Downloaded 11 times
















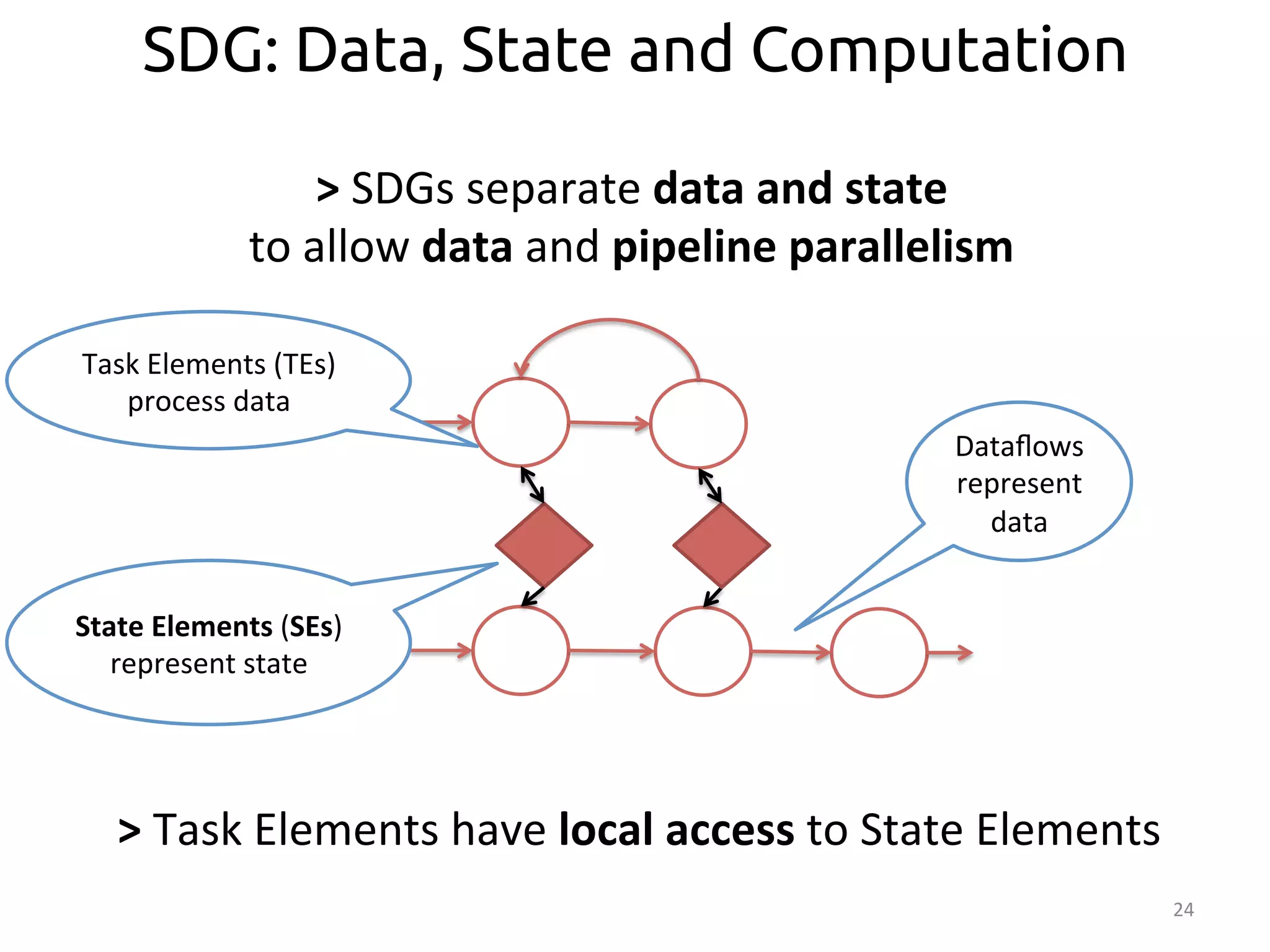

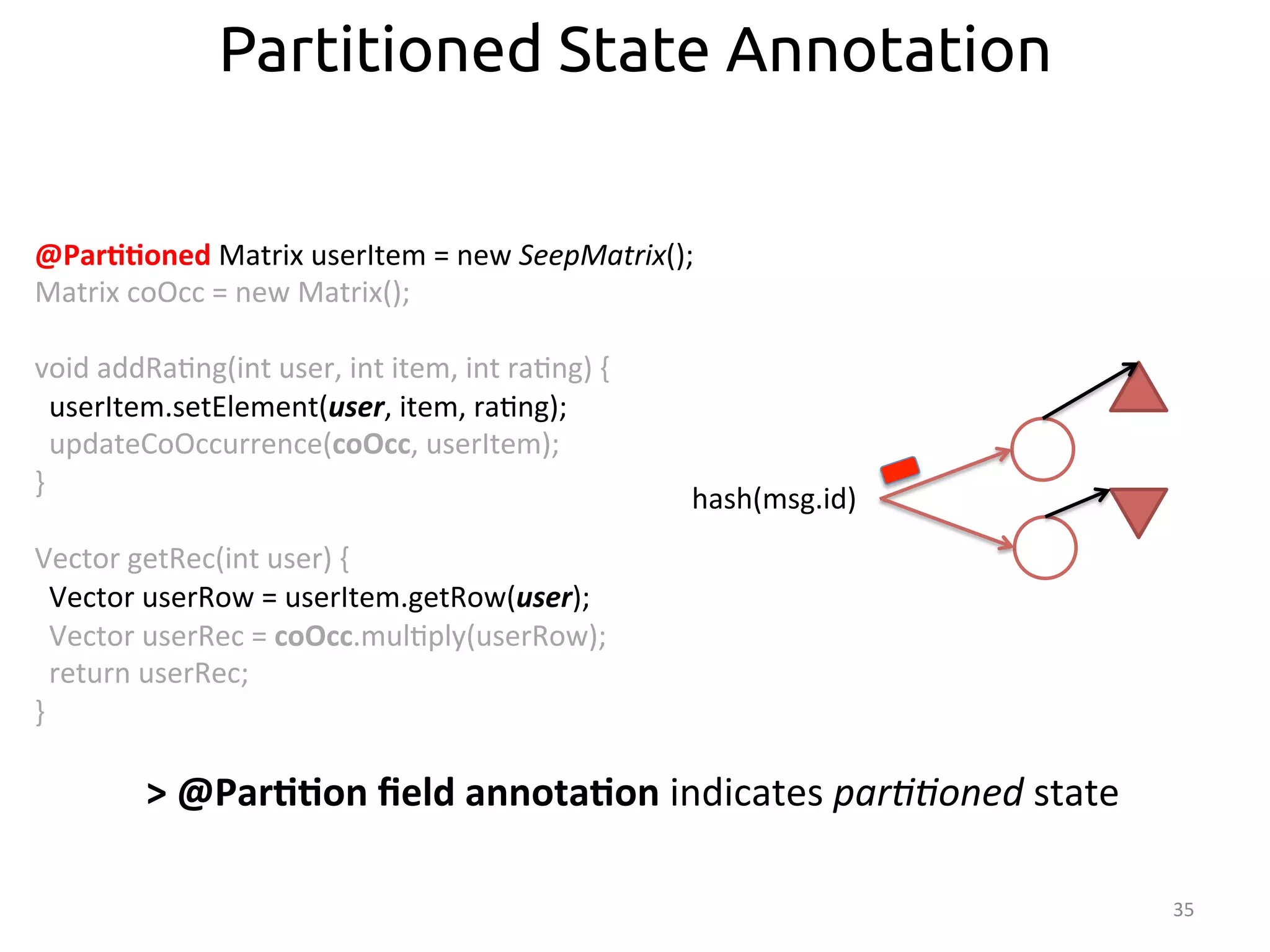
![Distributed Mutable State: Partitioned SEs
Access
by
key
State
par::oned
according
26
Dataflow
routed
according
to
hash
func:on
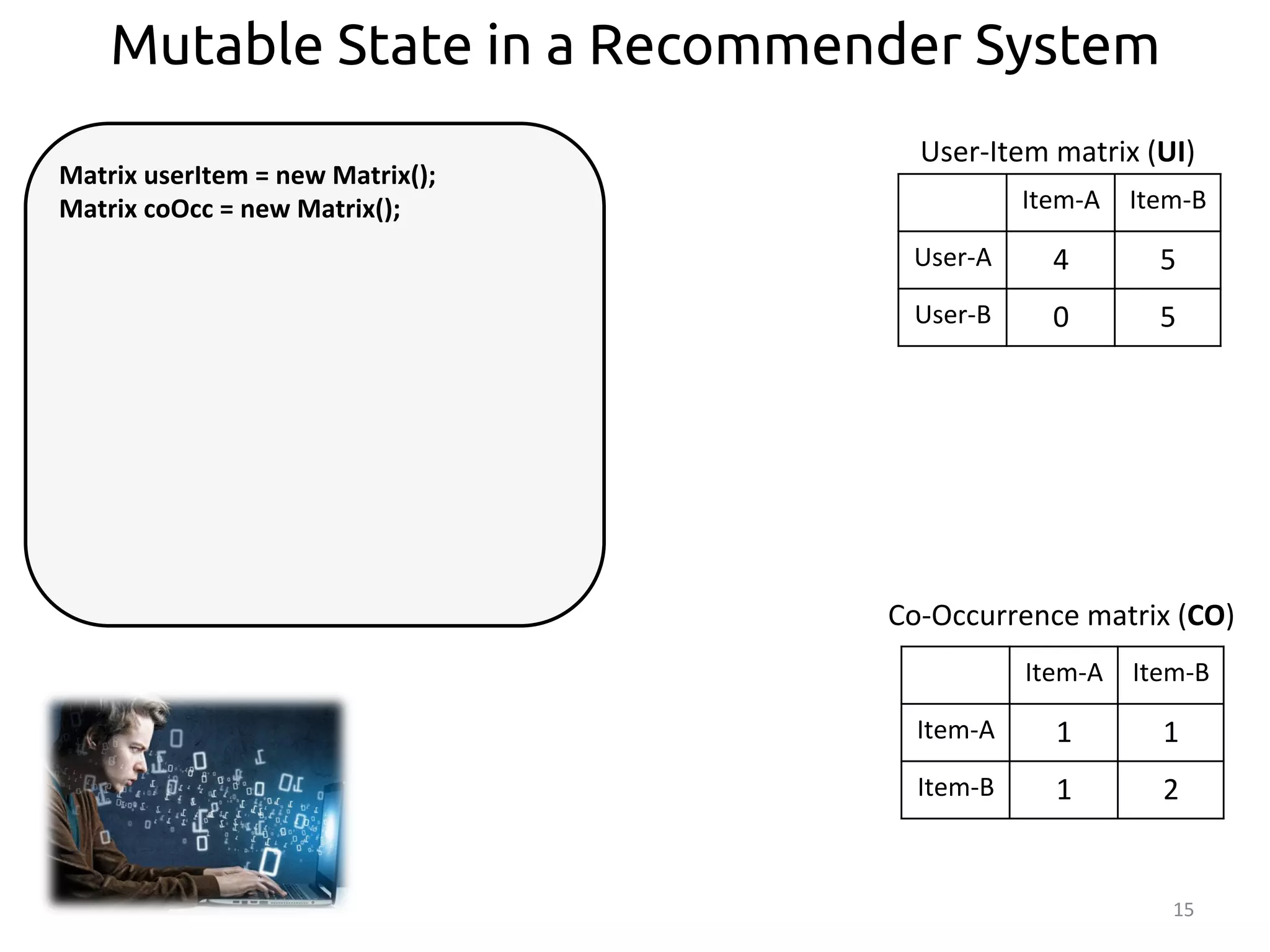
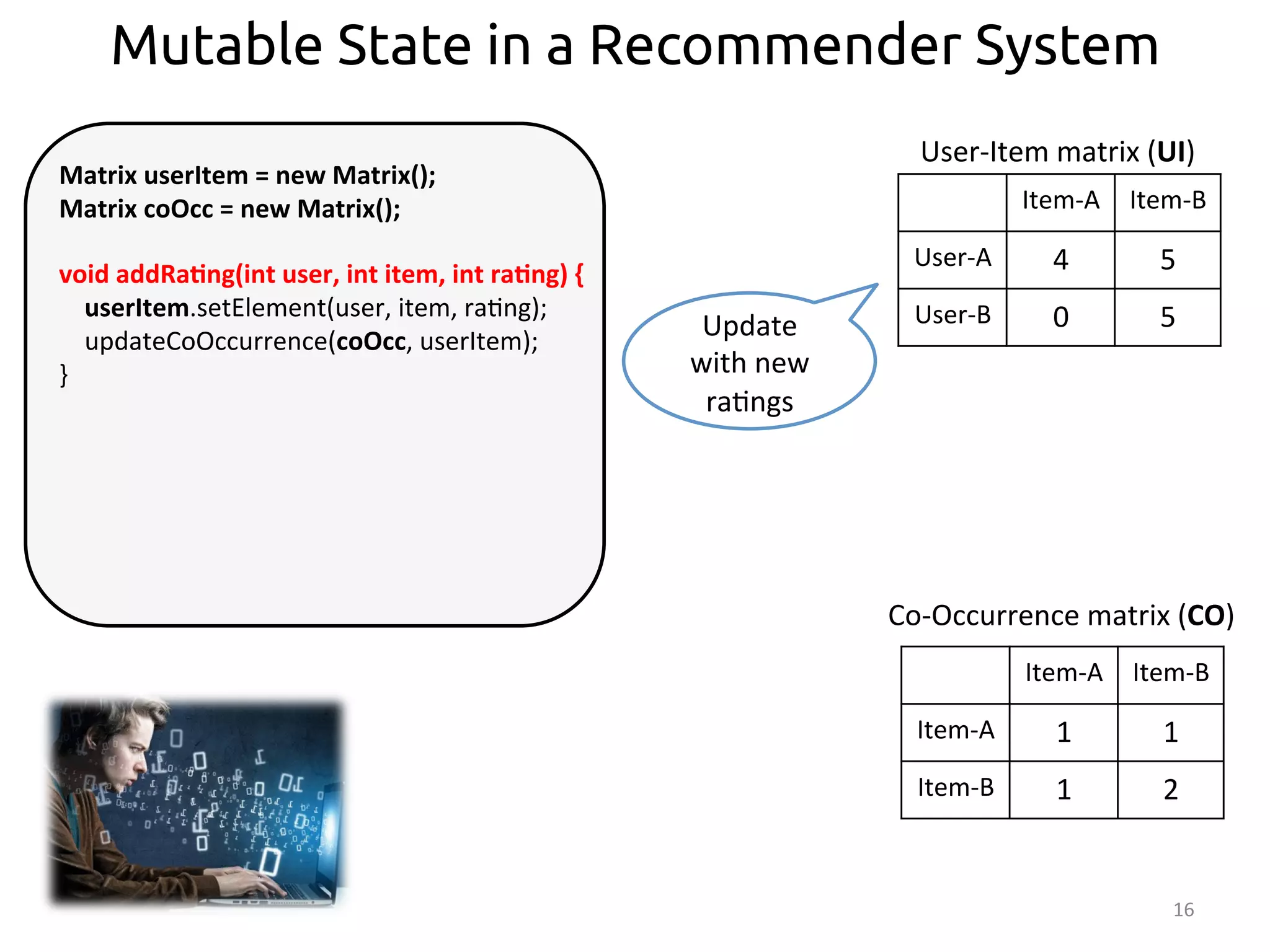
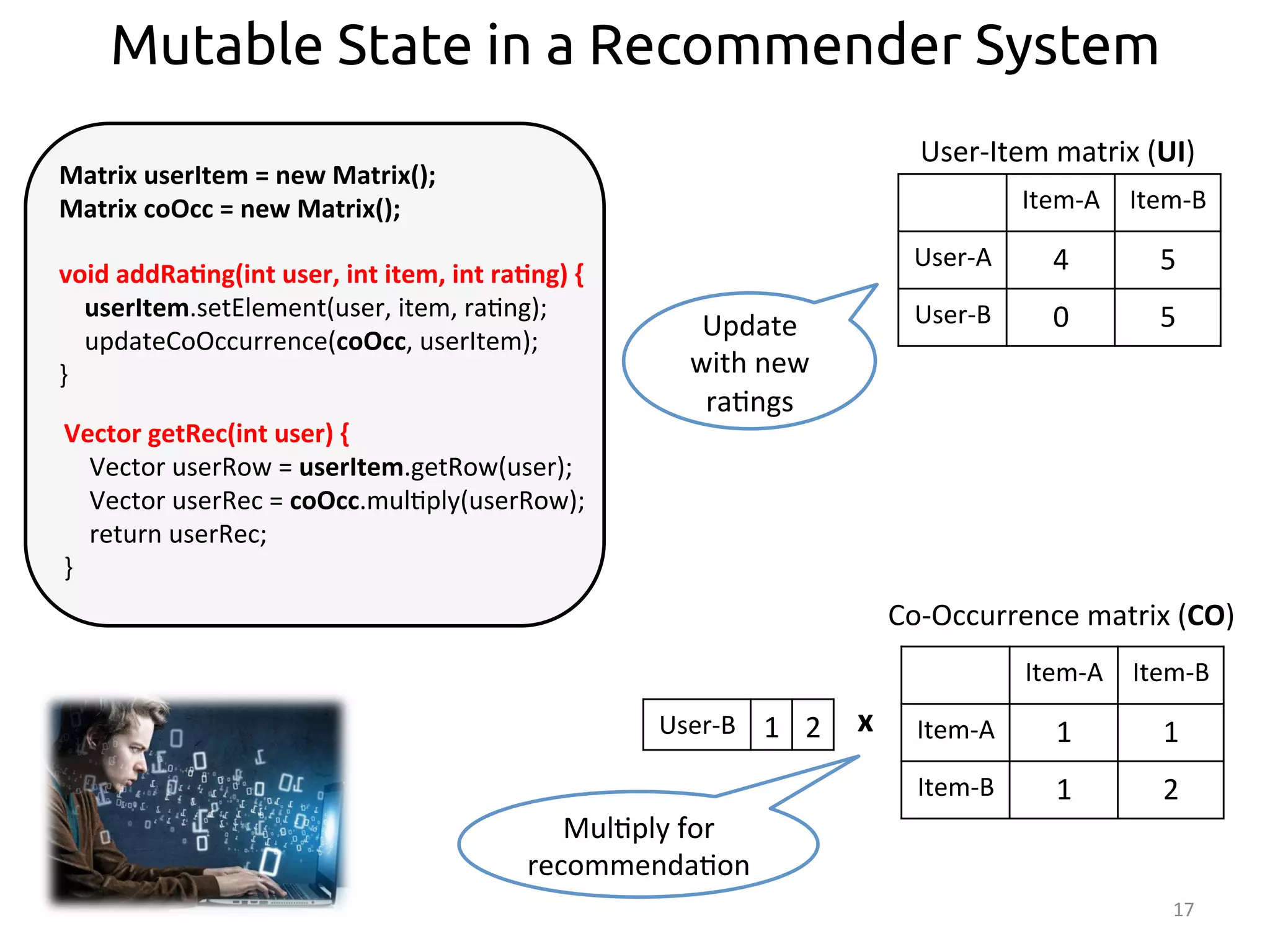
Item-‐A
Item-‐B
User-‐A
4
5
User-‐B
0
5
to
par>>oning
key
>
Par>>oned
SEs
split
into
disjoint
par::ons
User-‐Item
