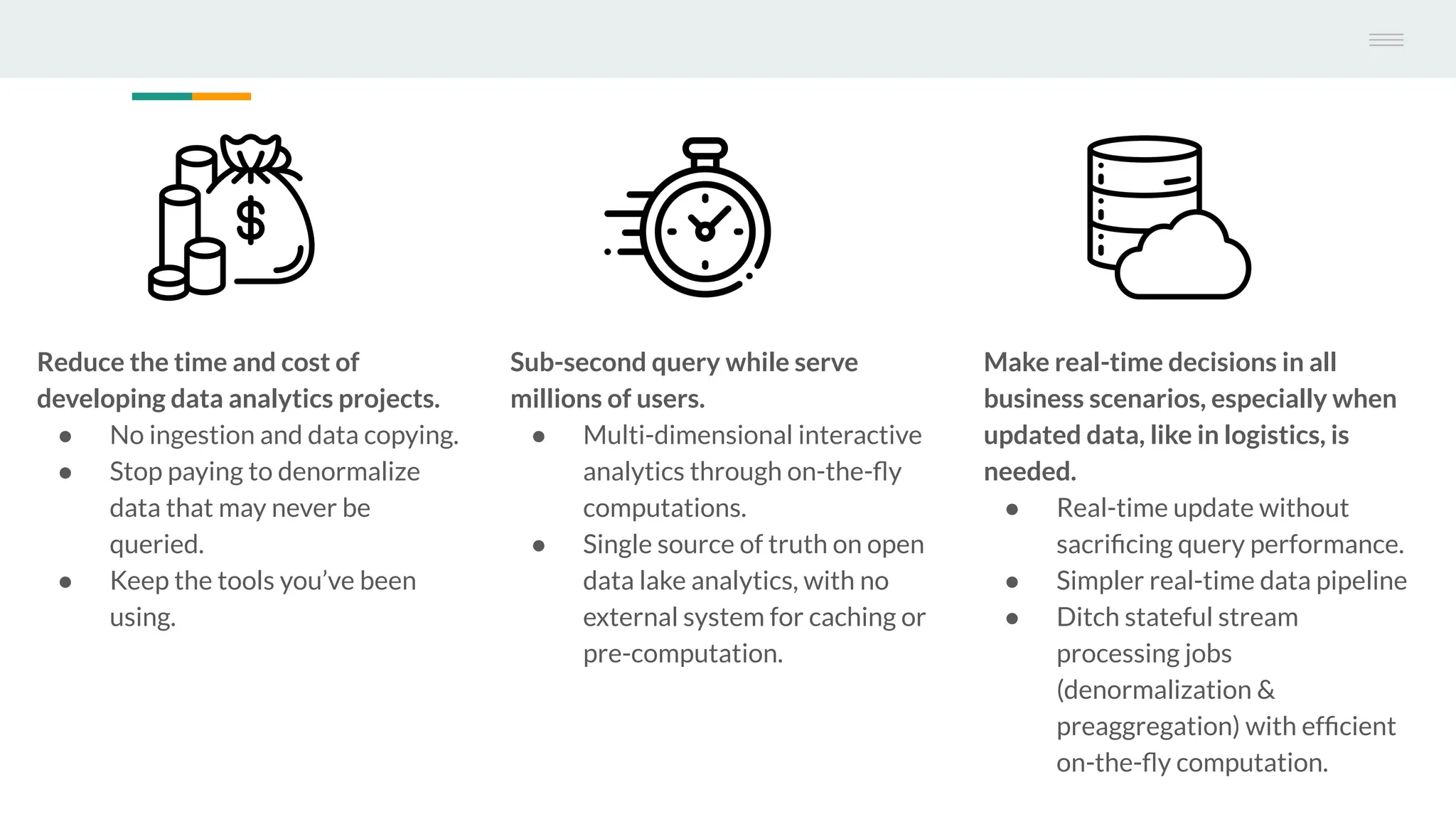
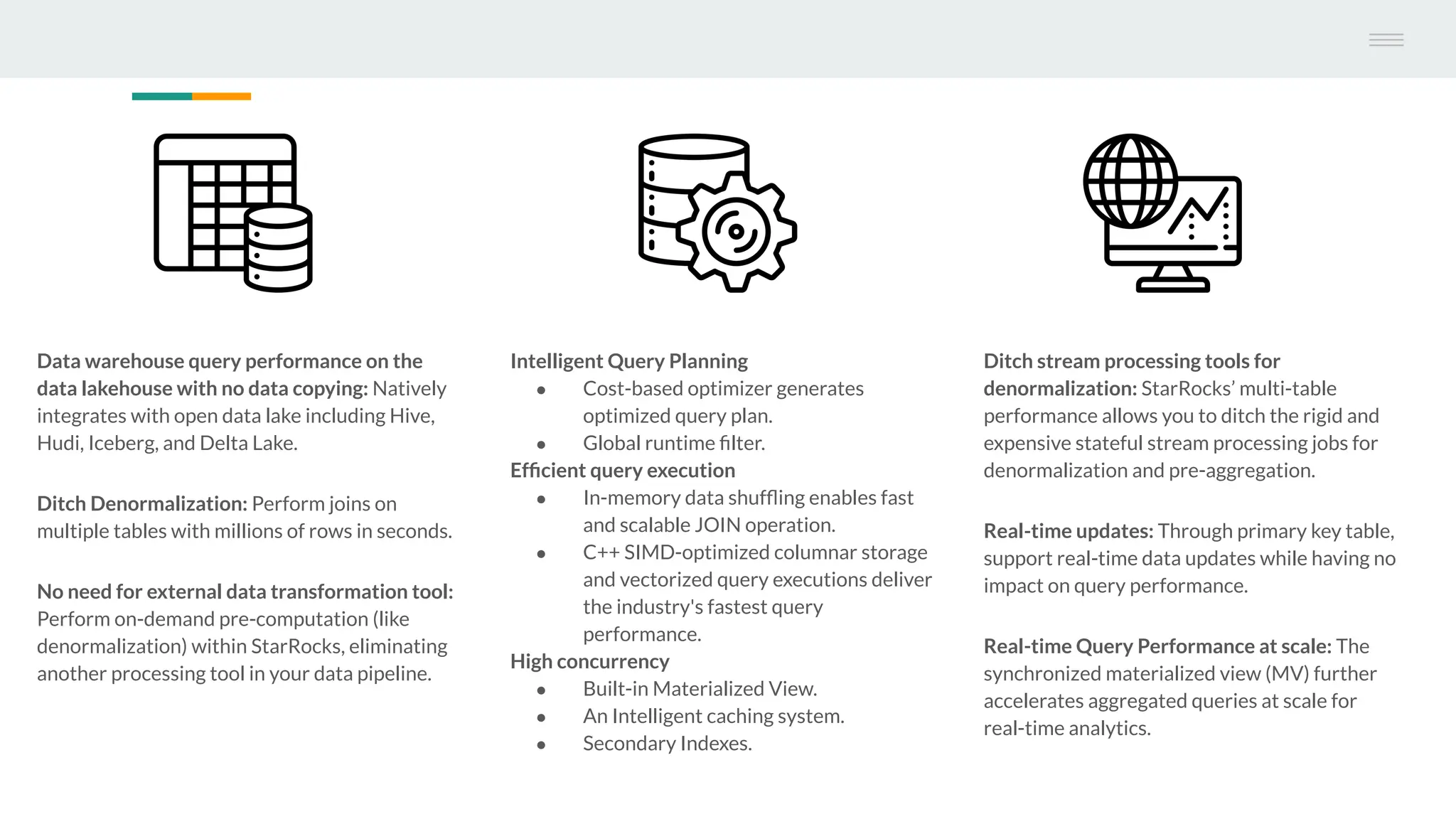
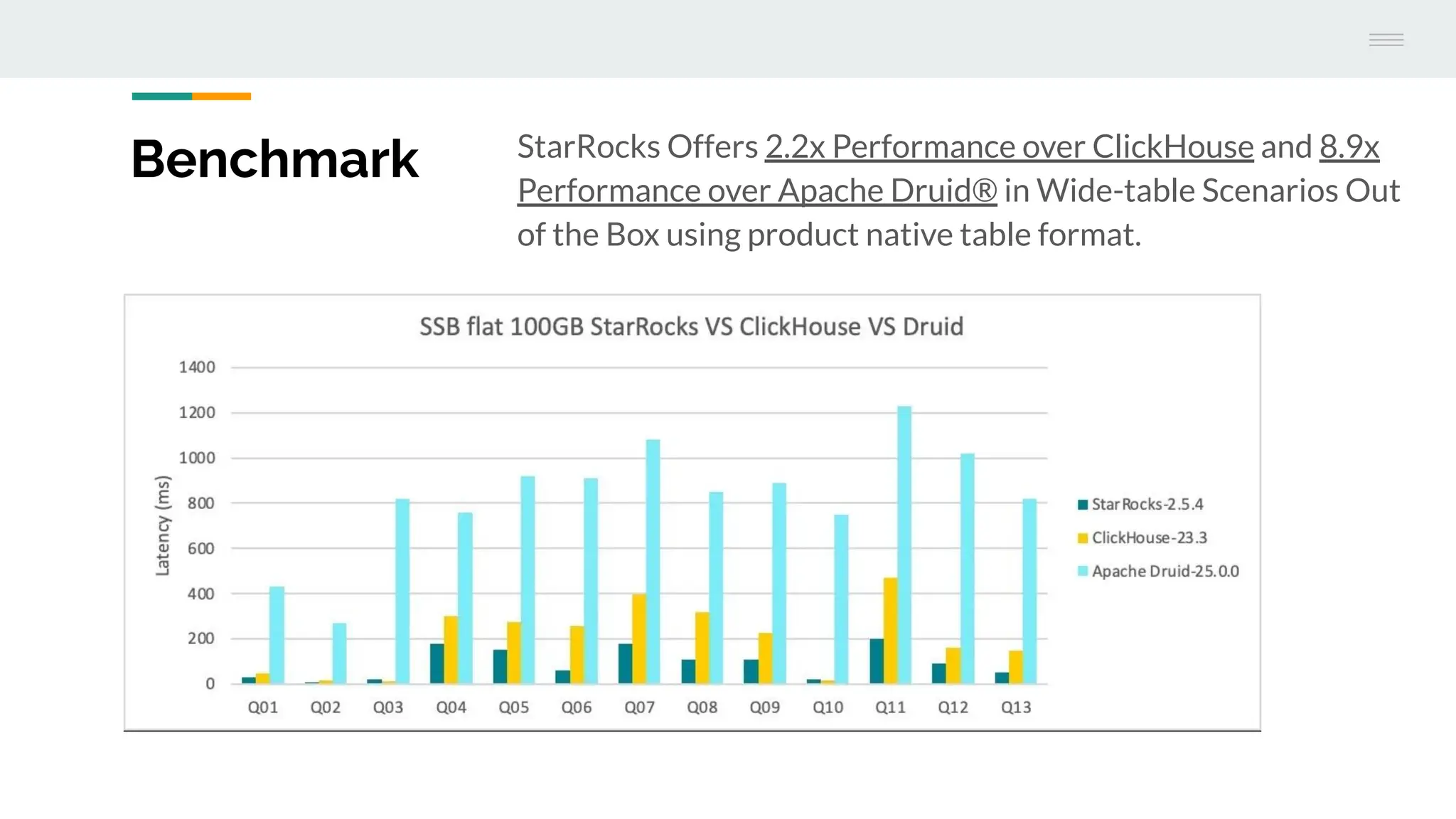
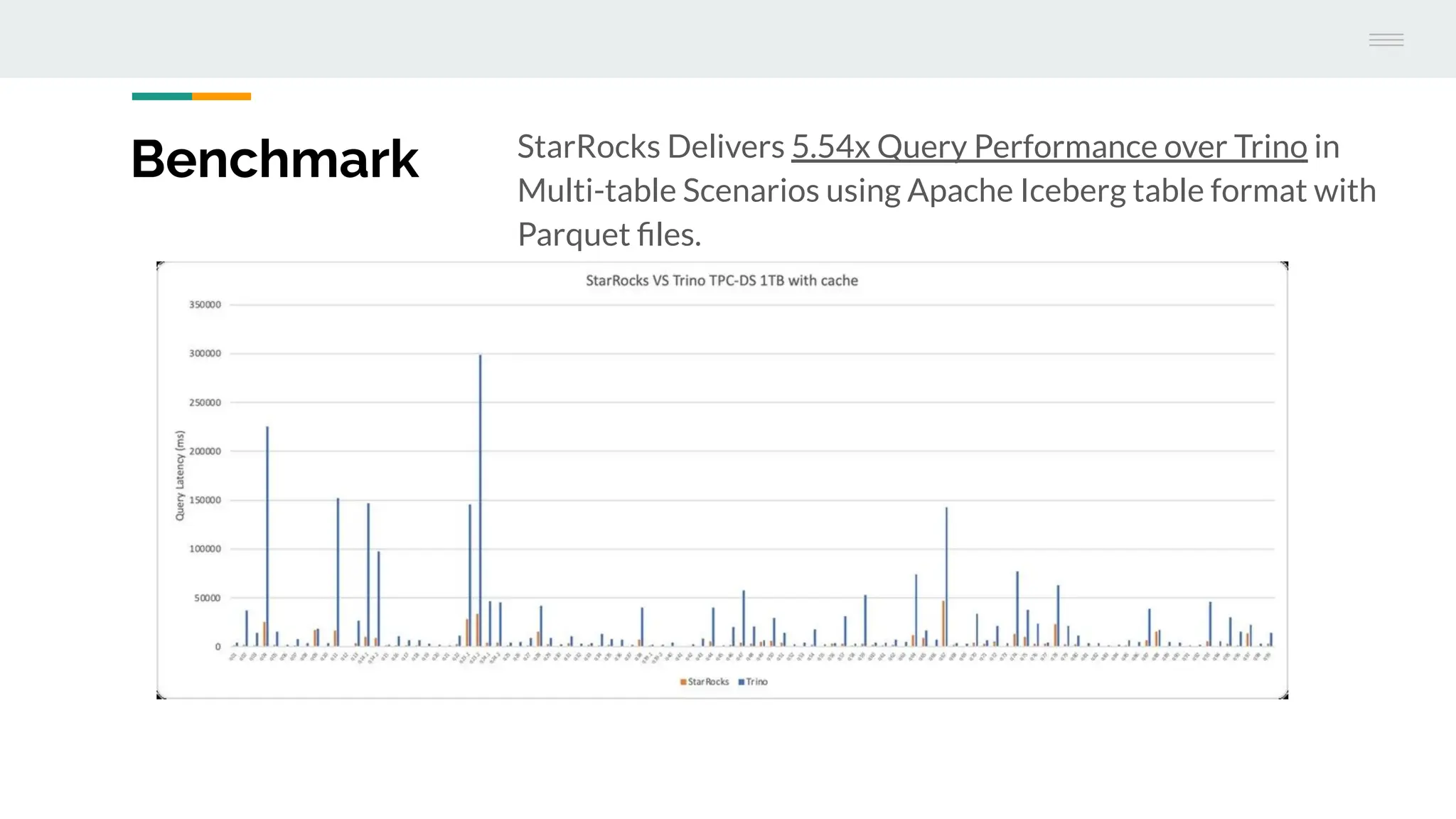
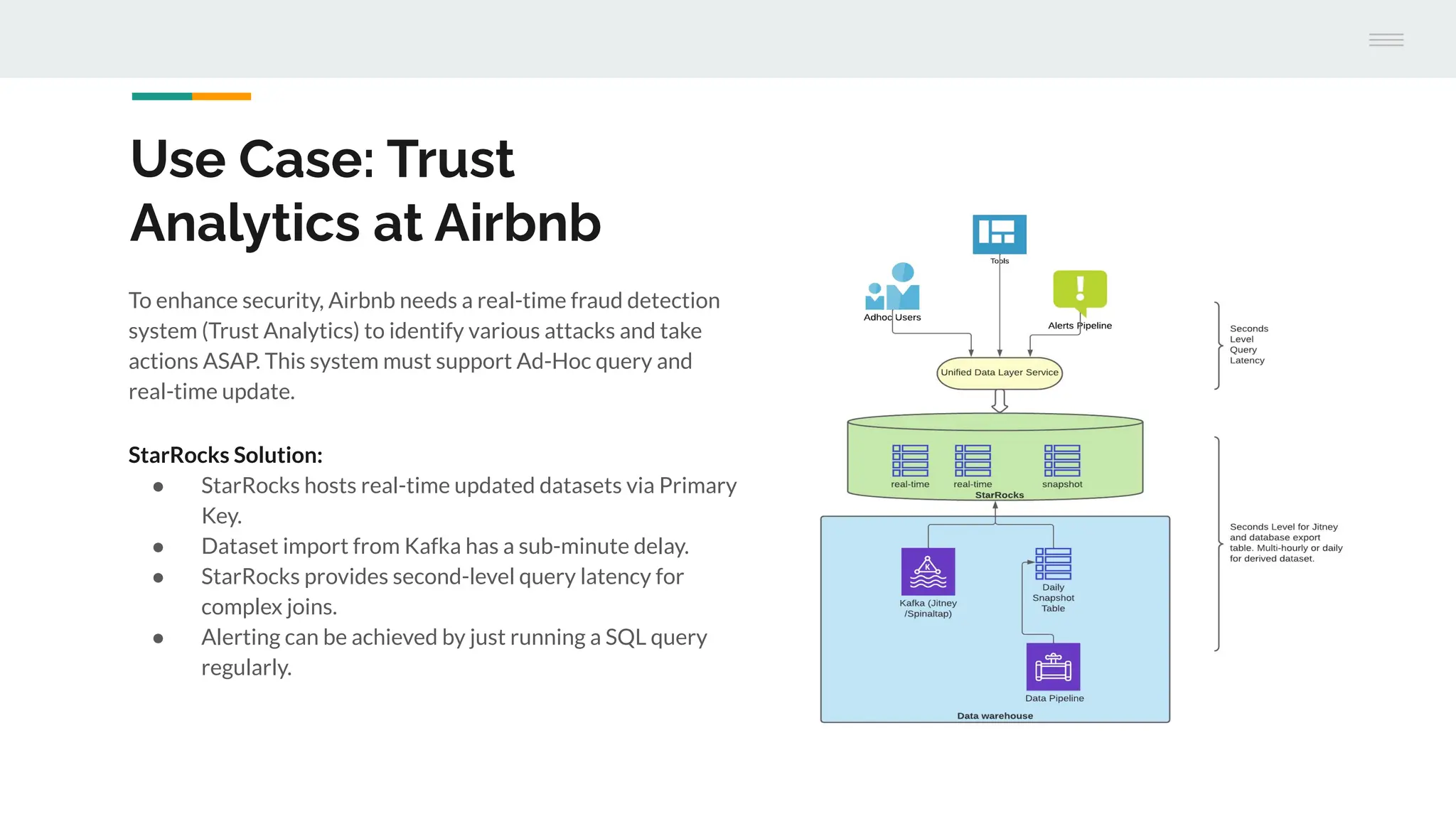
The document discusses StarRocks, a real-time analytics solution designed to address challenges such as high concurrency, low latency, and scalability in