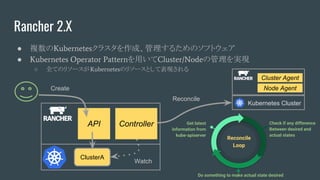
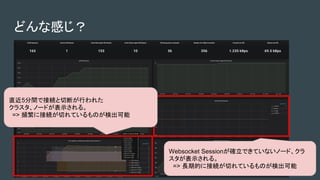
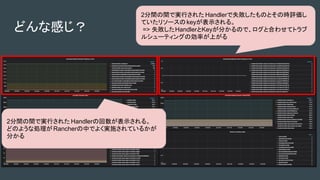
Rancher 2.X
● 複数のKubernetesクラスタを作成、管理するためのソフトウェア
●Kubernetes Operator Patternを用いてCluster/Nodeの管理を実現
○ 全てのリソースがKubernetesのリソースとして表現される
API Controller
ClusterA
Watch
Reconcile
Get latest
information from
kube-apiserver
Check if any difference
Between desired and
actual states
Do something to make actual state desired
Reconcile
Loop
Kubernetes Cluster
Cluster Agent
Node AgentCreate
14.
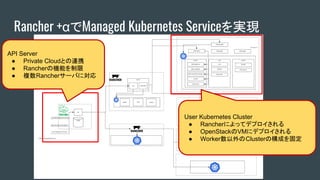
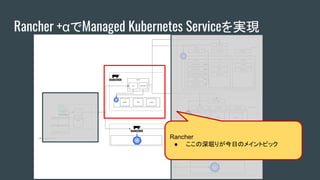
Rancher +αでManaged KubernetesServiceを実現
API Server
● Private Cloudとの連携
● Rancherの機能を制限
● 複数Rancherサーバに対応
User Kubernetes Cluster
● Rancherによってデプロイされる
● OpenStackのVMにデプロイされる
● Worker数以外のClusterの構成を固定
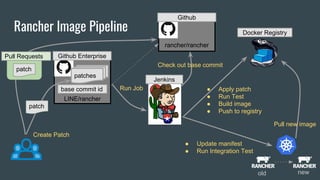
Rancher Image Pipeline
rancher/rancher
LINE/rancher
basecommit id
patches
Create Patch
patch
patch
Pull Requests
Run Job
Check out base commit
● Apply patch
● Run Test
● Build image
● Push to registry
Github Enterprise
Github
Jenkins
Docker Registry
● Update manifest
● Run Integration Test
Pull new image
old new












































![Recap: [Code fresh] Deploying to kubernetes thousands of times per day @kuber...](https://cdn.slidesharecdn.com/ss_thumbnails/codefreshdeployingtokubernetesthousandsoftimesperdaykubernetesmeetup9-180112141040-thumbnail.jpg?width=640&height=640&fit=bounds)












