matrix
(UI)
hash(msg.id)
Key
space:
[0-‐N]
[0-‐k]
[(k+1)-‐N]](https://image.slidesharecdn.com/ralcastrofernndez-theabstractionthatpowersthebigdatatechnology-bigdataspain2014-141125025741-conversion-gate01/75/Dataflows-The-abstraction-that-powers-Big-Data-by-Raul-Castro-Fernandez-at-Big-Data-Spain-2014-27-2048.jpg)
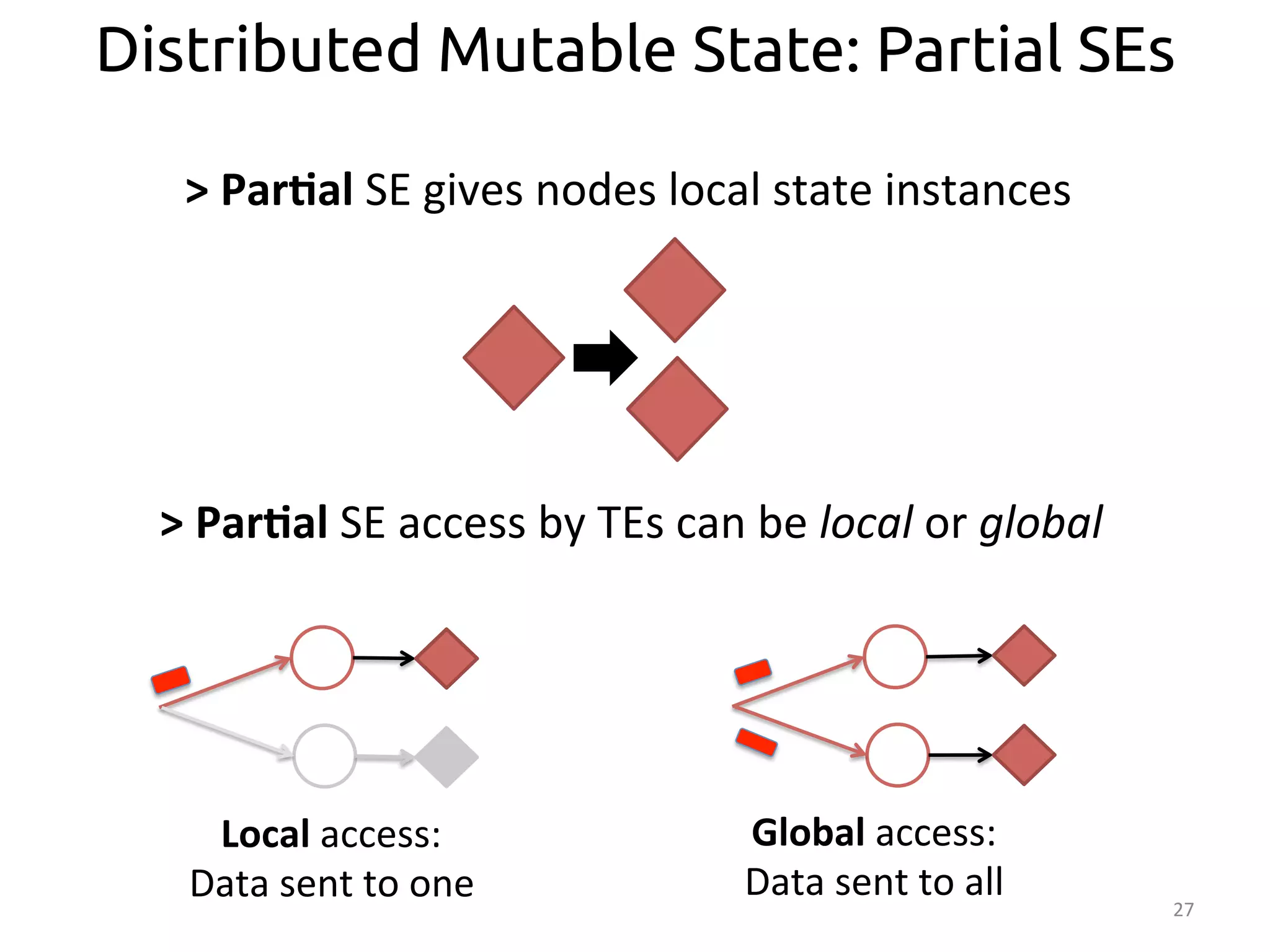
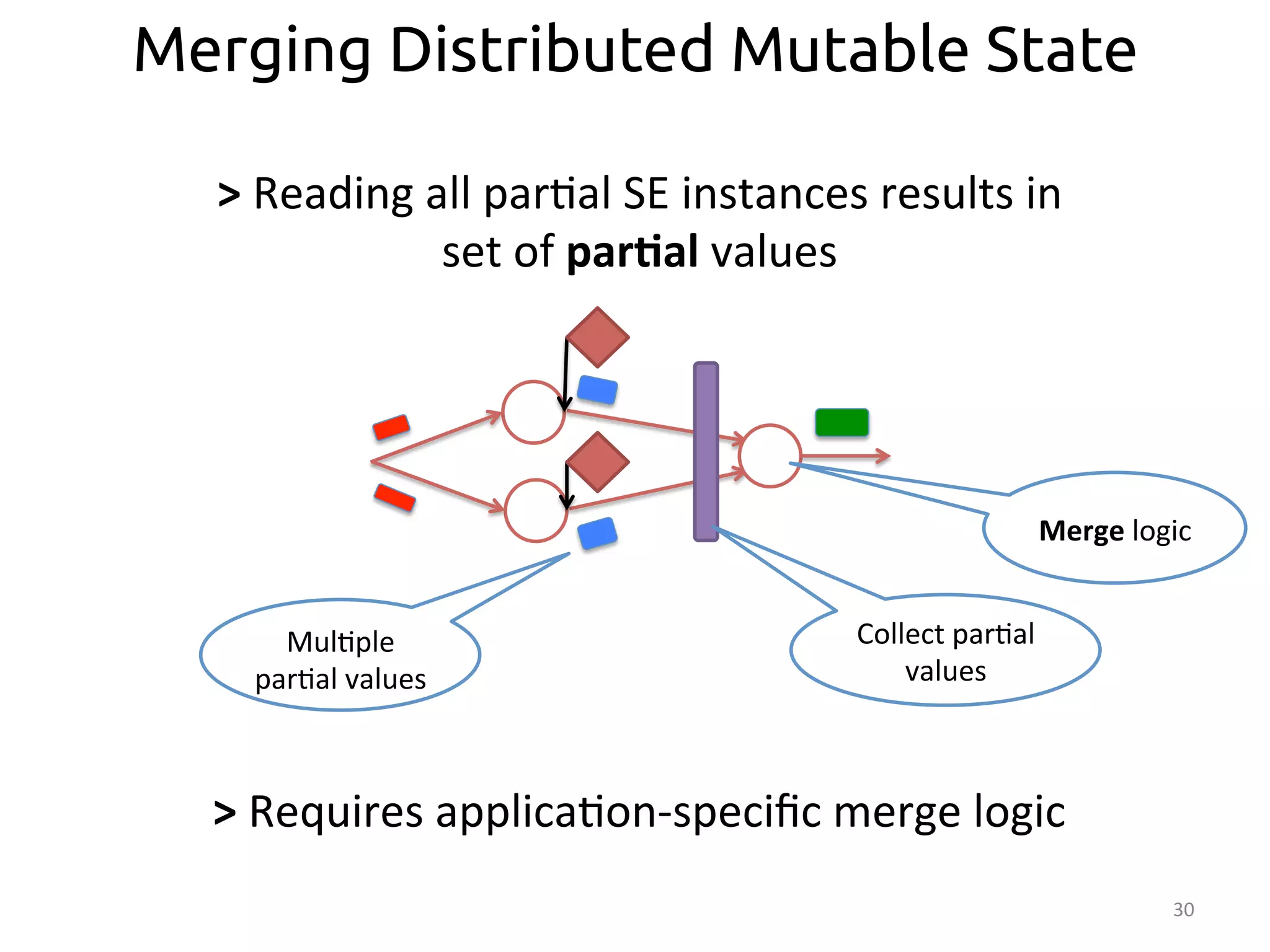
![32
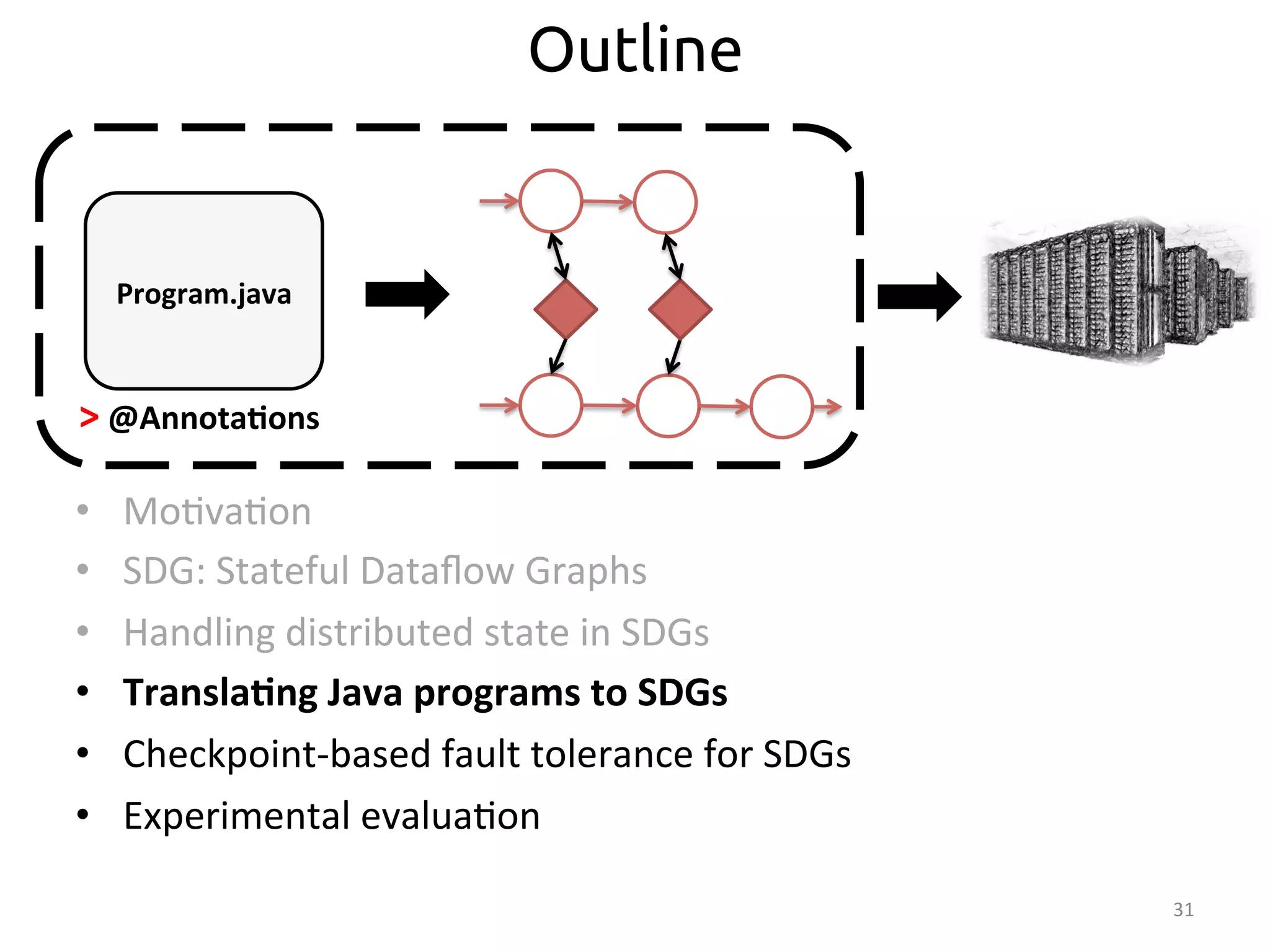
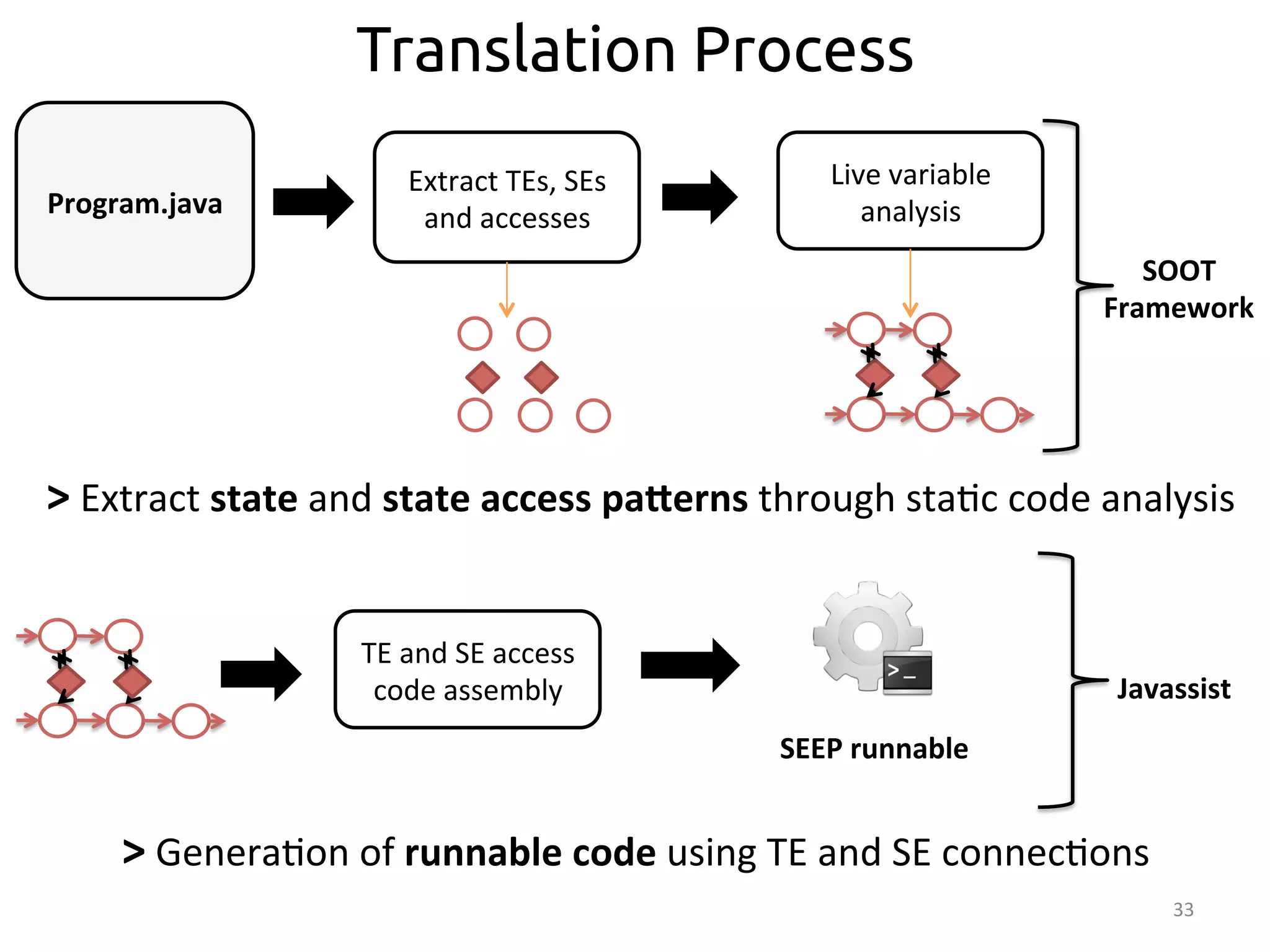
