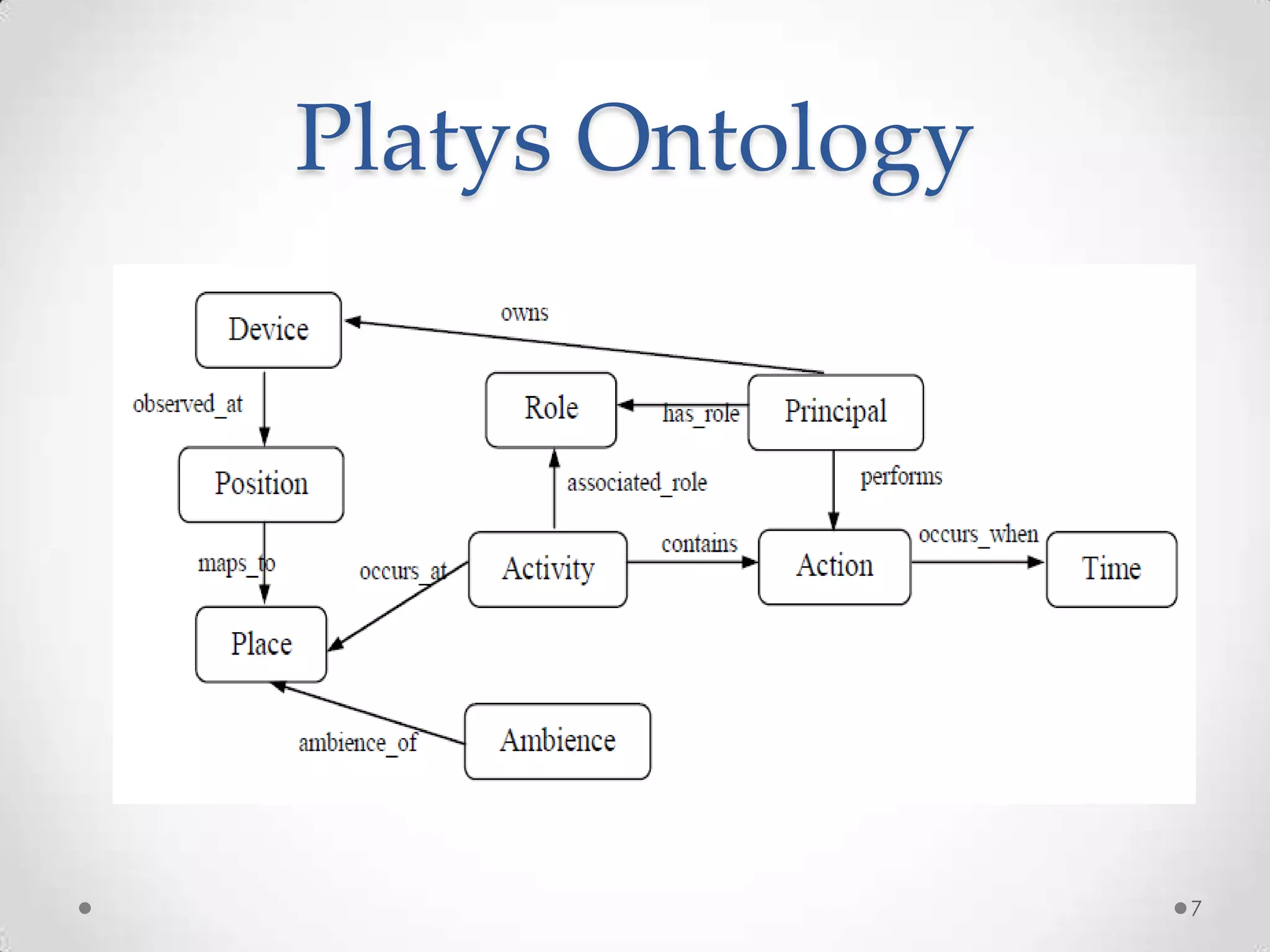
