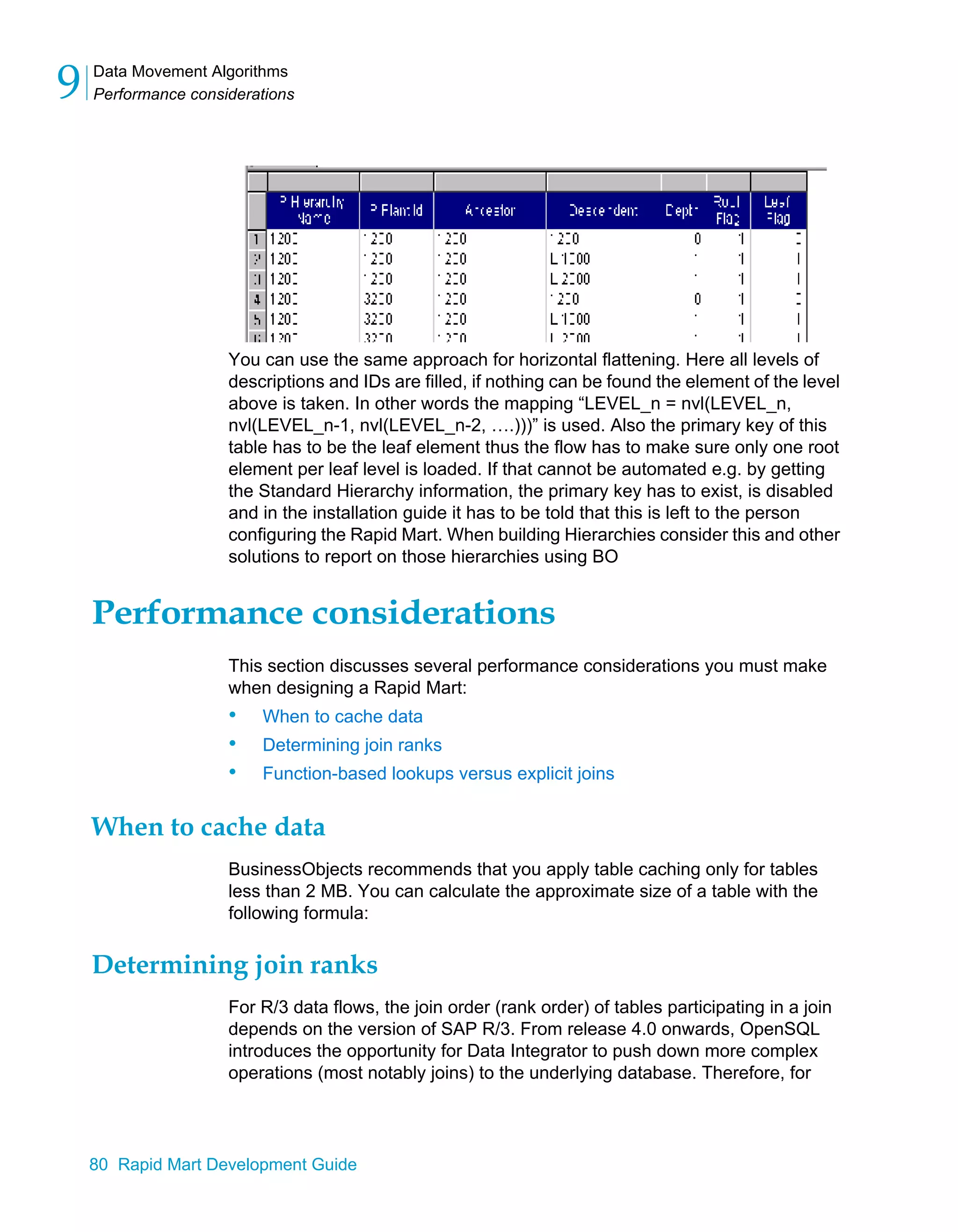
Downloaded 36 times







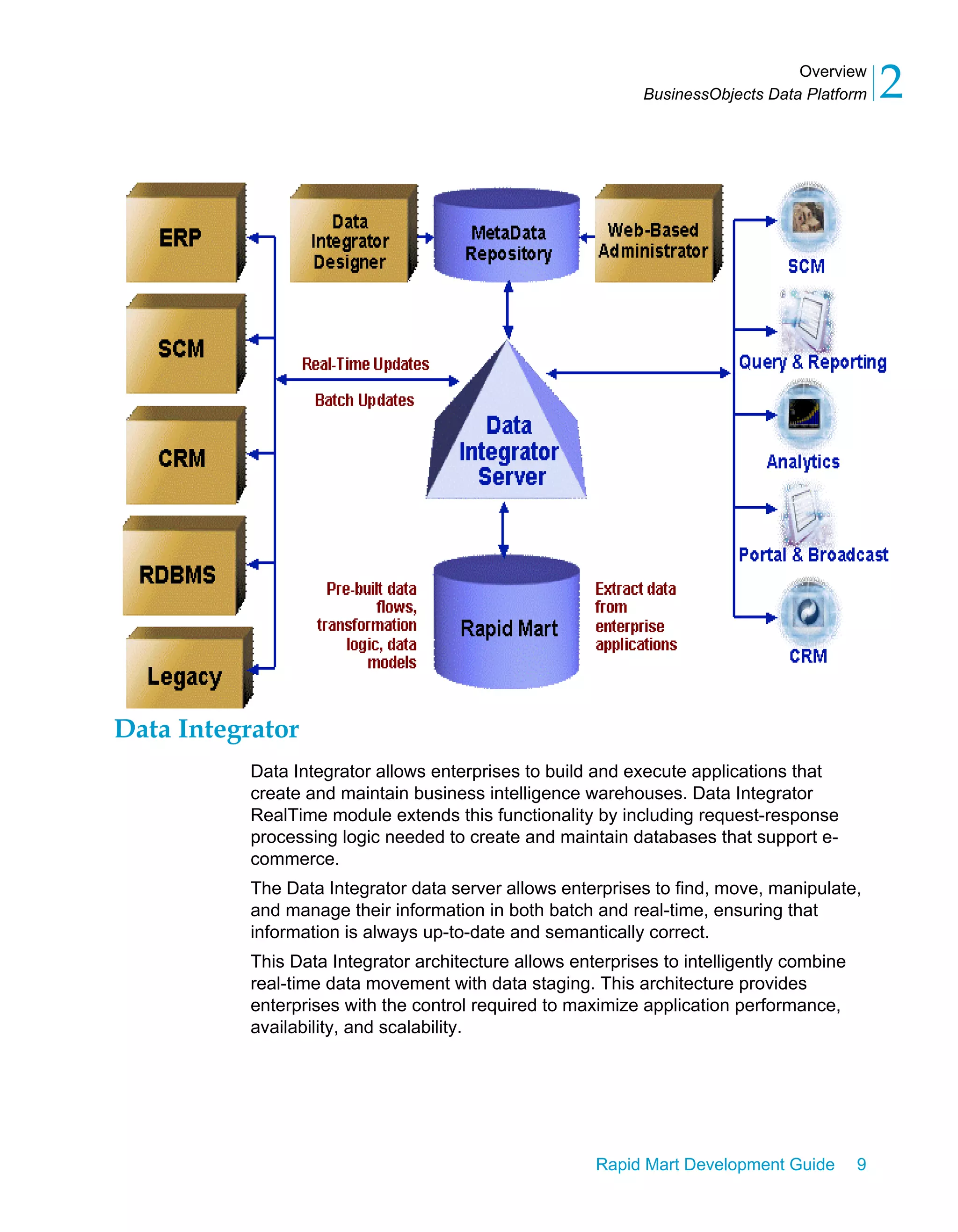















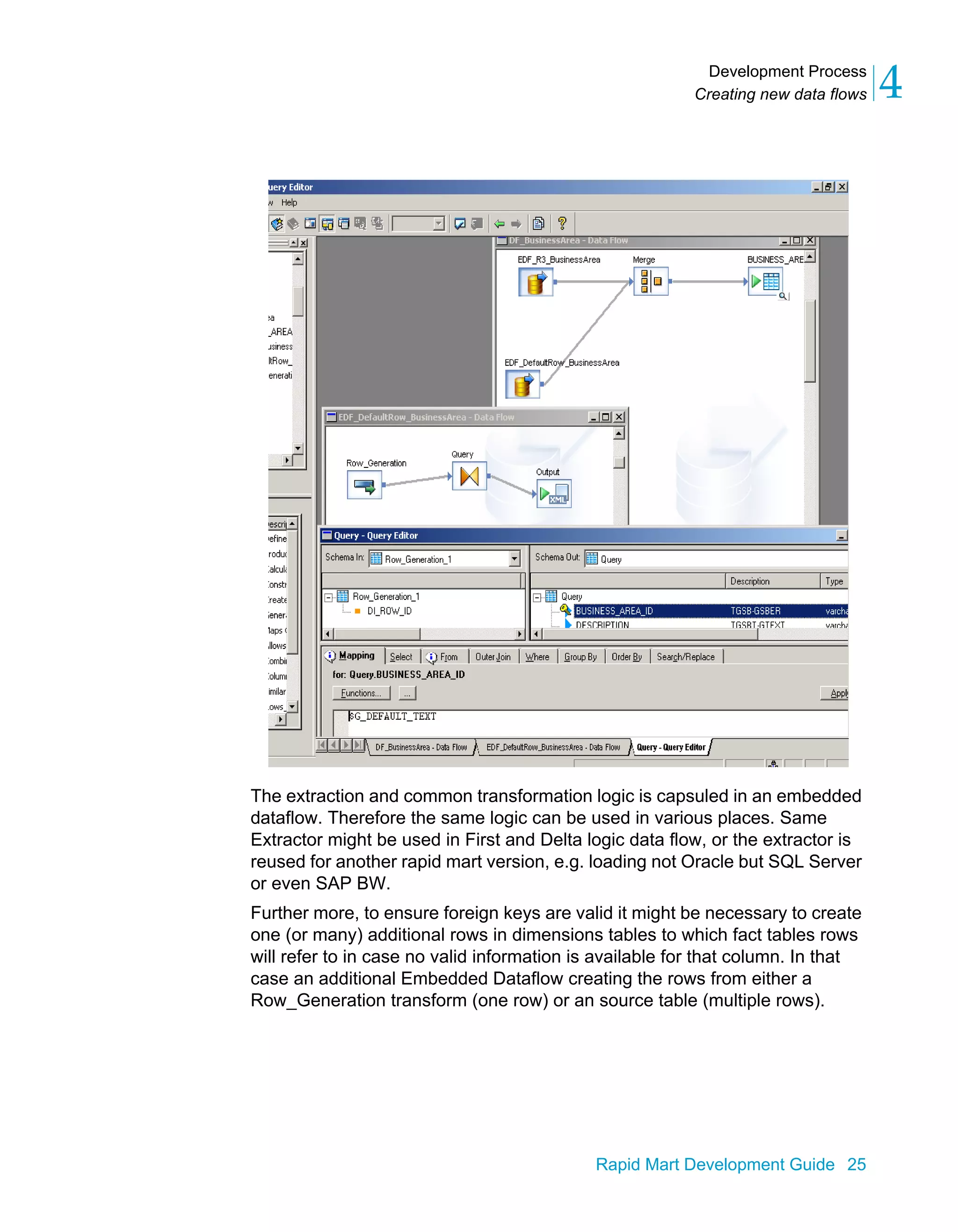
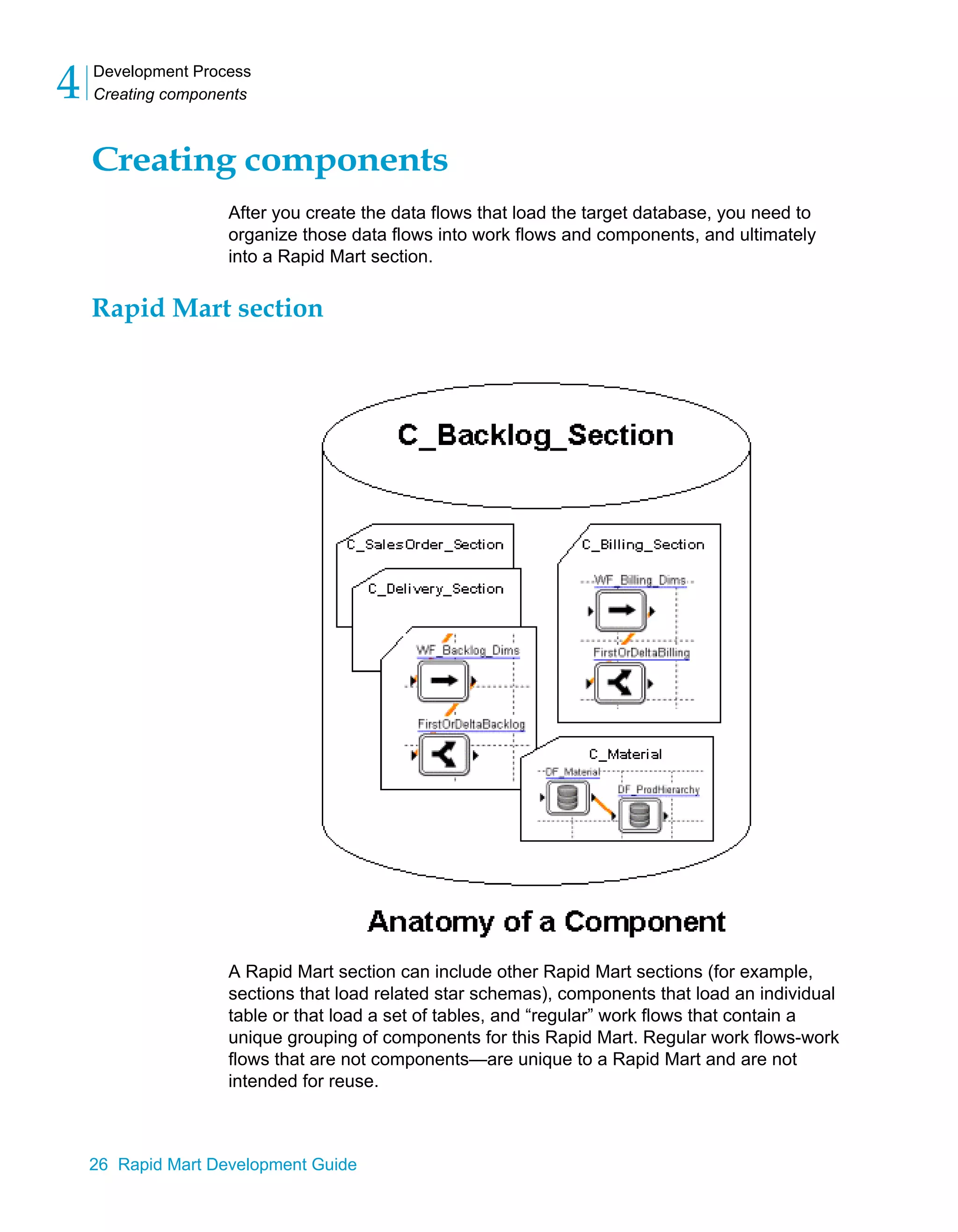




























































This document provides an overview of the BusinessObjects Data Platform and its components, including Data Integrator and Rapid Marts. Rapid Marts are pre-built data integration projects that use the Data Integrator framework to extract, transform, and load data from source systems into a data warehouse or operational database. The BusinessObjects Data Platform allows enterprises to integrate data from various sources, cache it in a relational database, and provide business and analytic applications easy access to up-to-date integrated data.


































![ABAP_RESTful_Programming_Model_EN[1].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/abaprestfulprogrammingmodelen1-231210152009-537059a3-thumbnail.jpg?width=640&height=640&fit=bounds)