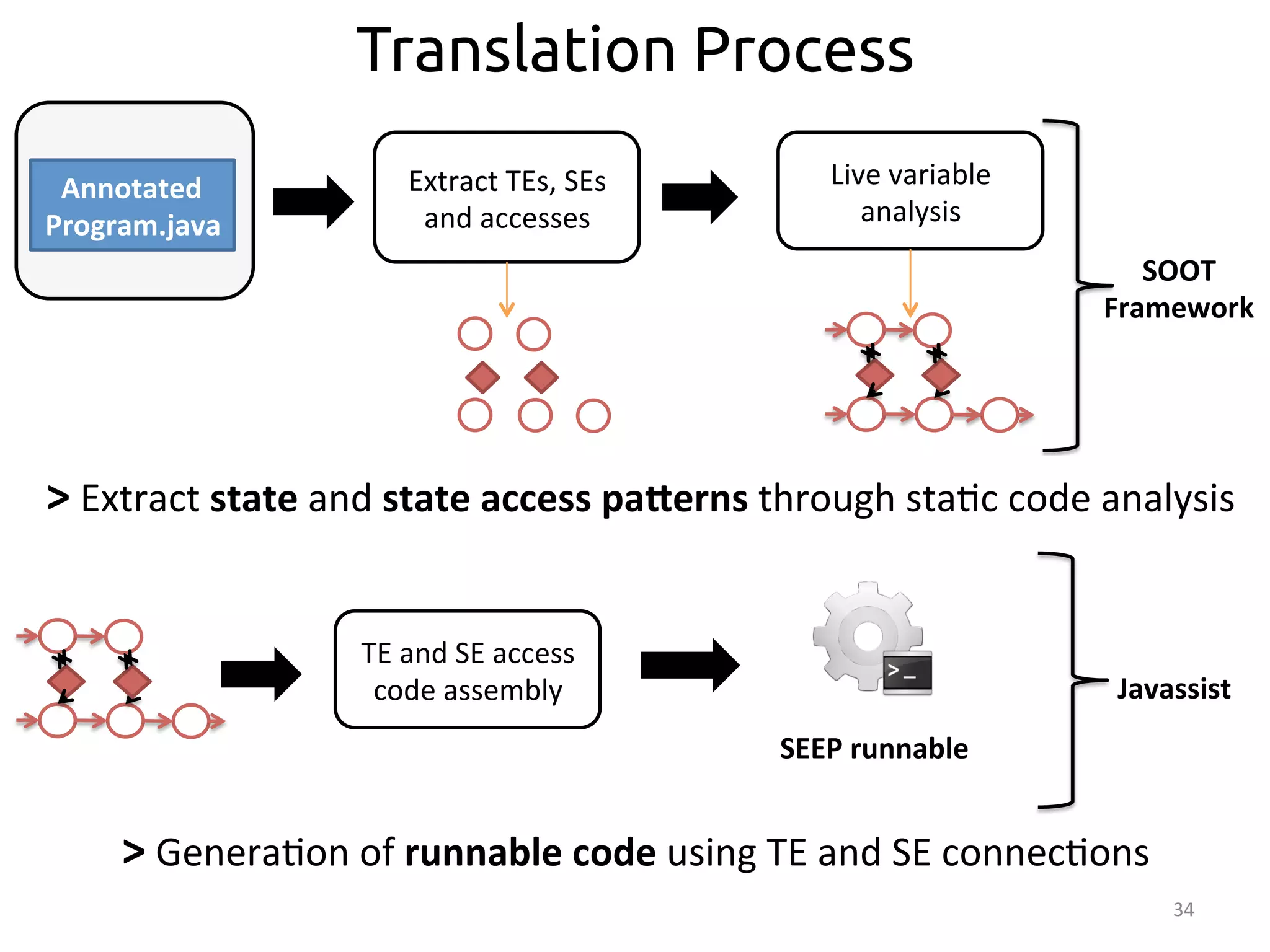
From Imperative Code to Execution
SEEP
Annotated
program
>
SEEP:
data-‐parallel
processing
plaborm
• Transla:on
occurs
in
two
stages:
– Sta<c
code
analysis:
From
Java
to
SDG
– Bytecode
rewri<ng:
From
SDG
to
SEEP
[SIGMOD’13]
Program.java](https://image.slidesharecdn.com/ralcastrofernndez-theabstractionthatpowersthebigdatatechnology-bigdataspain2014-141125025741-conversion-gate01/75/Dataflows-The-abstraction-that-powers-Big-Data-by-Raul-Castro-Fernandez-at-Big-Data-Spain-2014-33-2048.jpg)