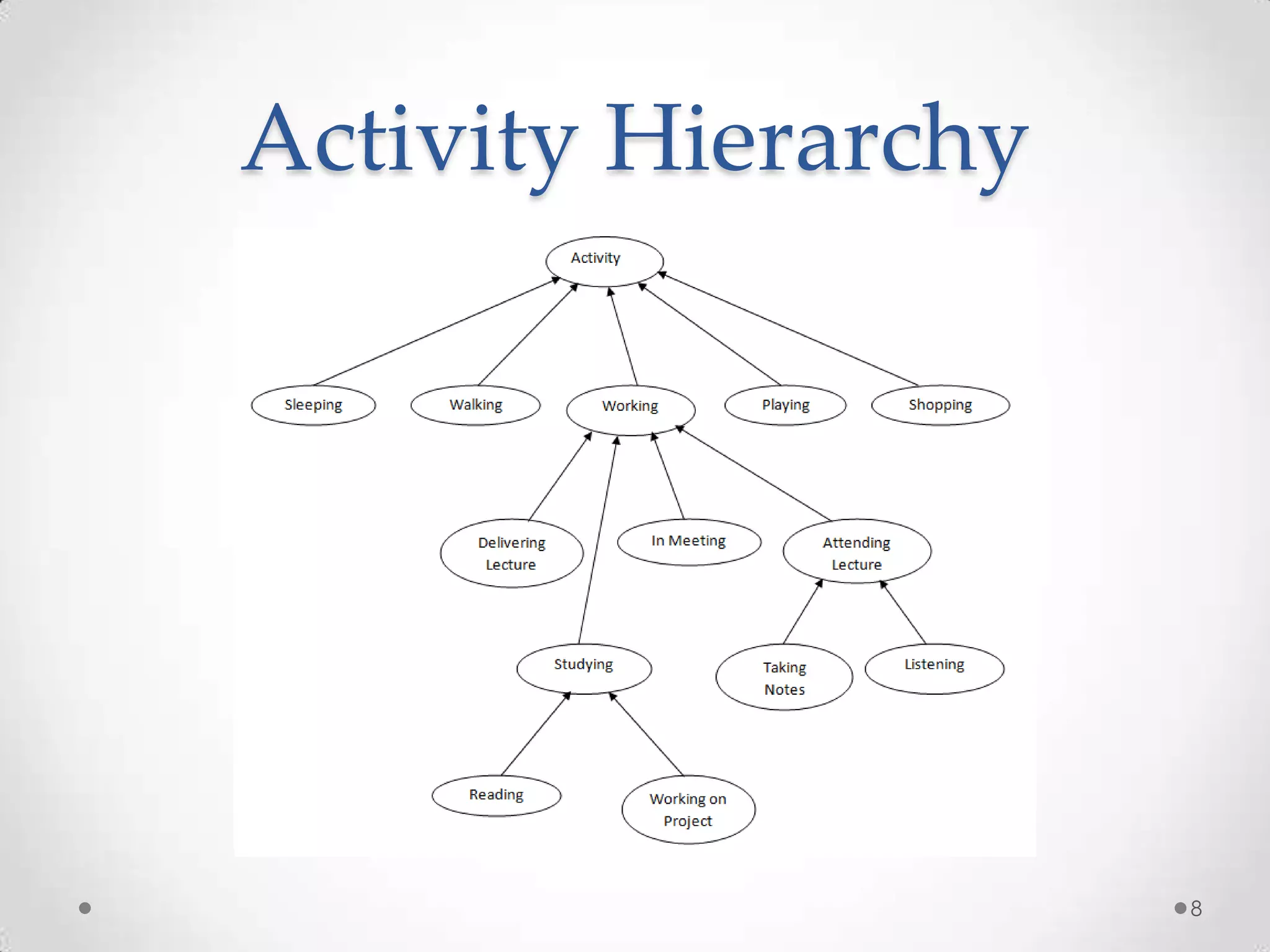