data processing. It highlights its capabilities in querying data directly from data lakes, performing complex queries with sub-second response times, and optimizing resource allocation for better cost efficiency. Additionally, several case studies showcase the effective application of StarRocks in organizations like Airbnb and Tencent for various analytics needs.

















![[pgday.Seoul 2022] PostgreSQL with Google Cloud](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-postgresqlwithgooglecloud-221114013605-5def484f-thumbnail.jpg?width=640&height=640&fit=bounds)



























![FastStone Capture 10.4 Crack + Serial Key [Latest]](https://cdn.slidesharecdn.com/ss_thumbnails/starrockstechnicaloverview-250128095402-02b8b419-thumbnail.jpg?width=640&height=640&fit=bounds)


![Adobe Photoshop CC 26.3 Crack + Serial Key [Latest 2025]](https://cdn.slidesharecdn.com/ss_thumbnails/starrockstechnicaloverview-250129092907-72c3d55c-thumbnail.jpg?width=640&height=640&fit=bounds)
![Serif Affinity Photo Crack 2.3.1.2217 + Serial Key [Latest]](https://cdn.slidesharecdn.com/ss_thumbnails/starrockstechnicaloverview-250128095832-74508123-thumbnail.jpg?width=640&height=640&fit=bounds)



![EASEUS Partition Master 18.8 Crack + License Code [2025]](https://cdn.slidesharecdn.com/ss_thumbnails/starrockstechnicaloverview-250128094712-a1013639-thumbnail.jpg?width=640&height=640&fit=bounds)




