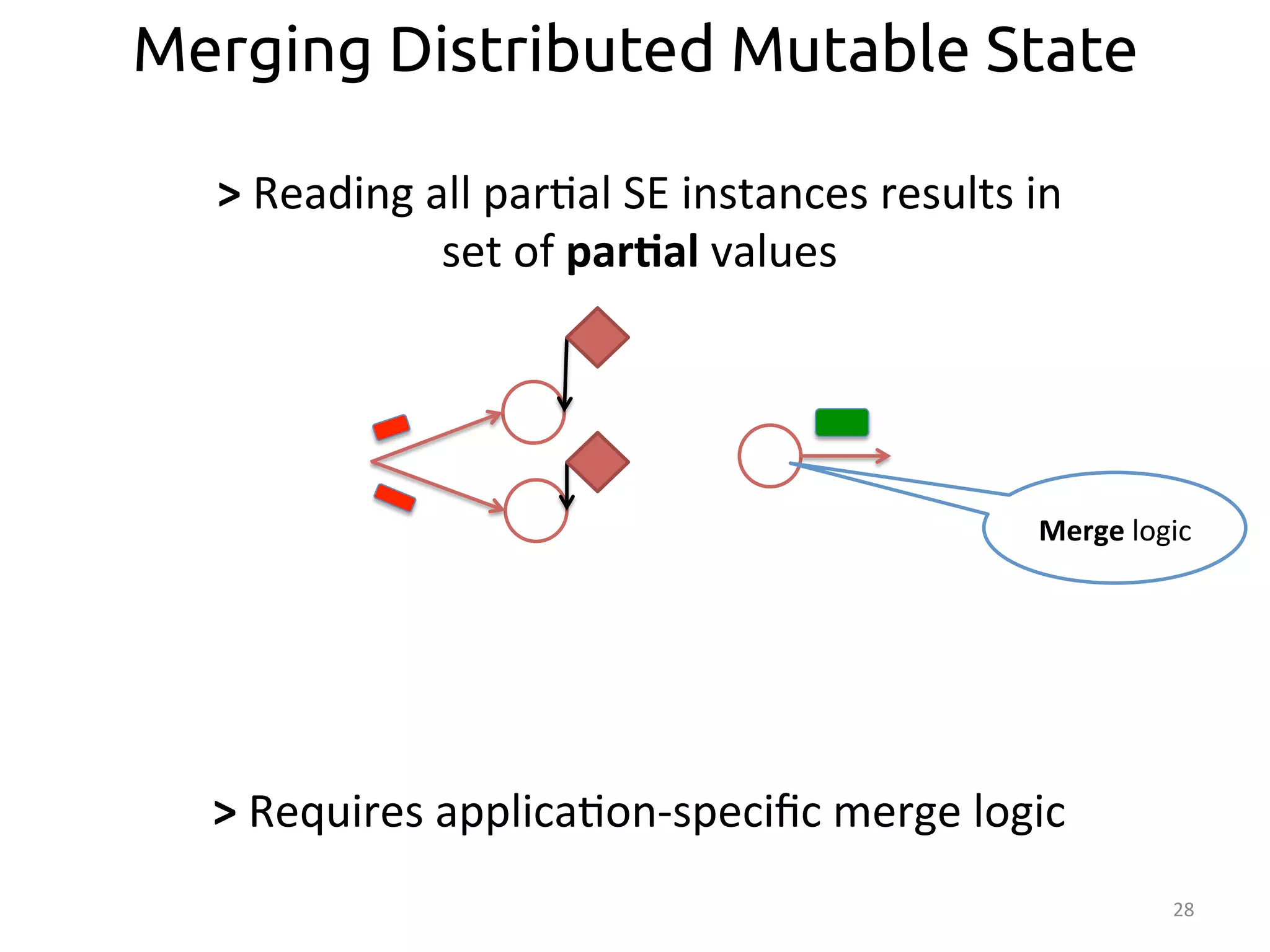
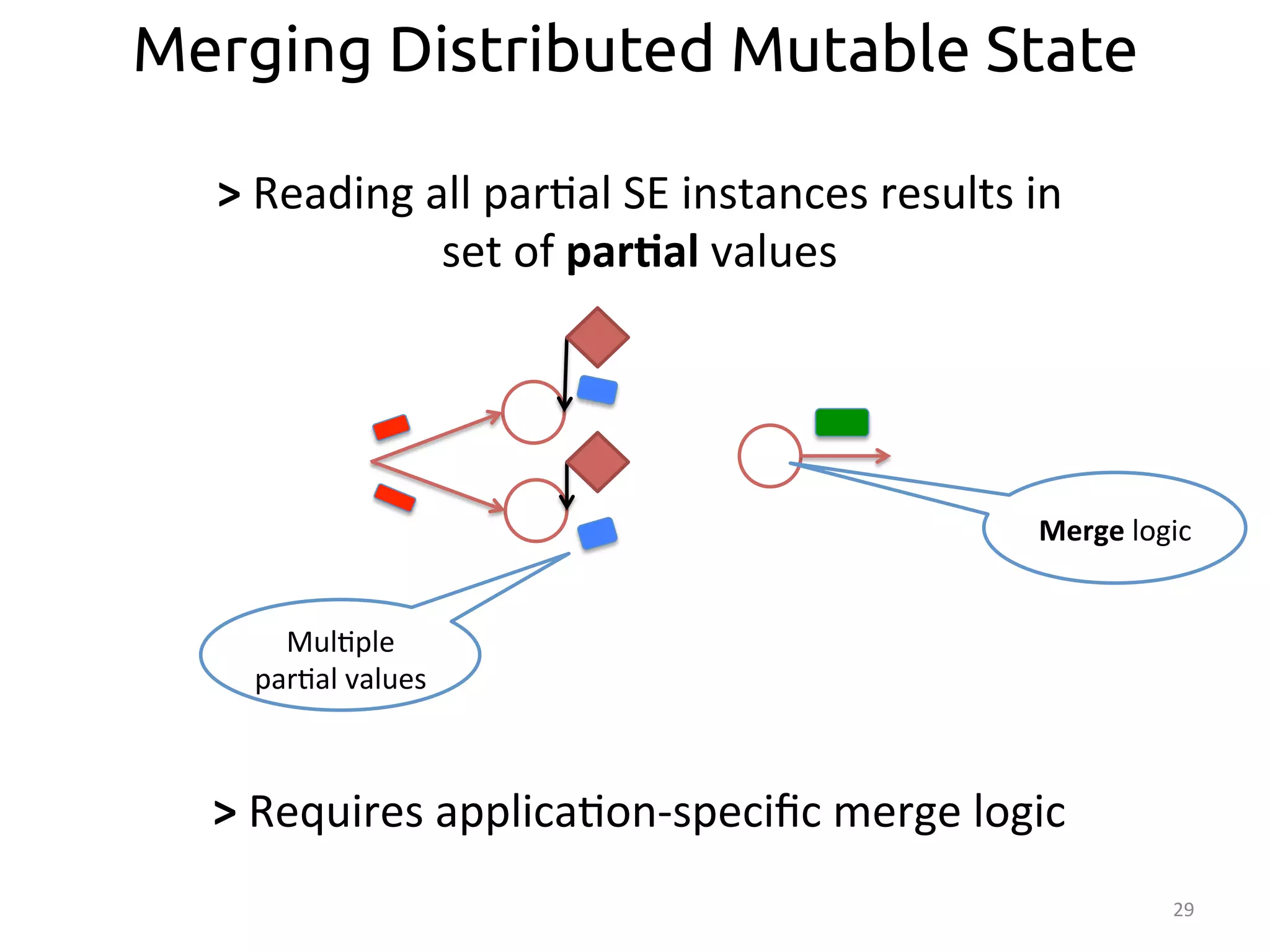
![37
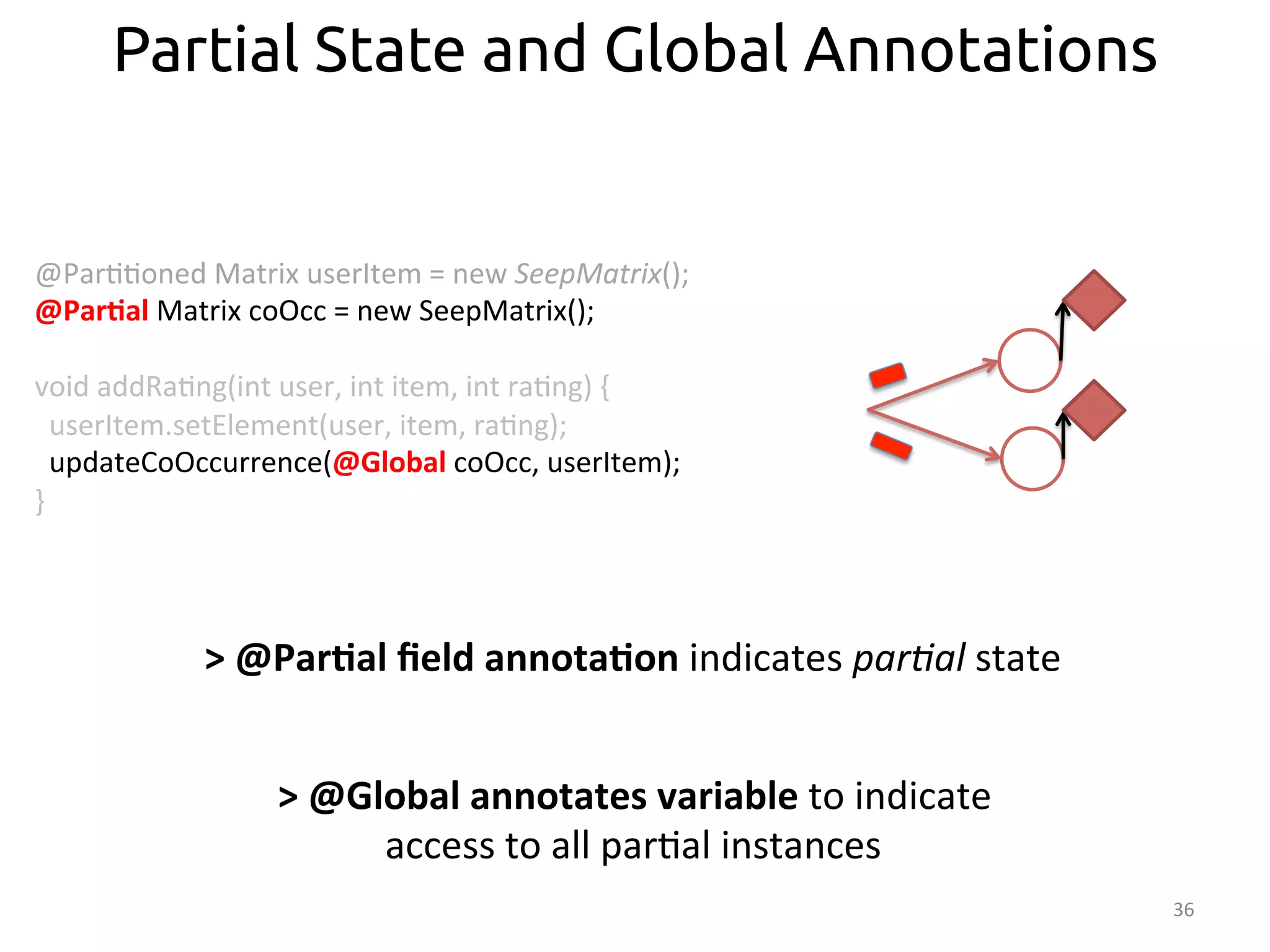
Partial and Collection Annotations
@Par::oned
Matrix
userItem
=
new
SeepMatrix();
@Par>al
Matrix
coOcc
=
new
SeepMatrix();
Vector
getRec(int
user)
{
Vector
userRow
=
userItem.getRow(user);
@Par>al
Vector
puRec
=
@Global
coOcc.mul:ply(userRow);
Vector
userRec
=
merge(puRec);
return
userRec;
}
Vector
merge(@Collec>on
Vector[]
v){
/*…*/
}
>
@Collec>on
annota:on
indicates
merge
logic](https://image.slidesharecdn.com/ralcastrofernndez-theabstractionthatpowersthebigdatatechnology-bigdataspain2014-141125025741-conversion-gate01/75/Dataflows-The-abstraction-that-powers-Big-Data-by-Raul-Castro-Fernandez-at-Big-Data-Spain-2014-38-2048.jpg)
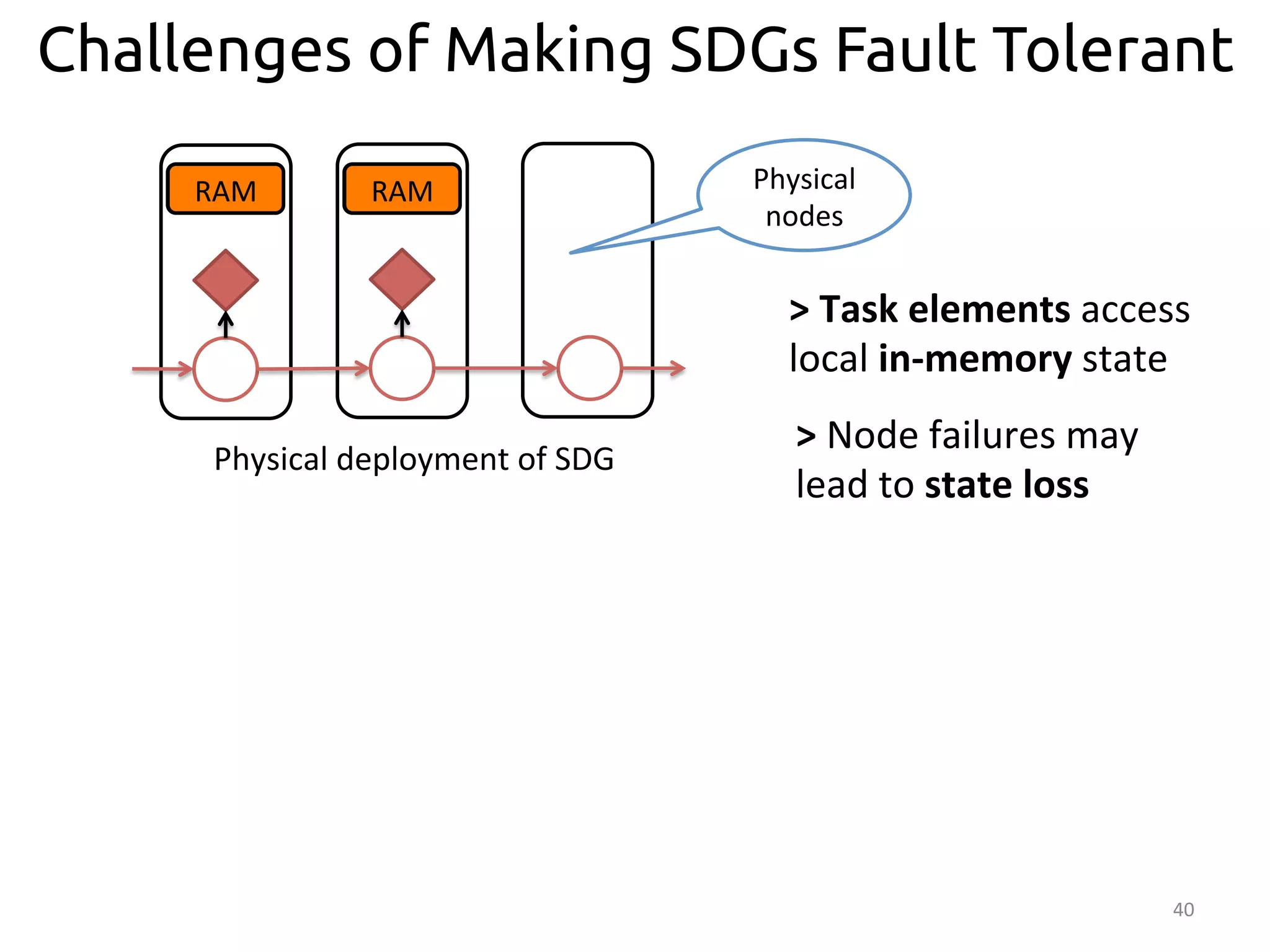
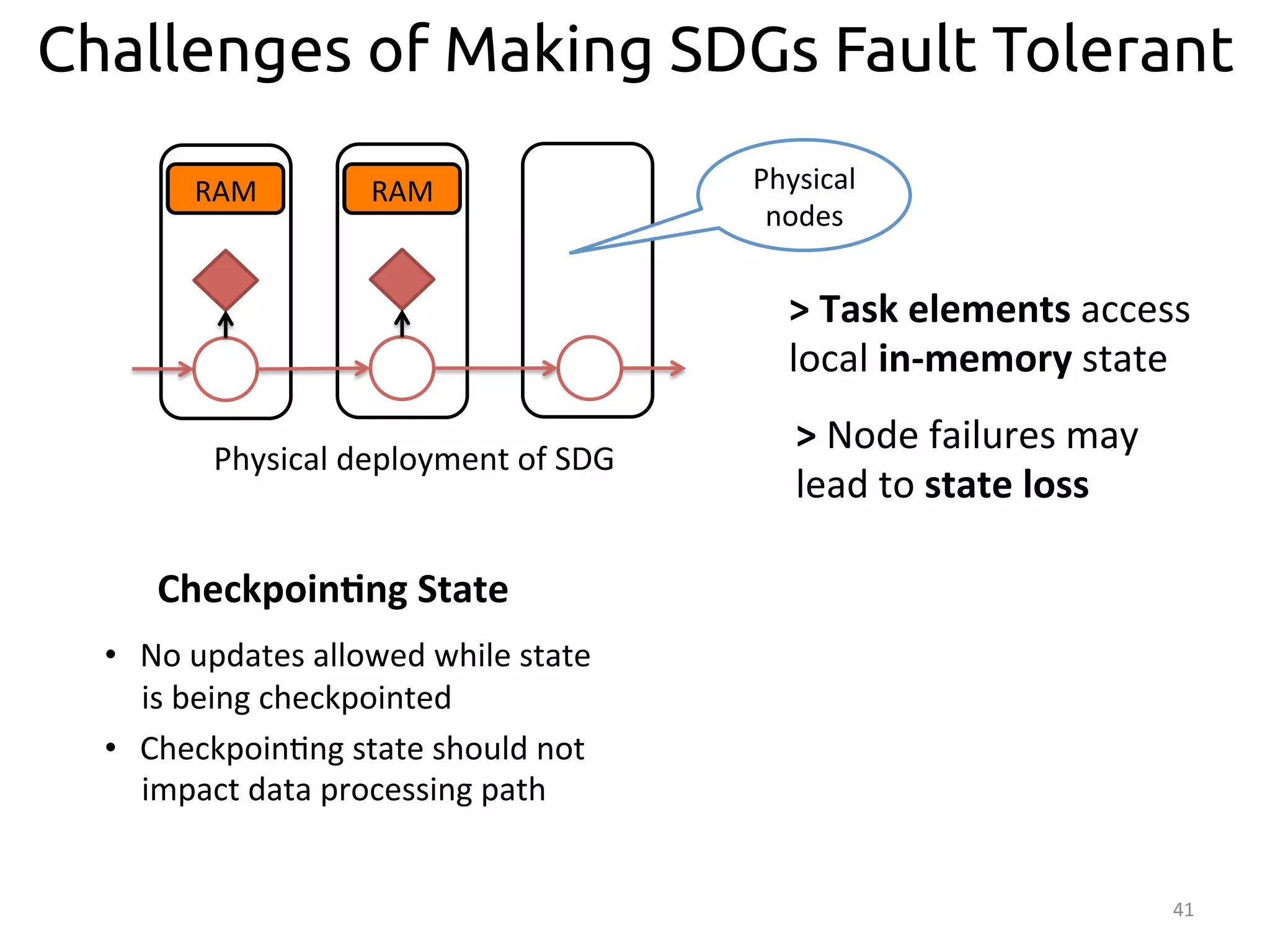
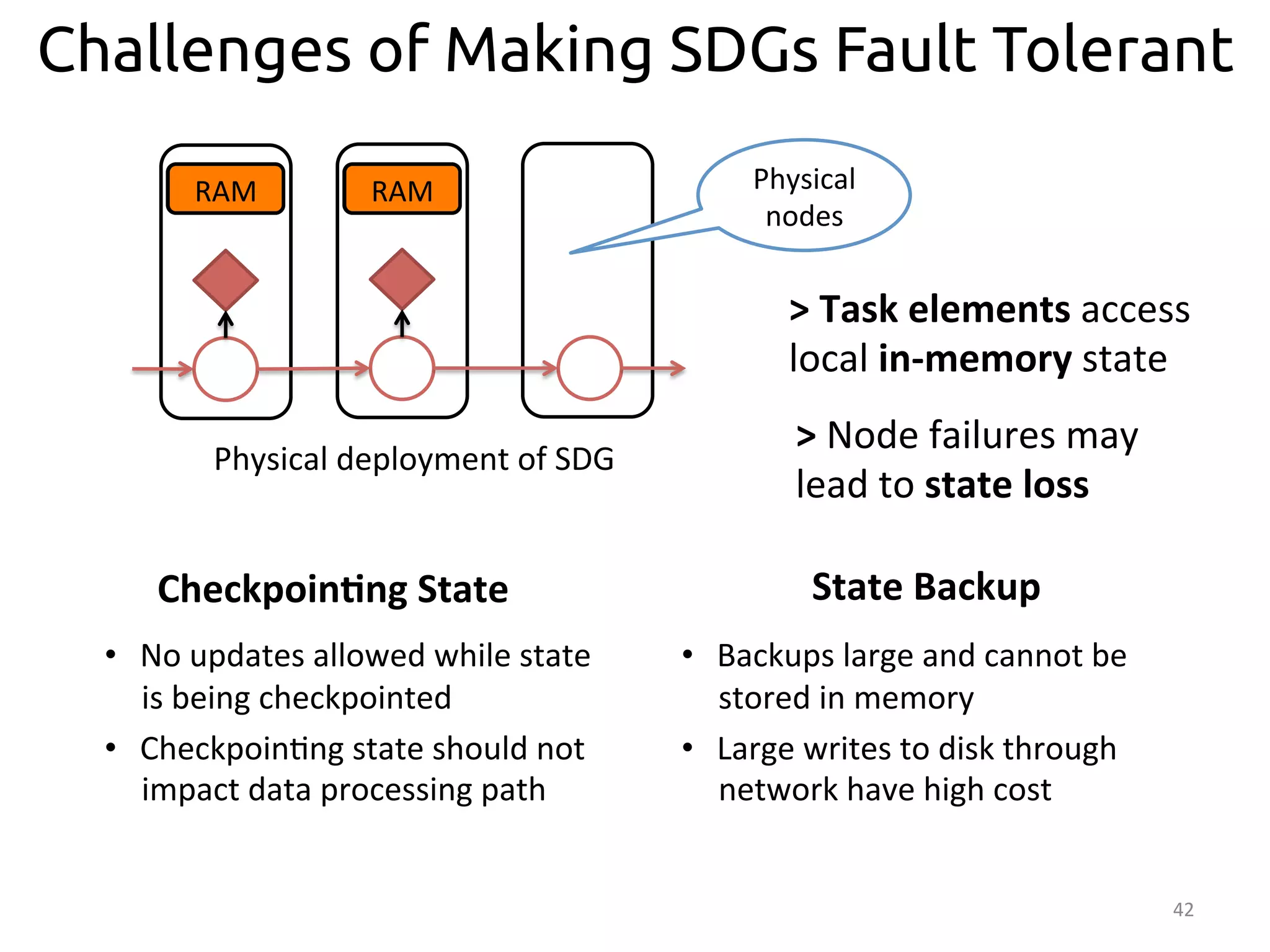

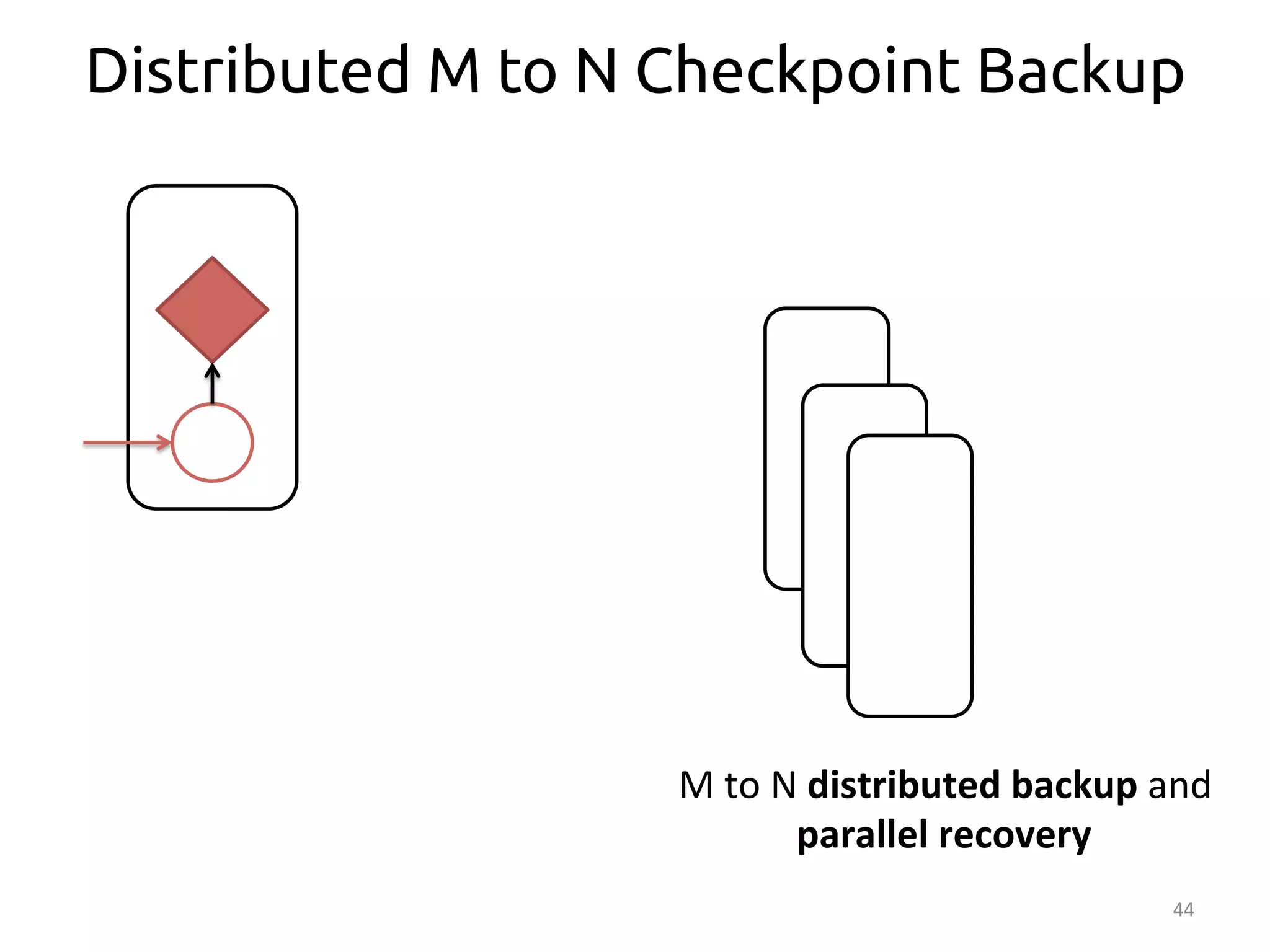
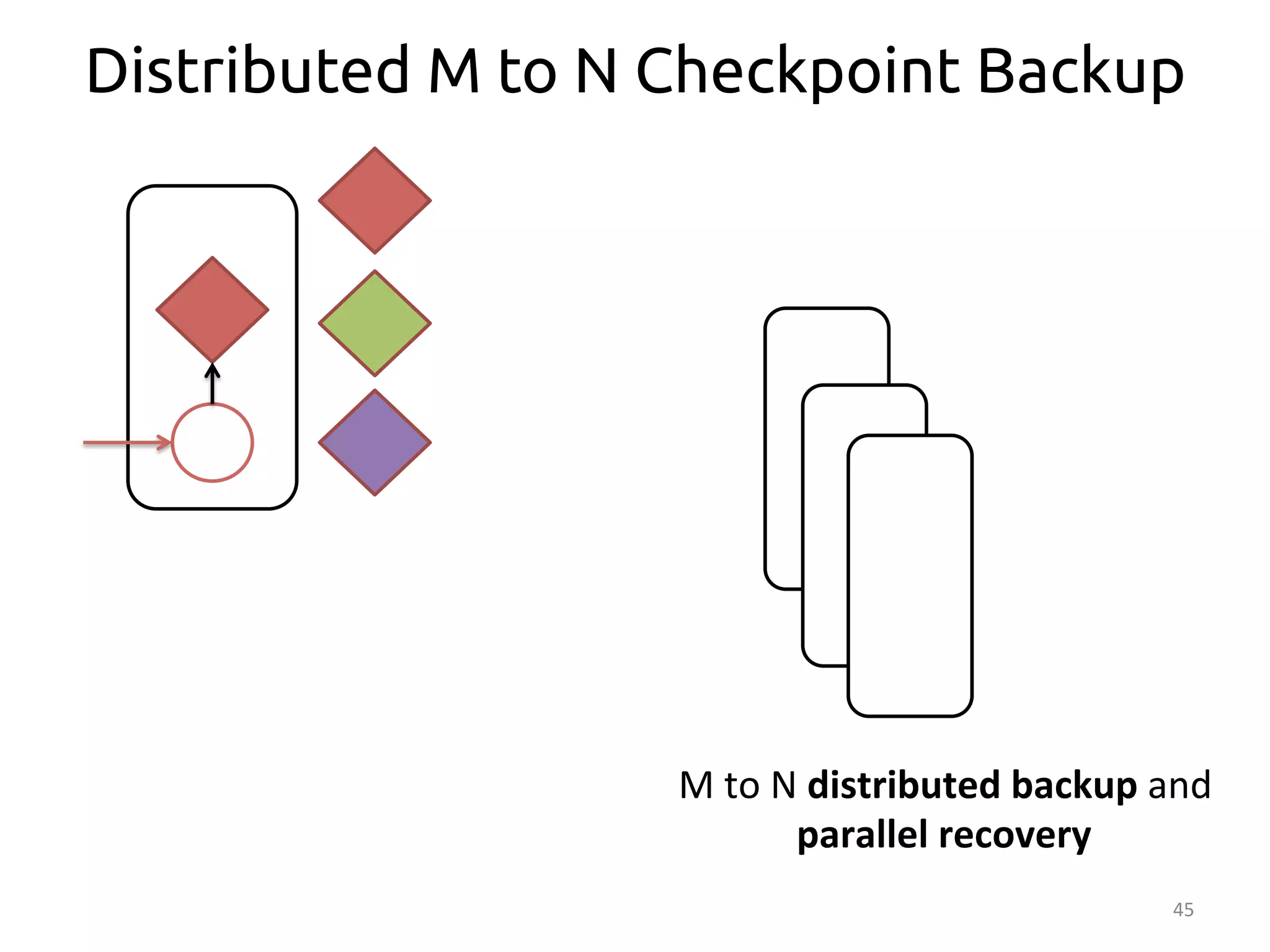
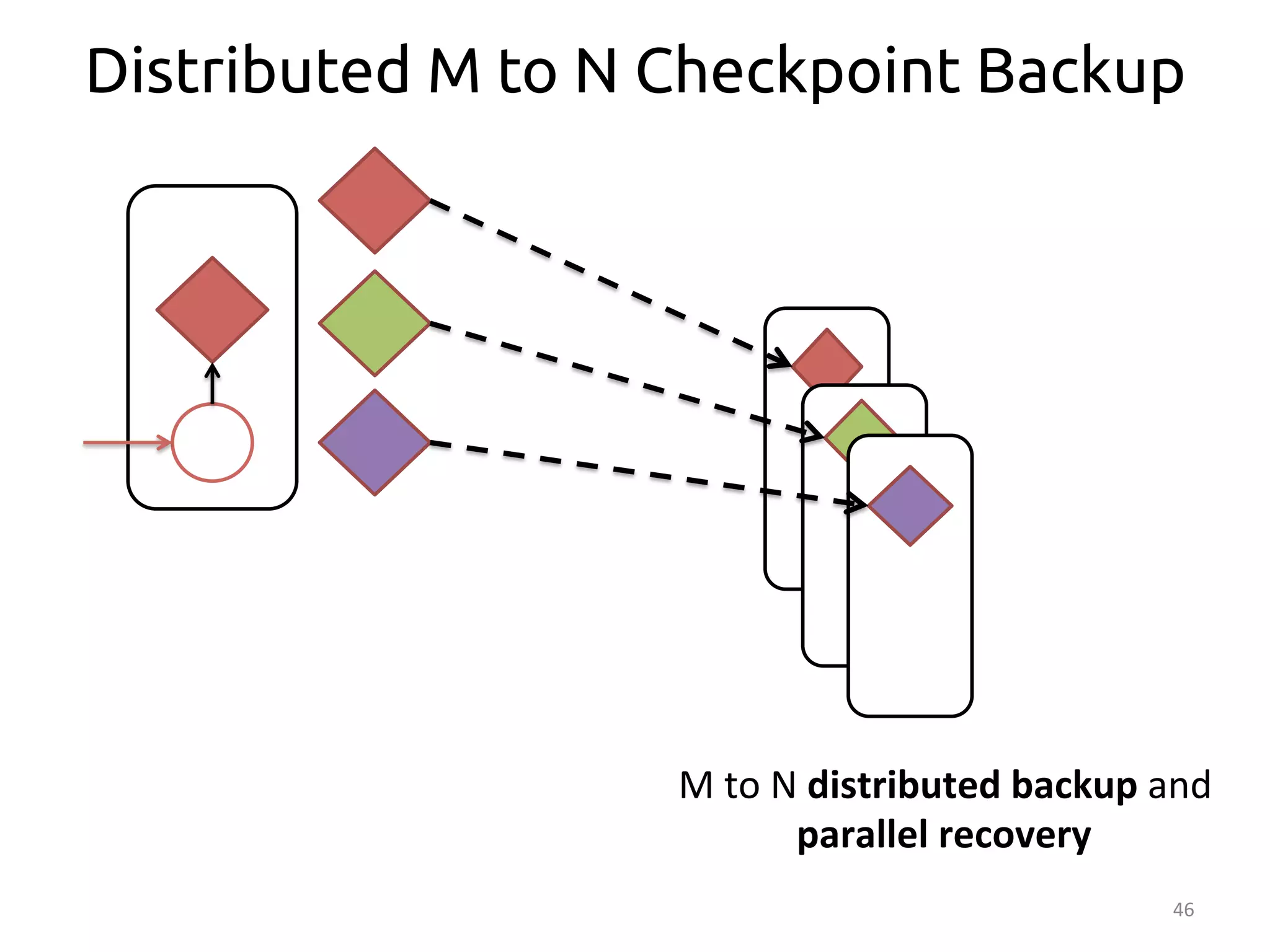
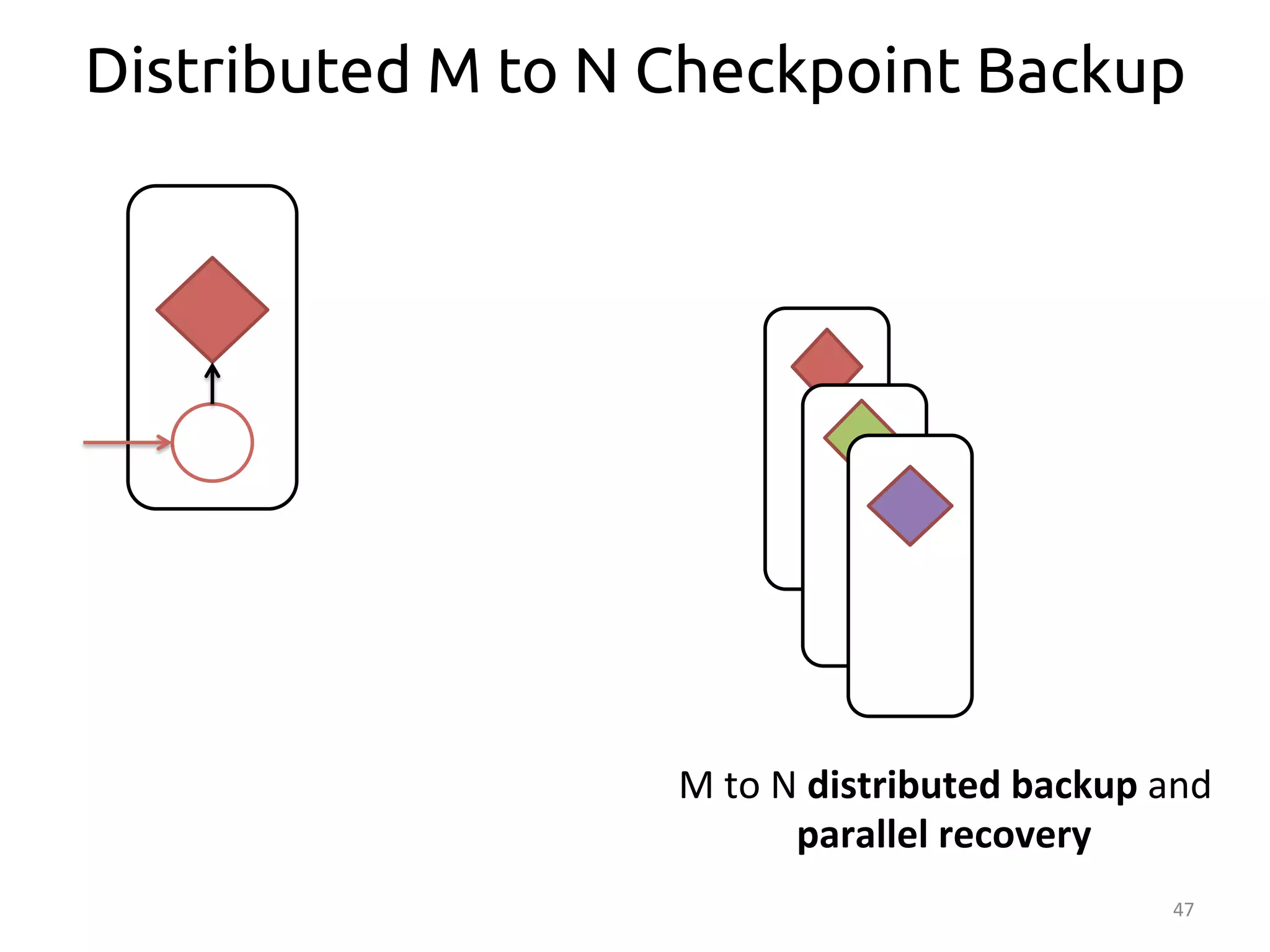
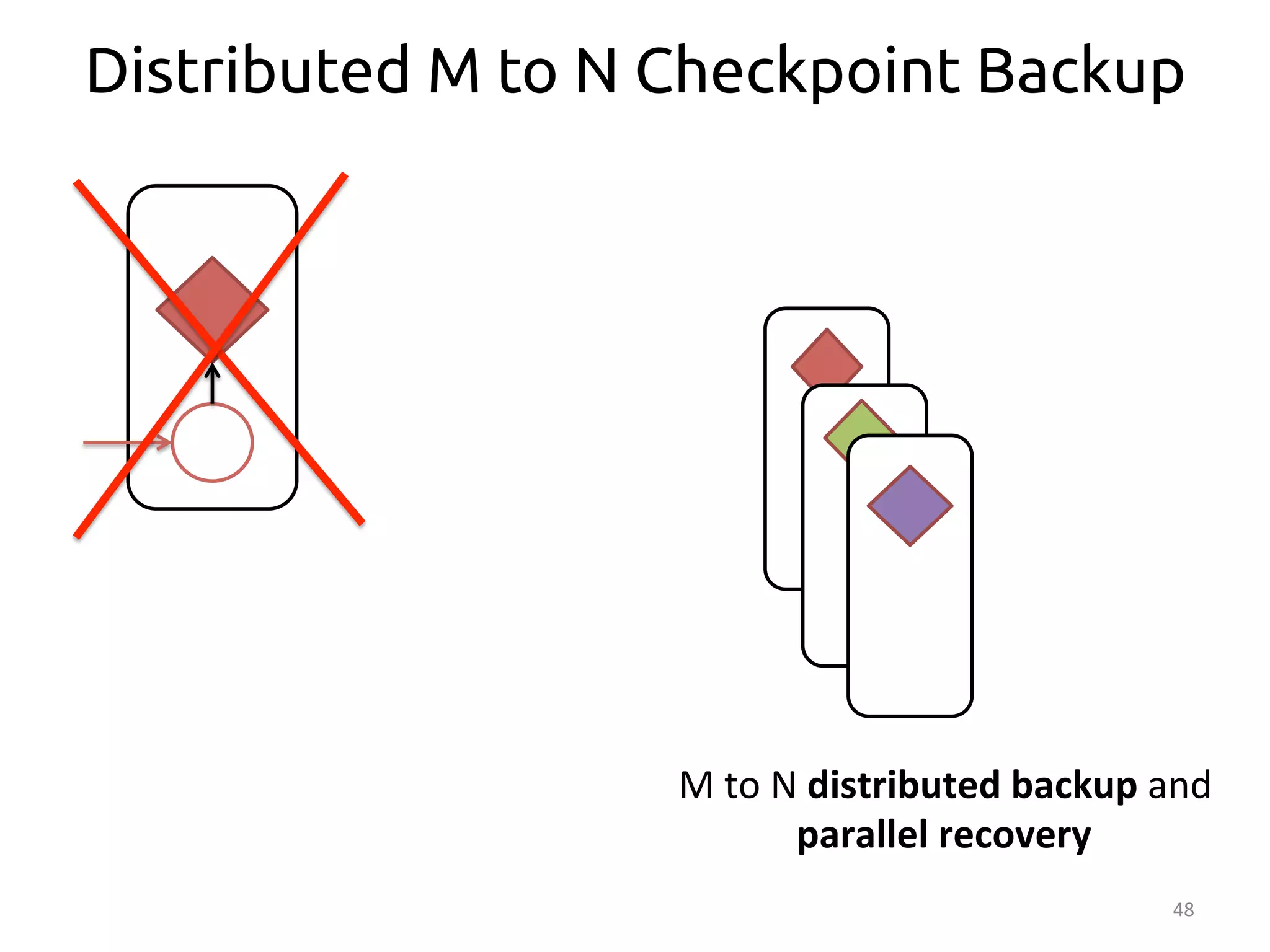
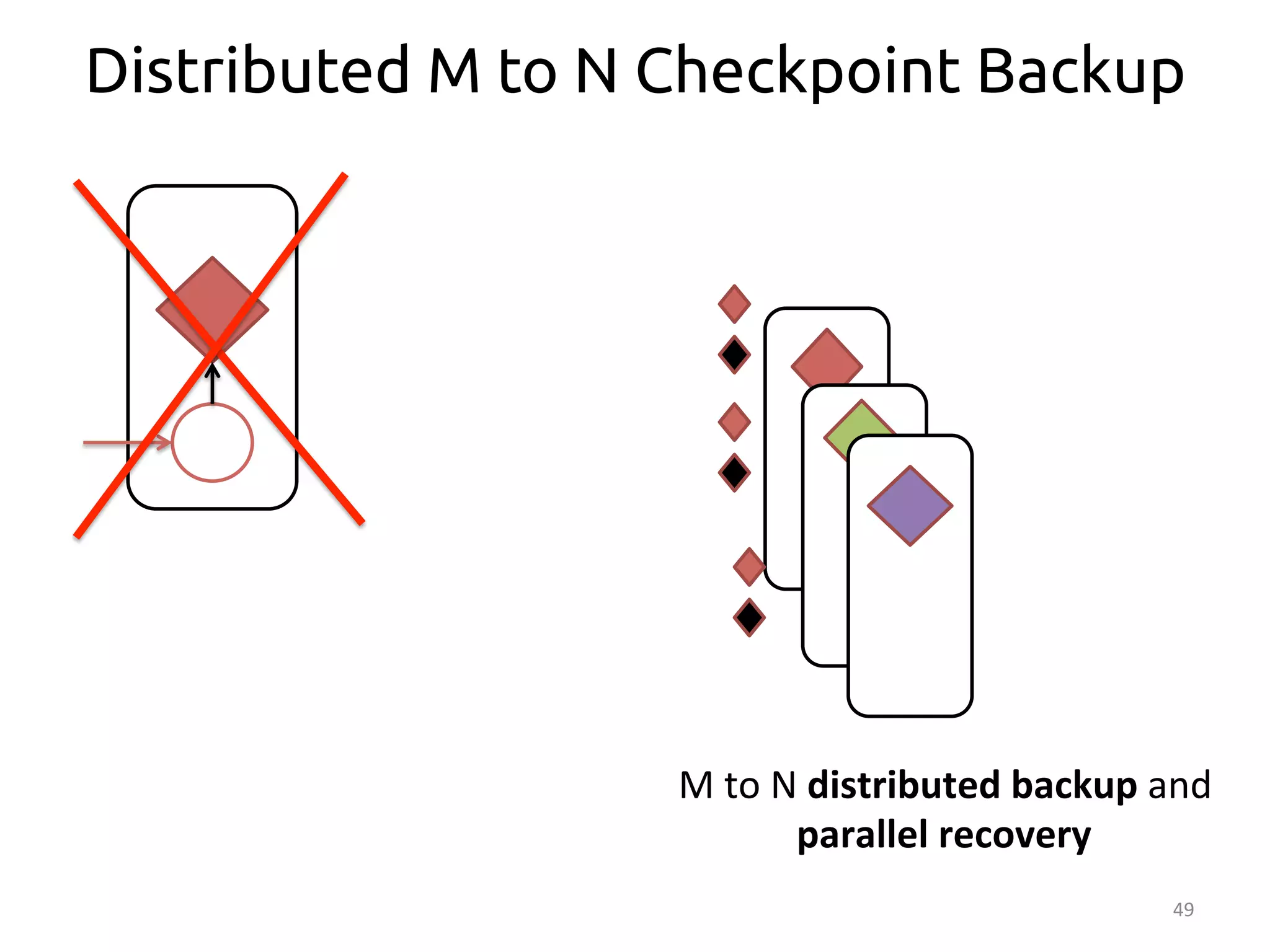
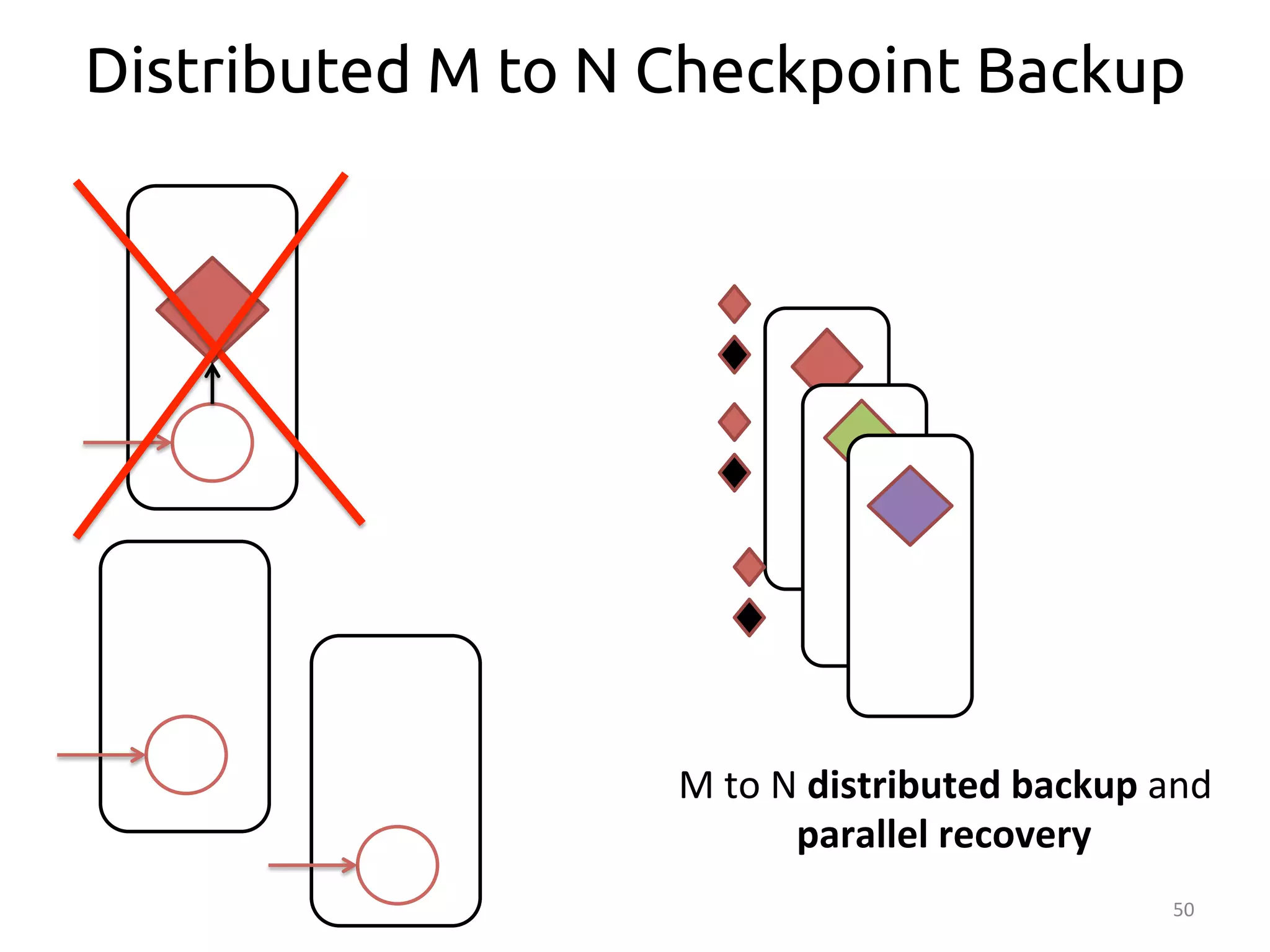
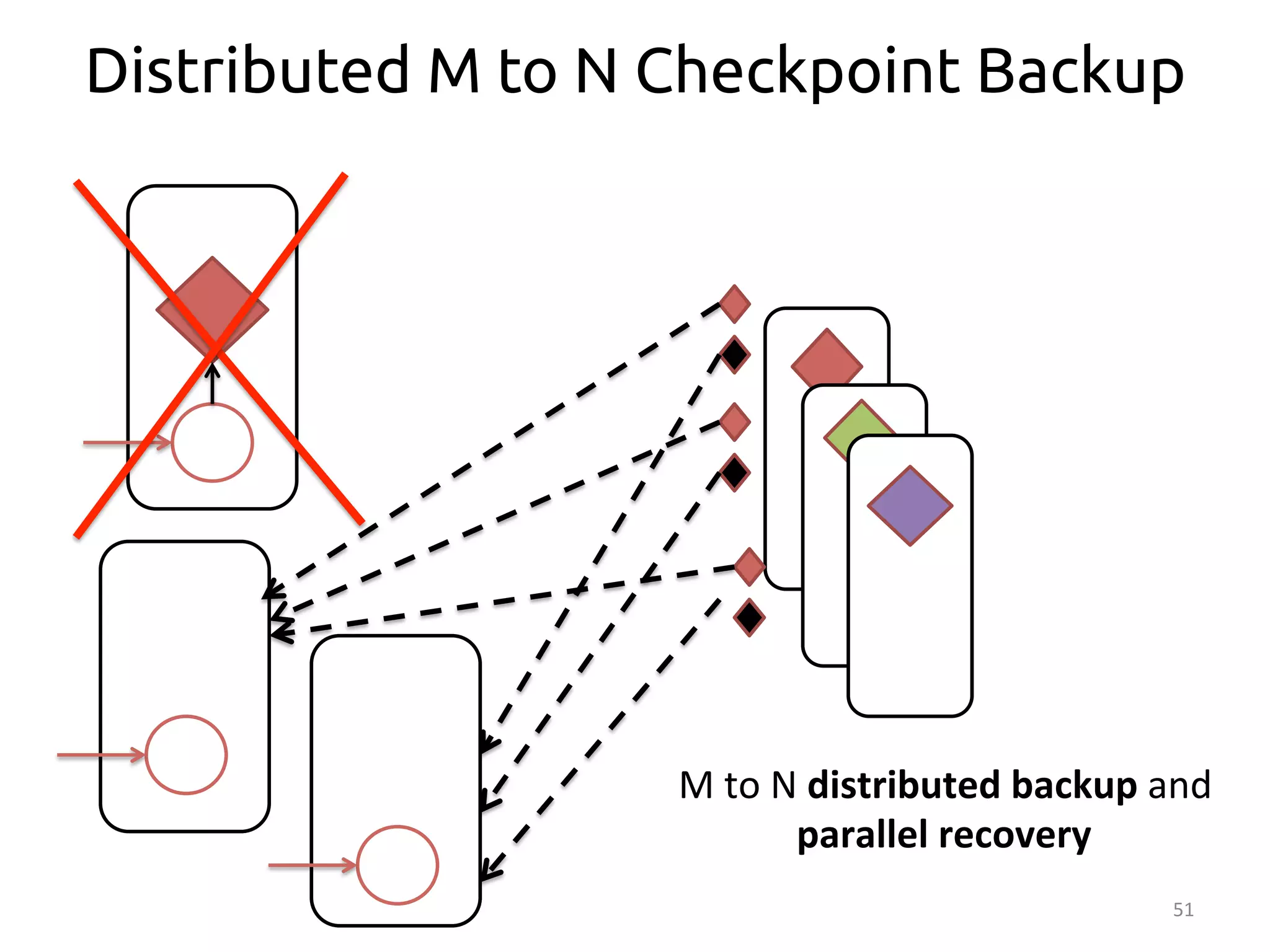
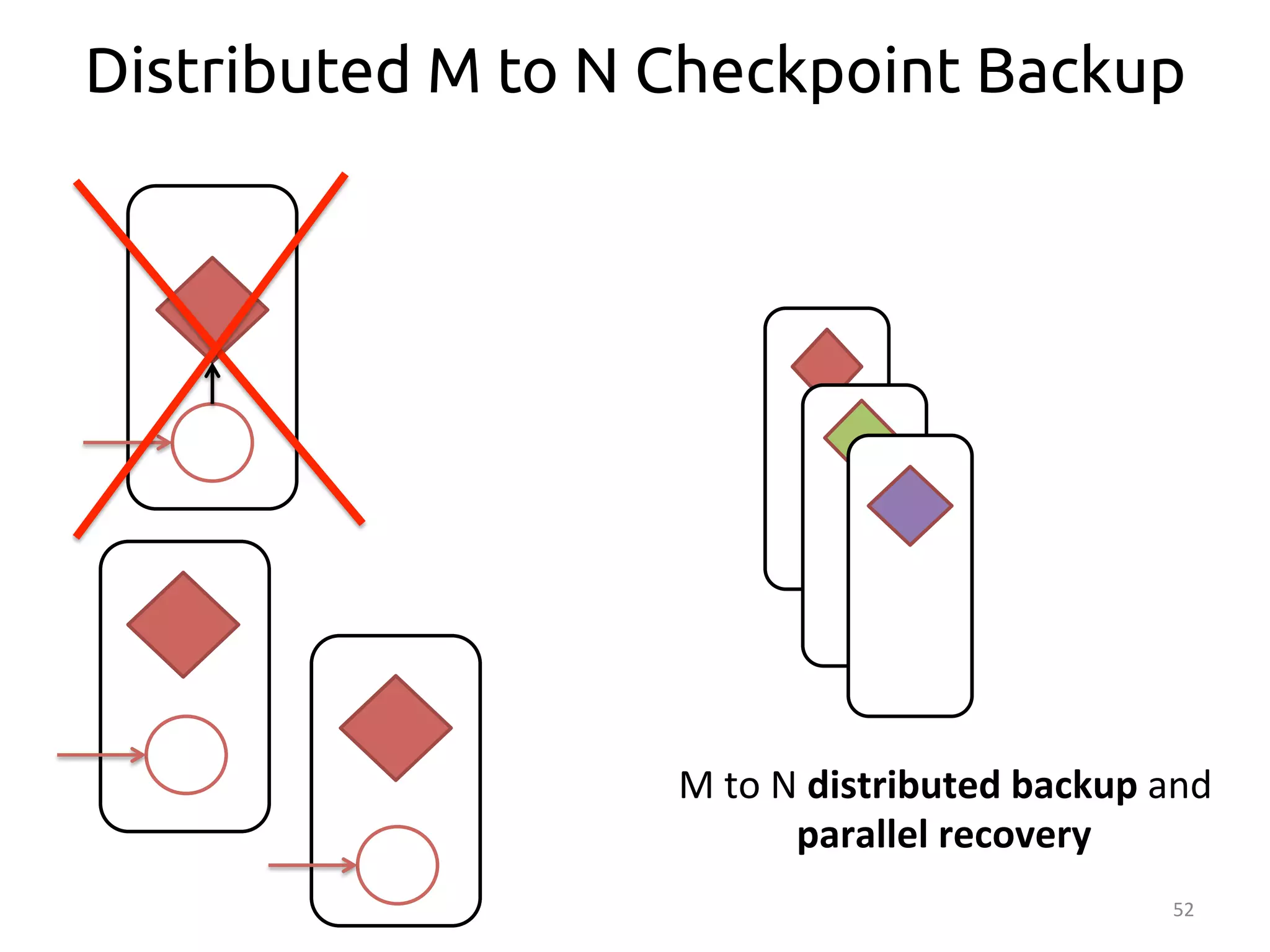

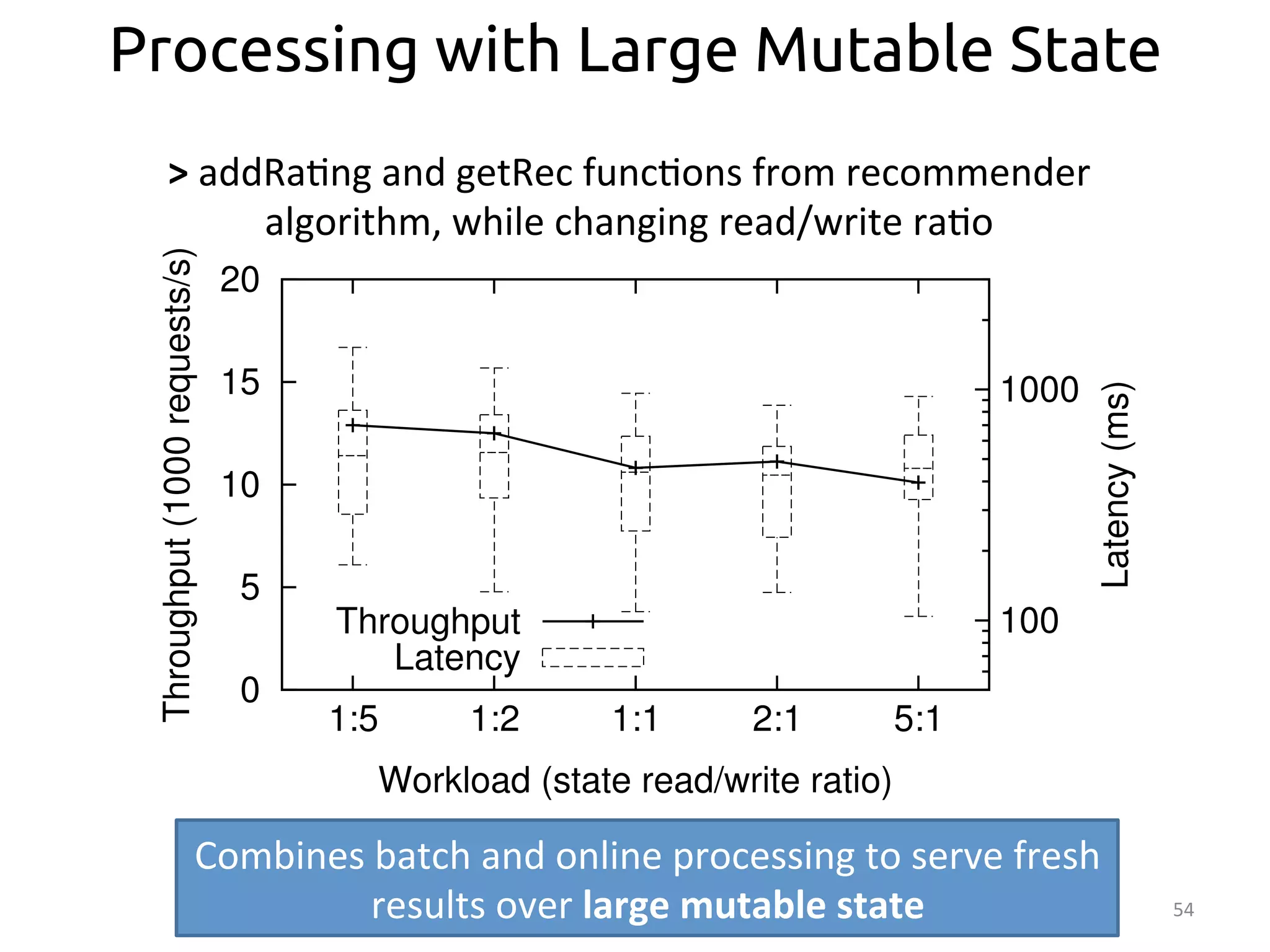

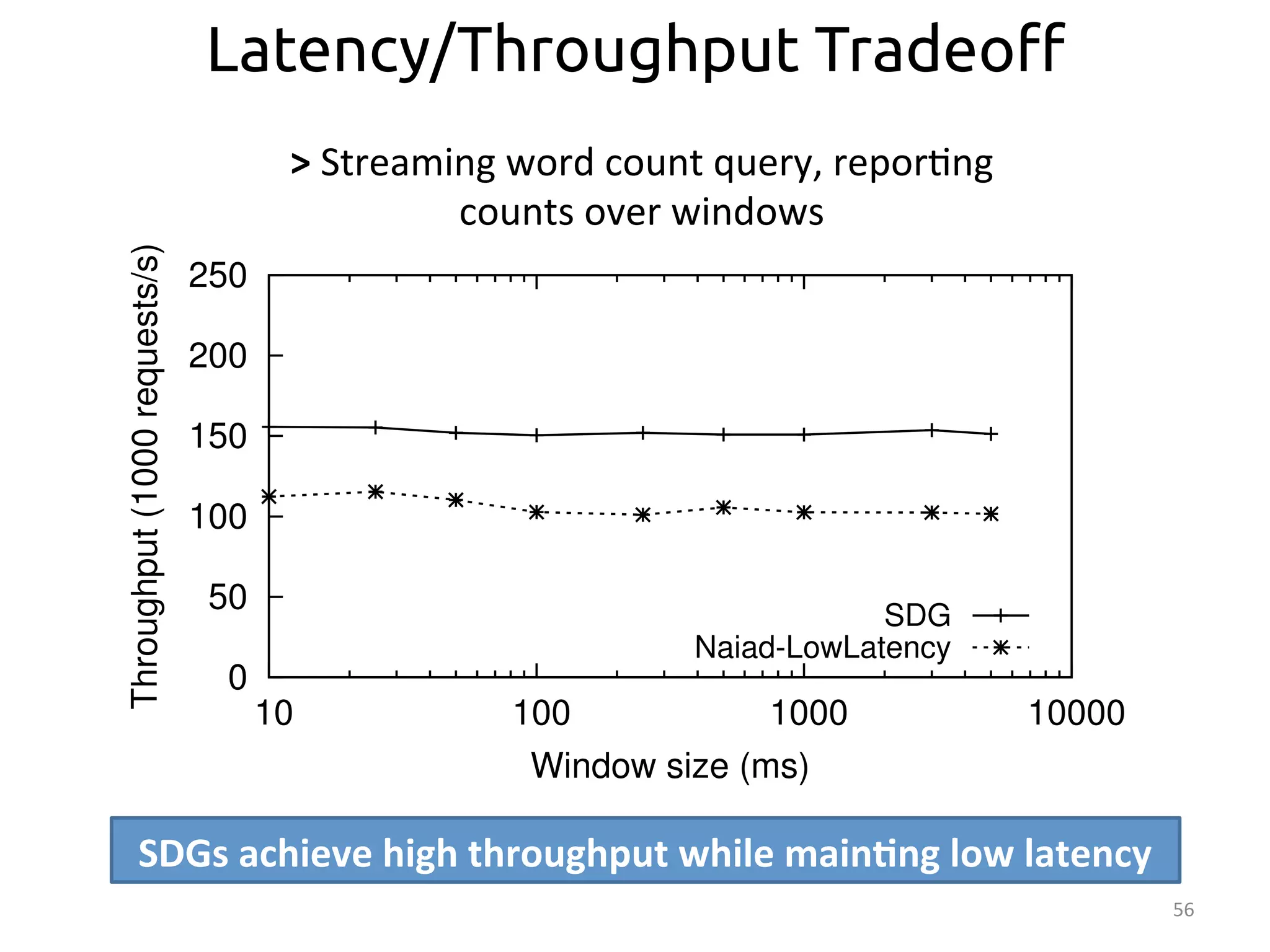
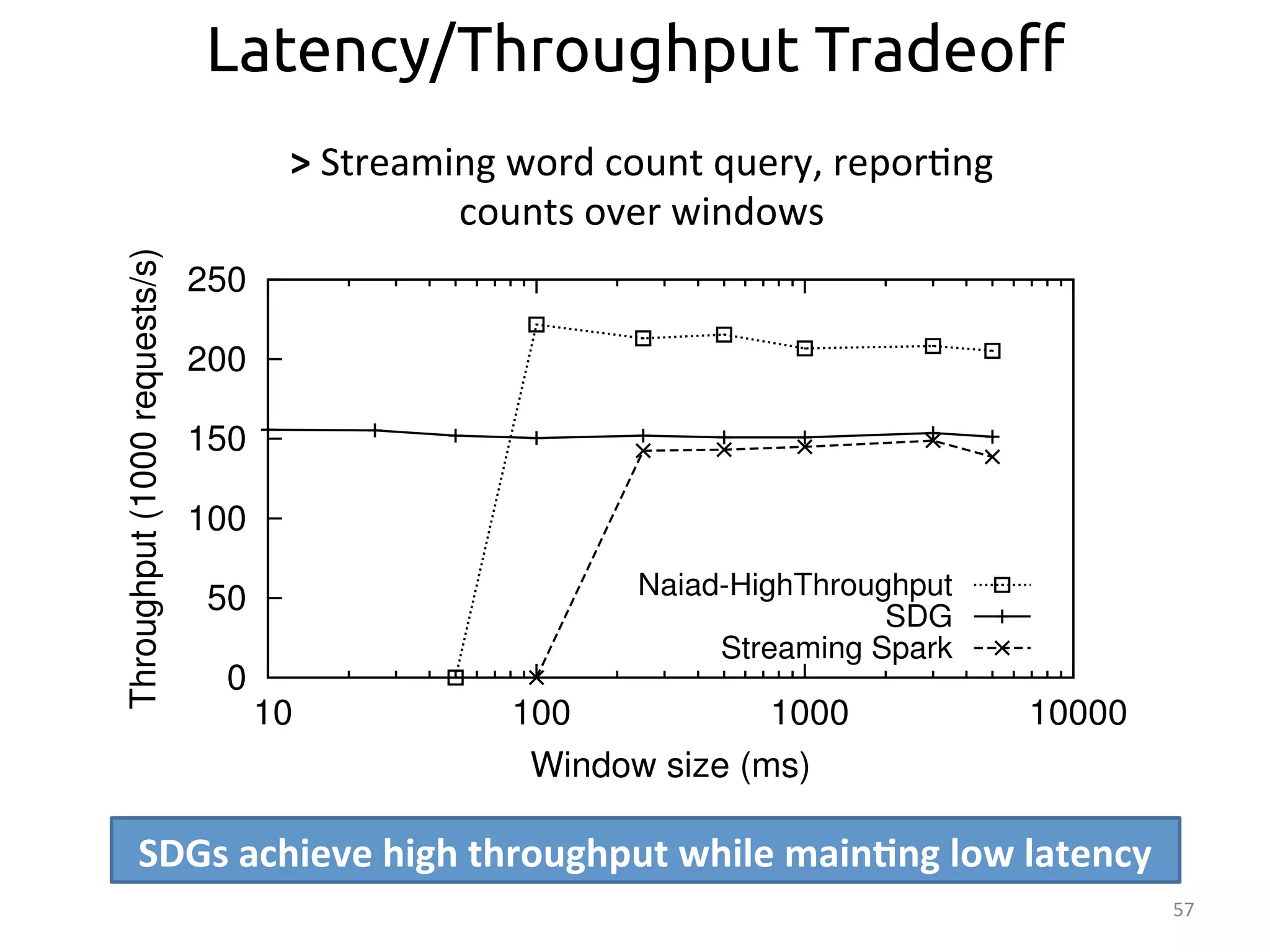
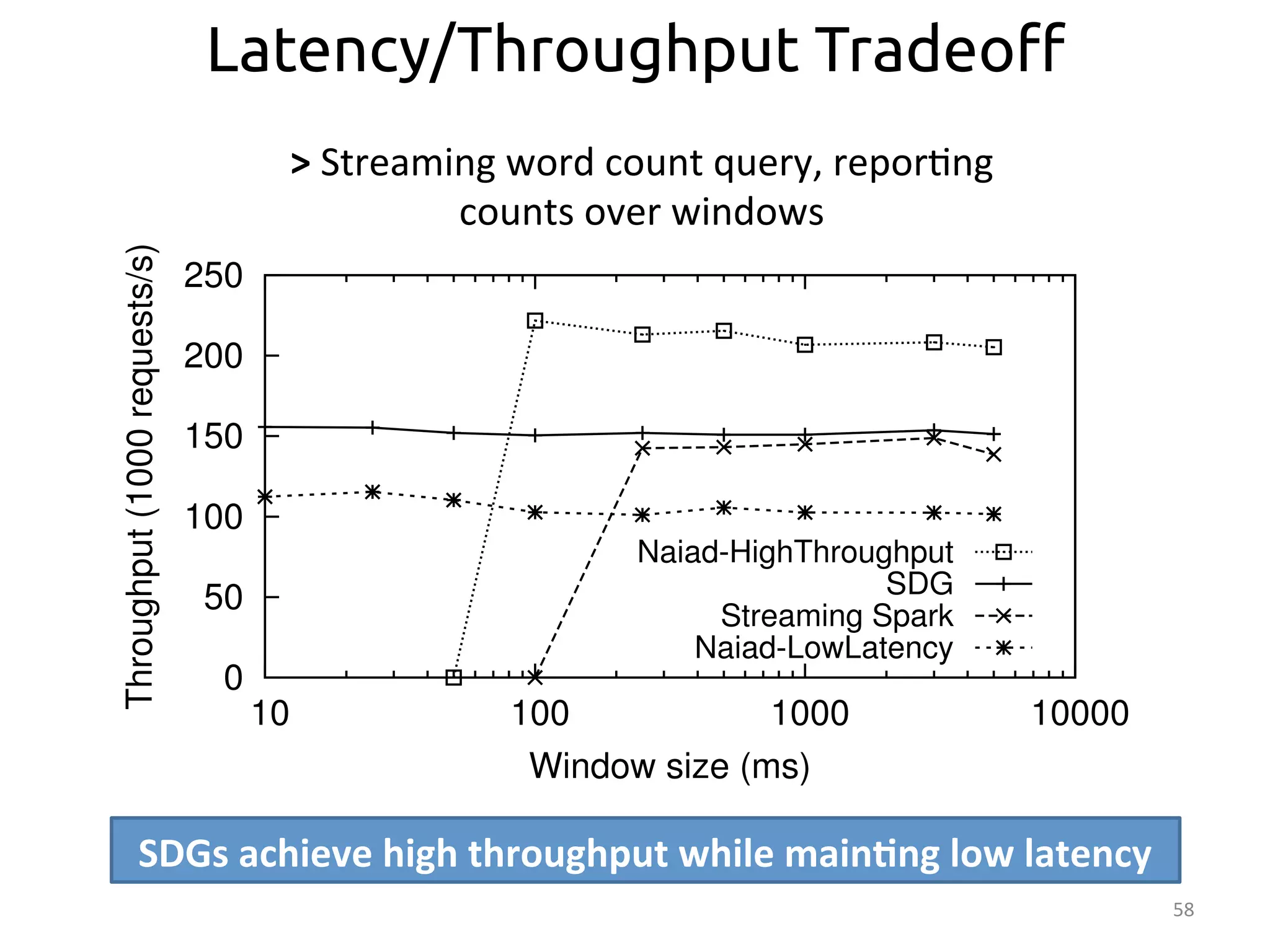



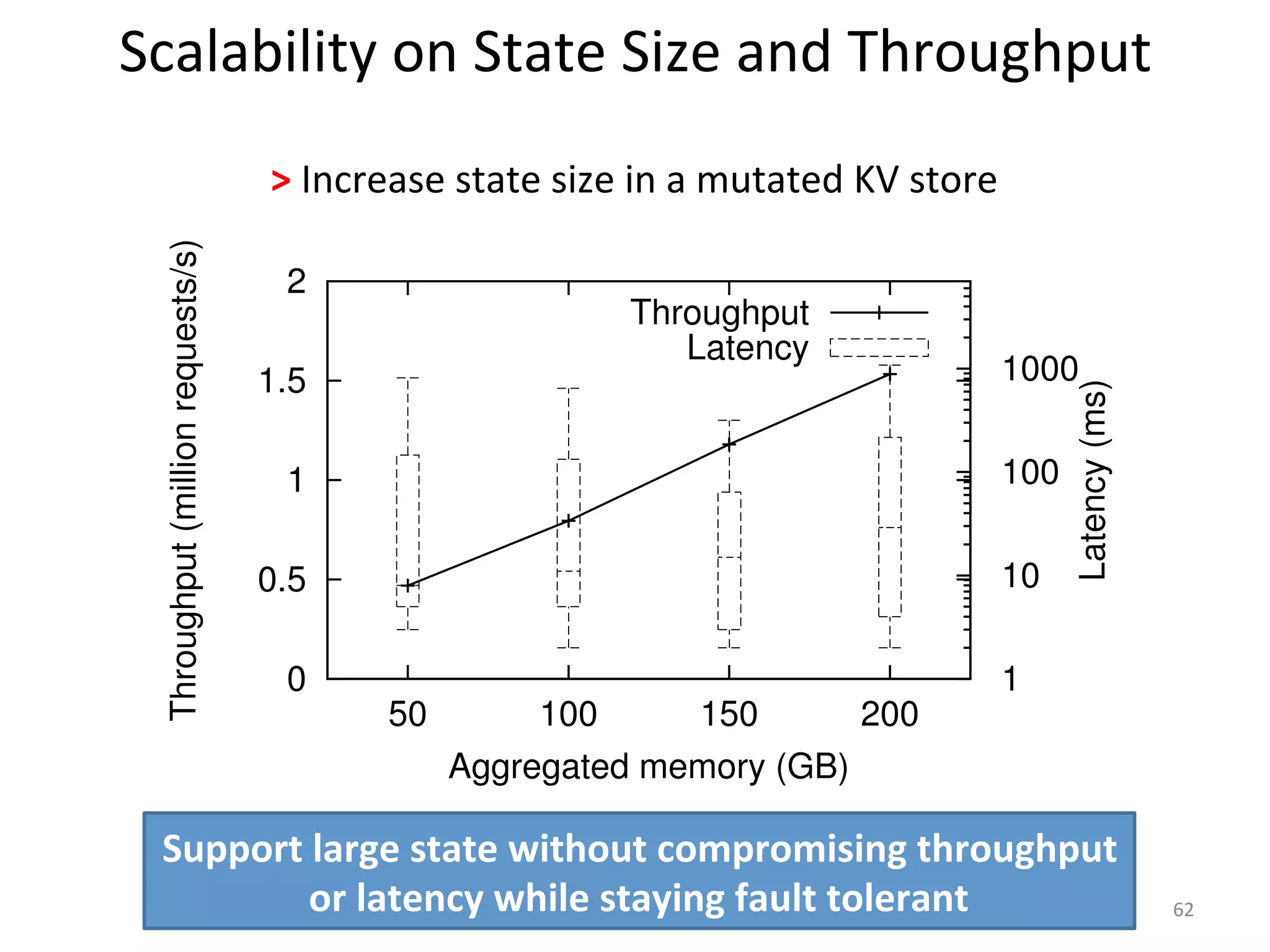
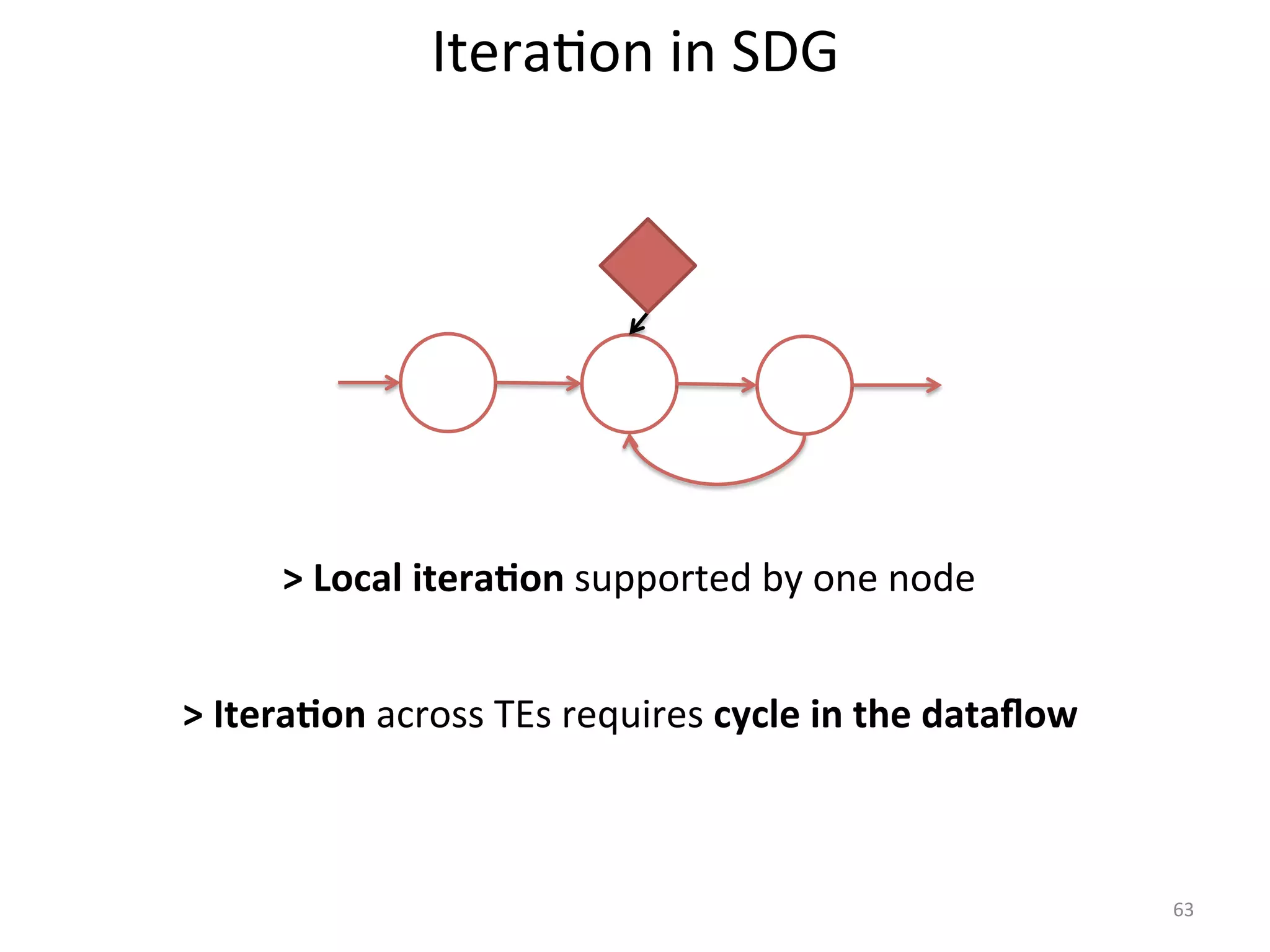

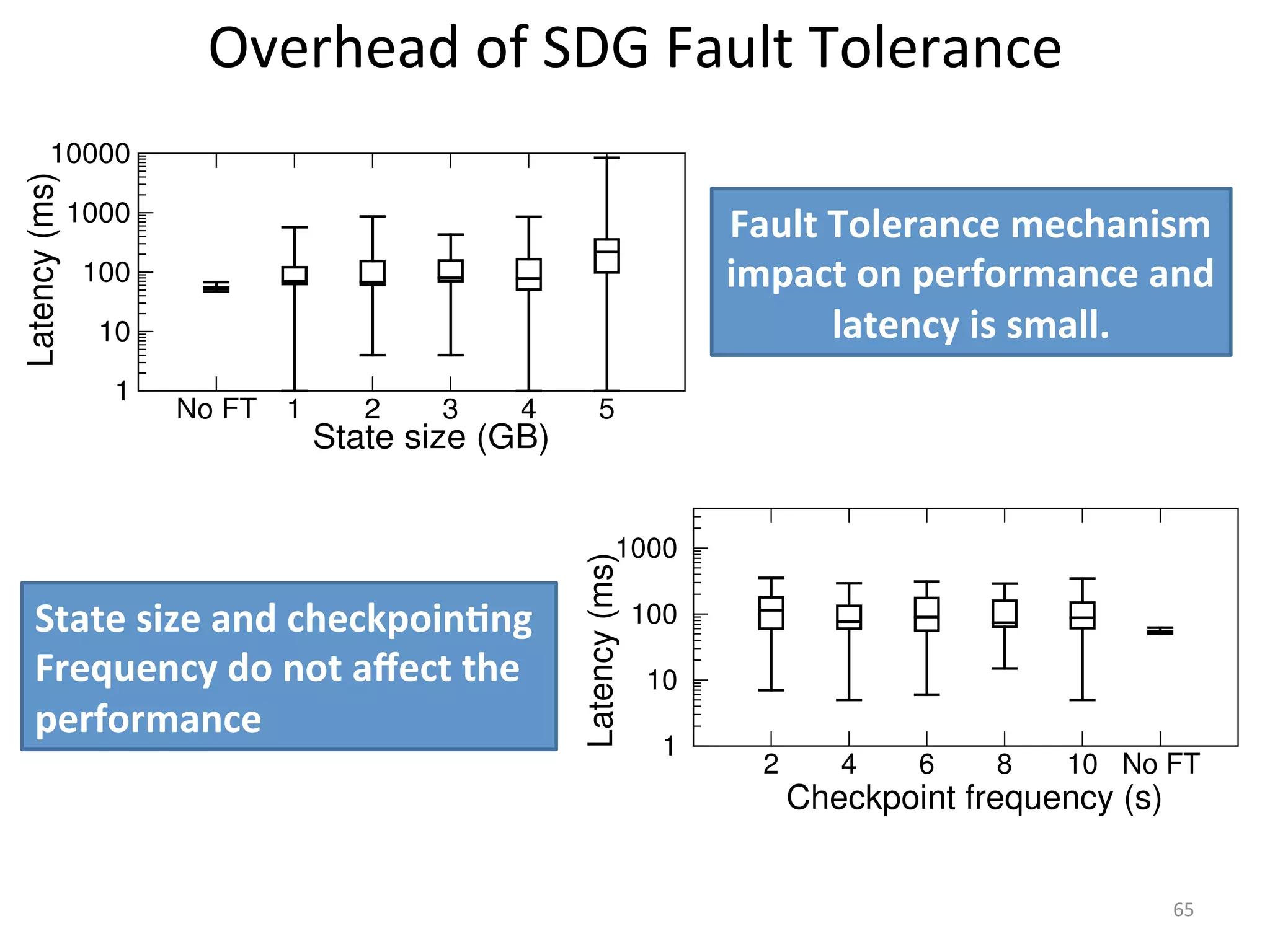
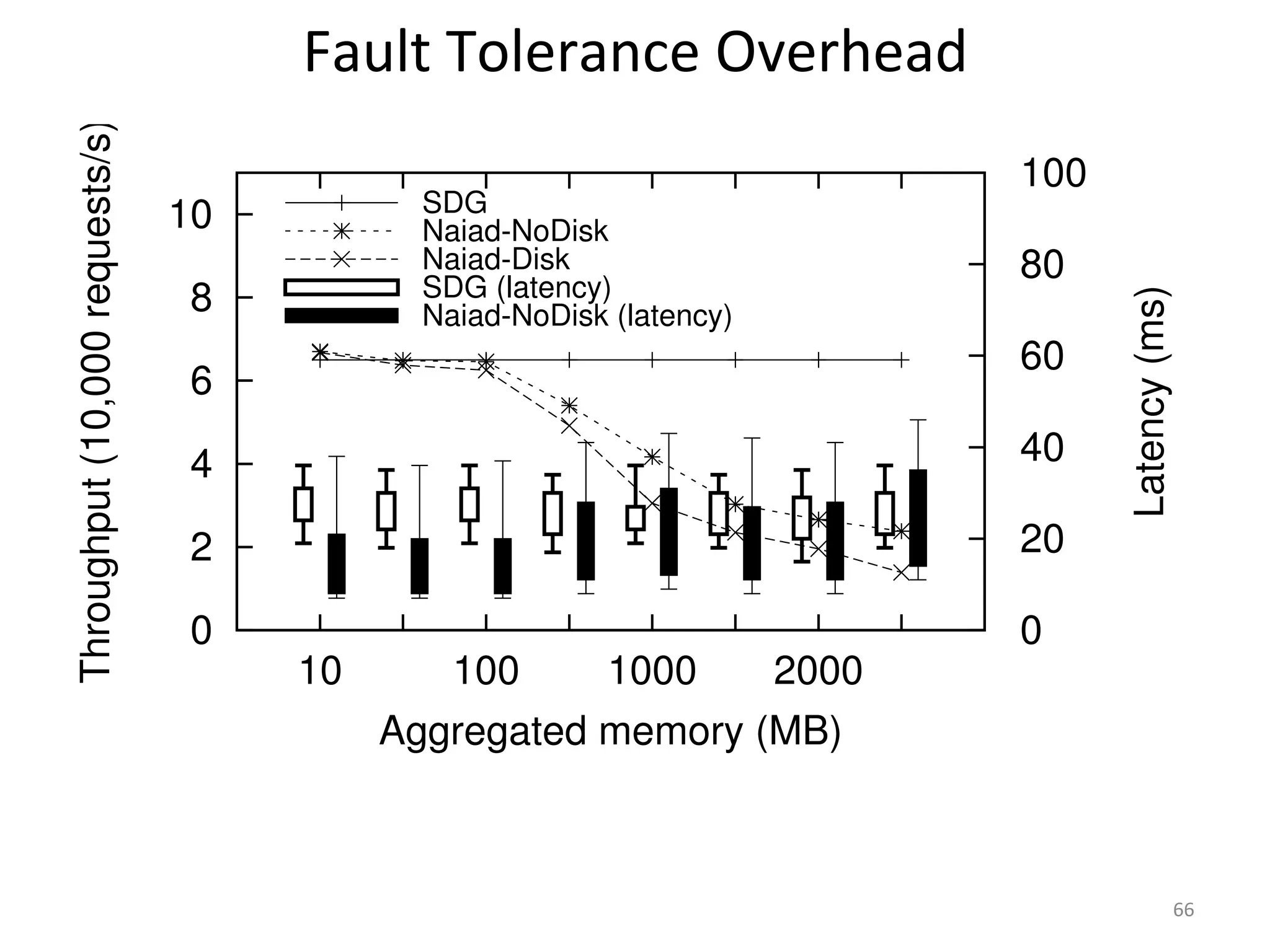
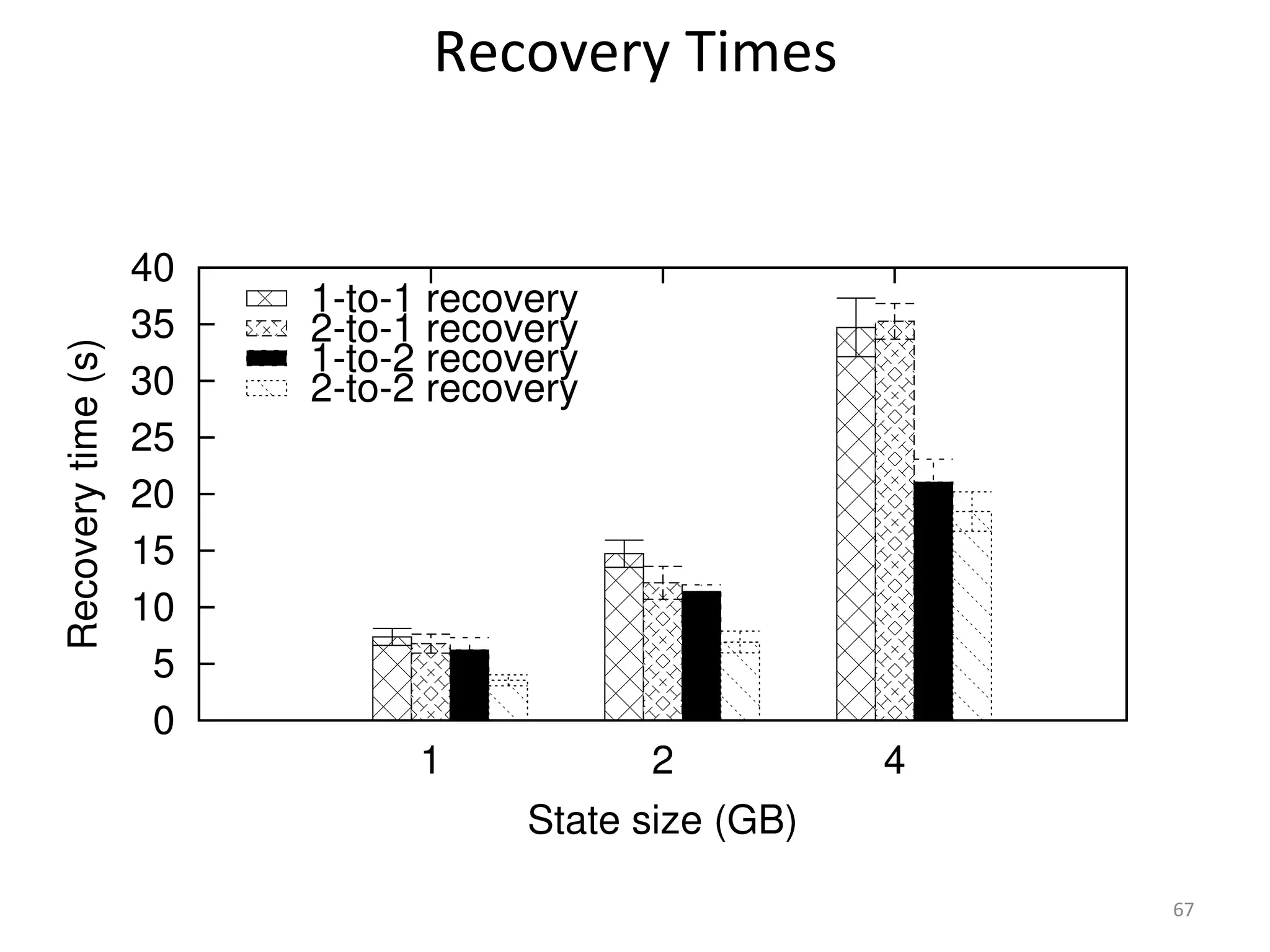
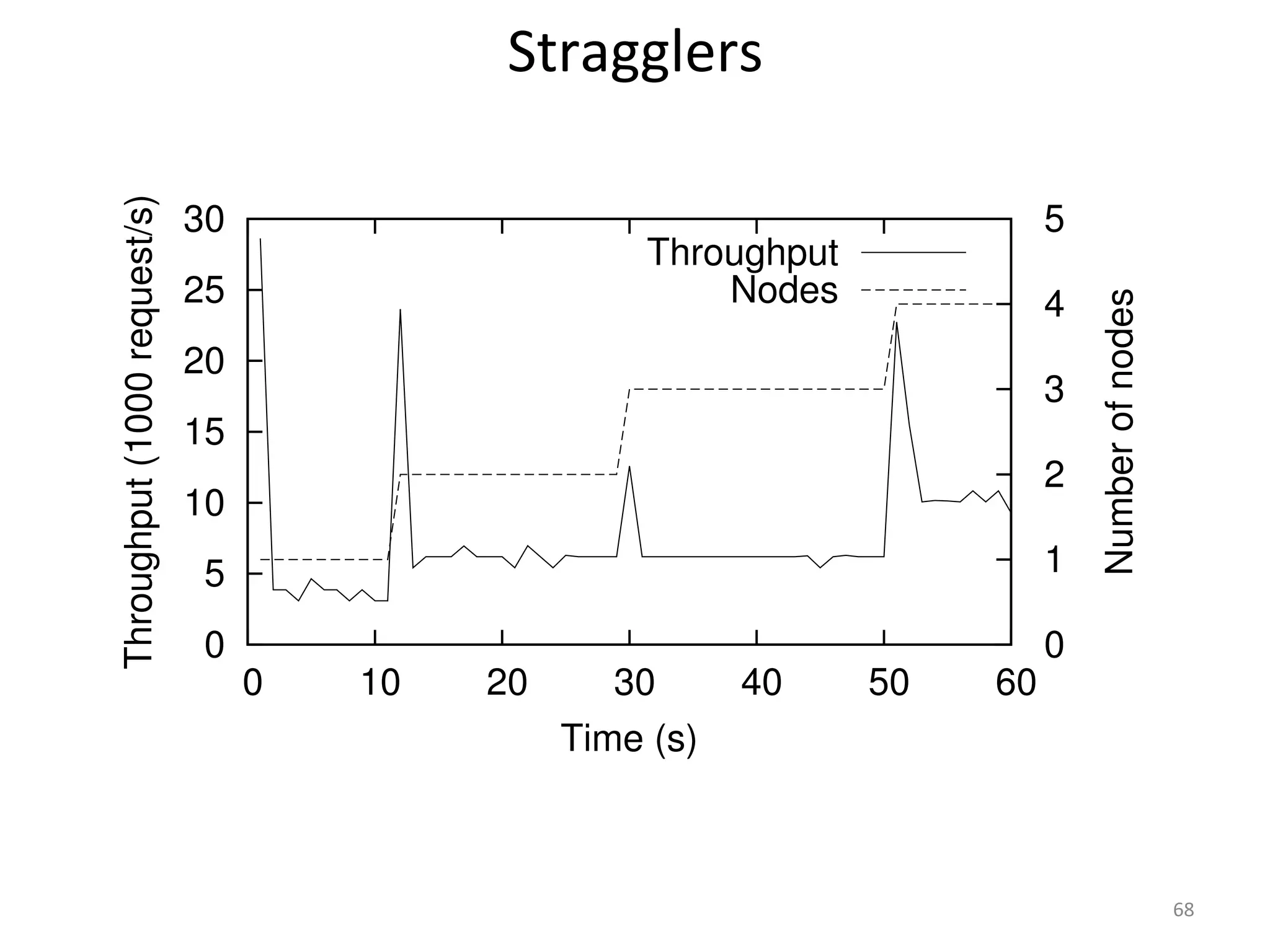
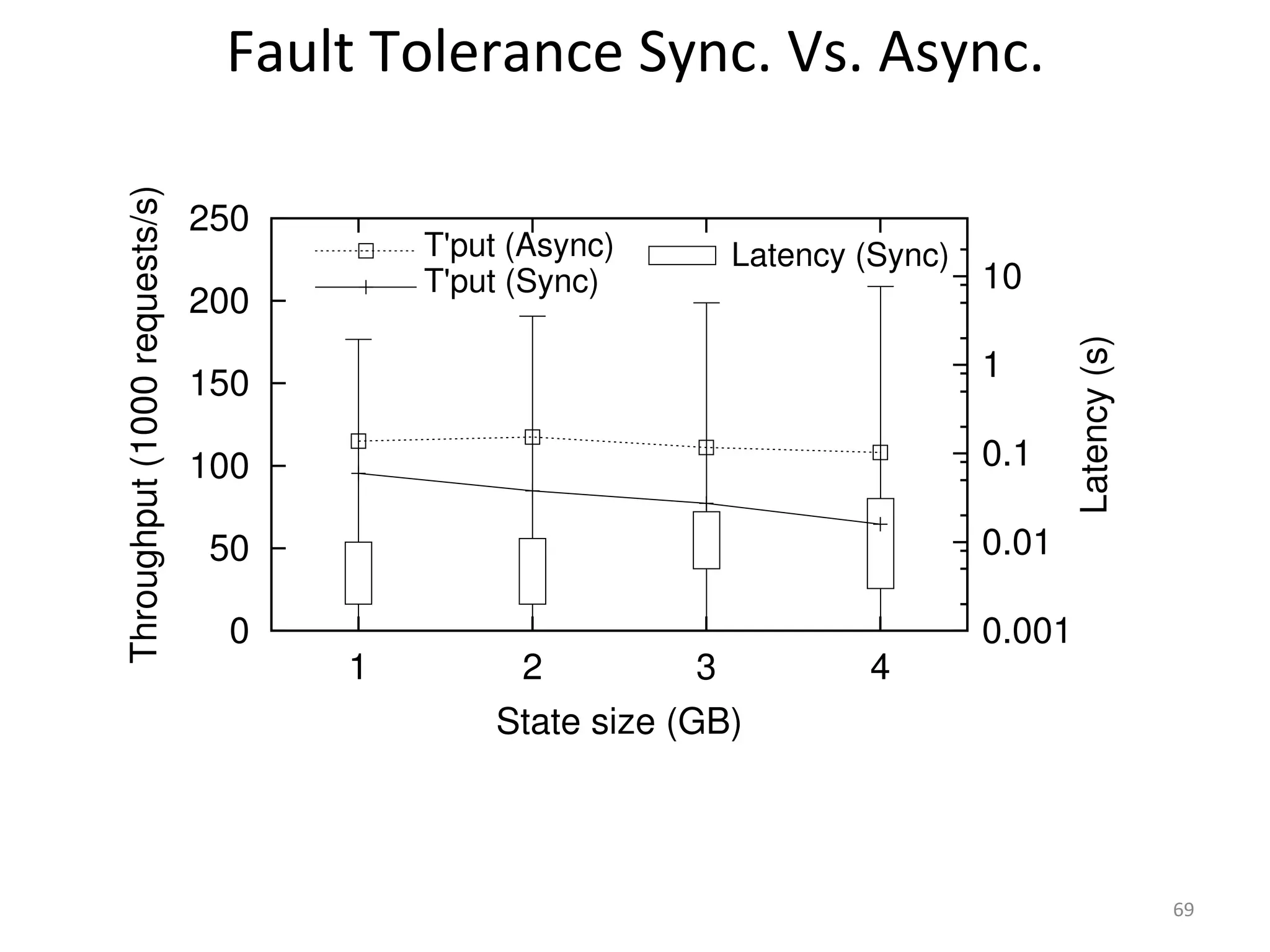
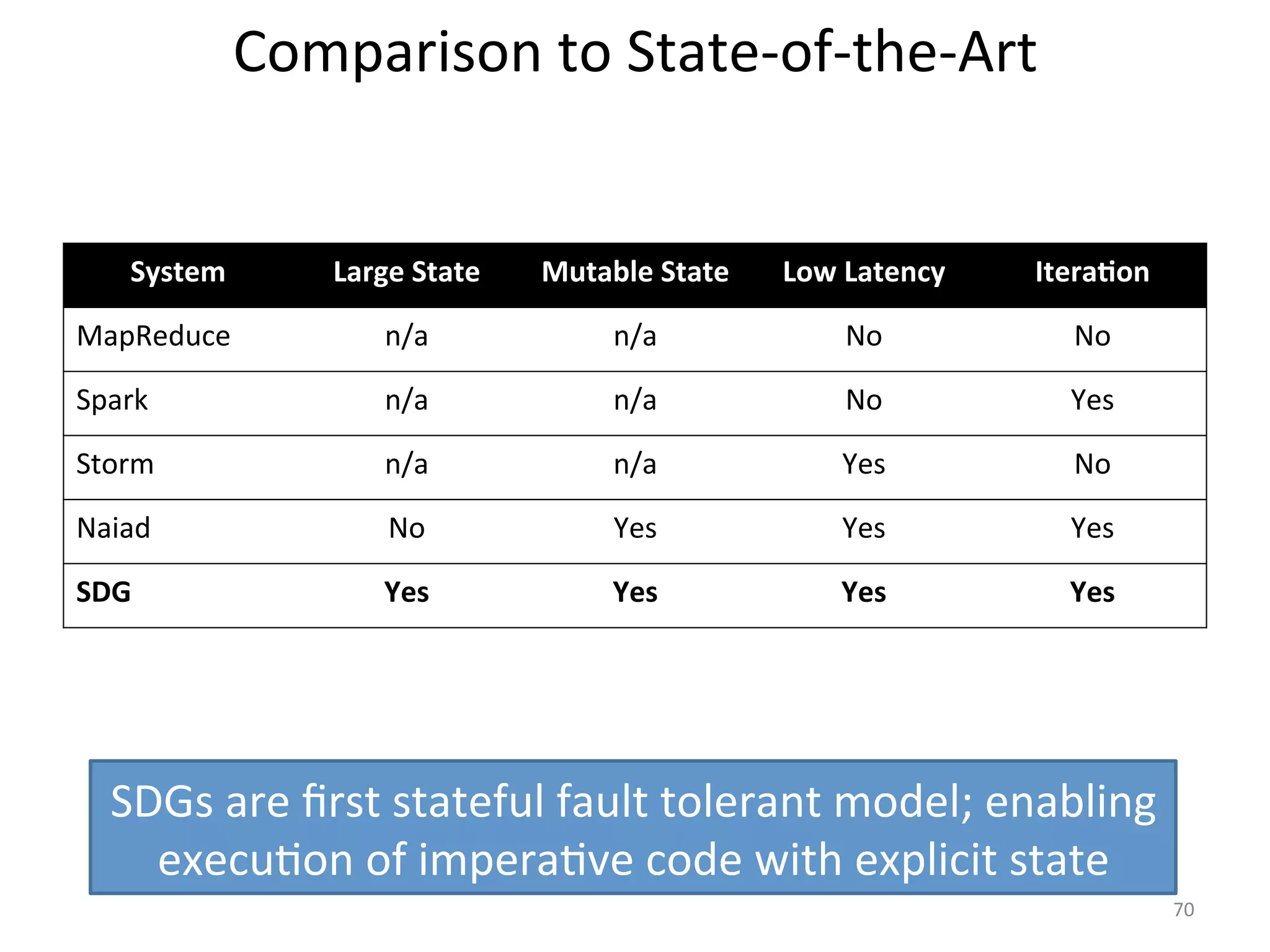
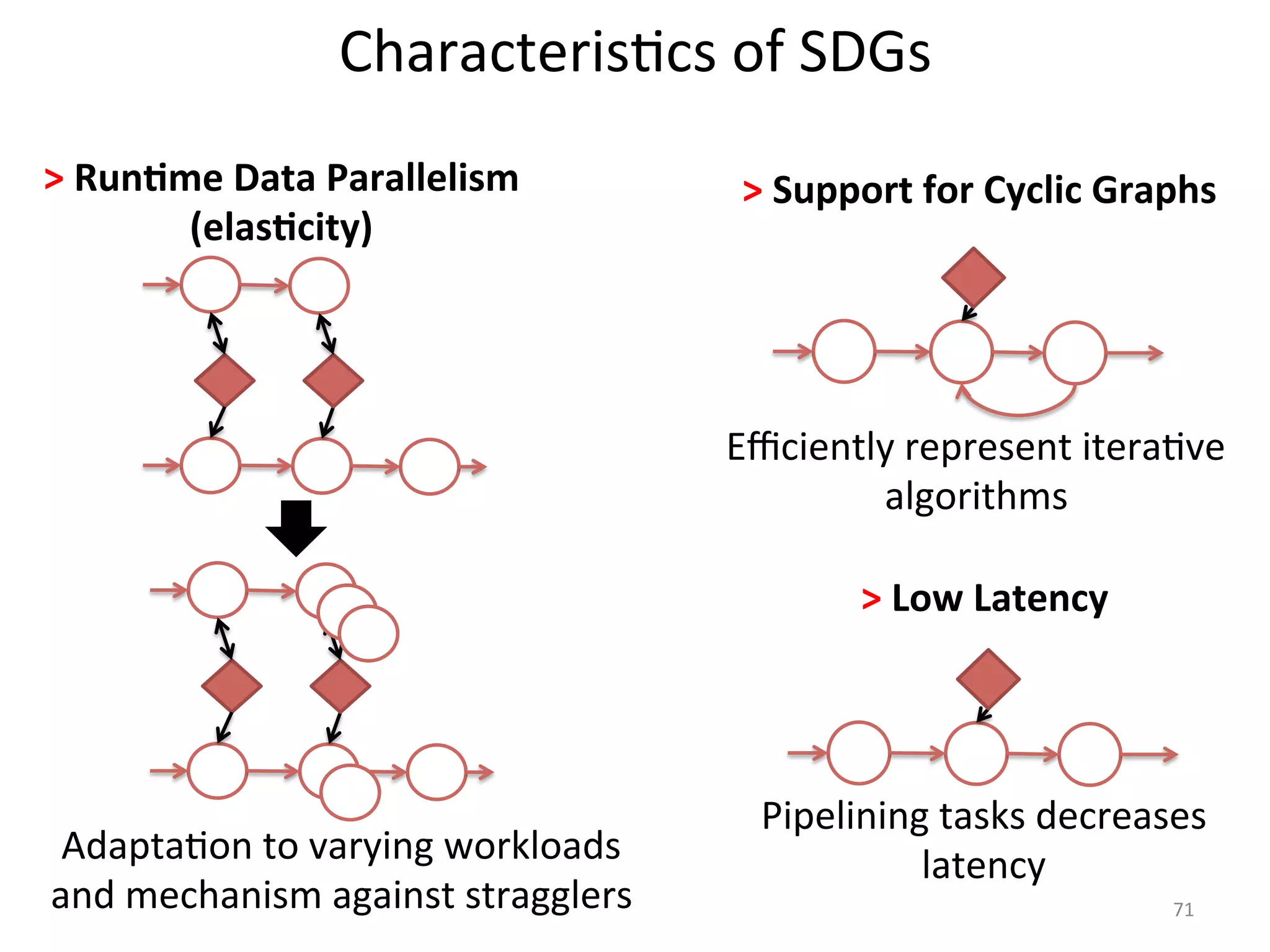



The document discusses the concept of stateful dataflow graphs (SDGs) that enable the handling of distributed mutable state in big data applications. It emphasizes the democratization of data analysis, allowing various users beyond traditional developers to engage with data, while also addressing the challenges of ensuring fault tolerance and performance in big data processing. The techniques presented aim to allow Java programs to maintain mutable state with the advantages of distributed dataflow systems.






















































