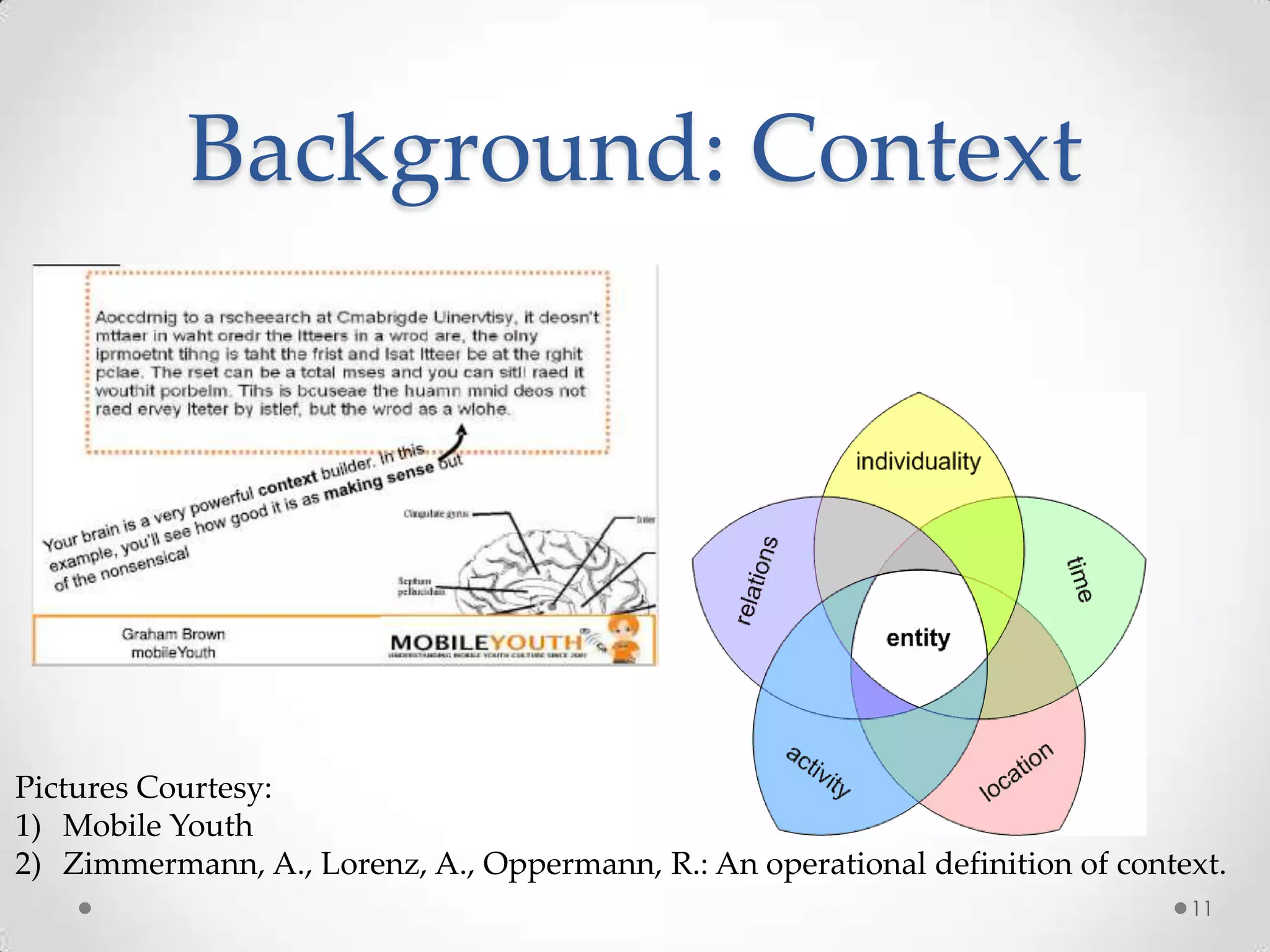
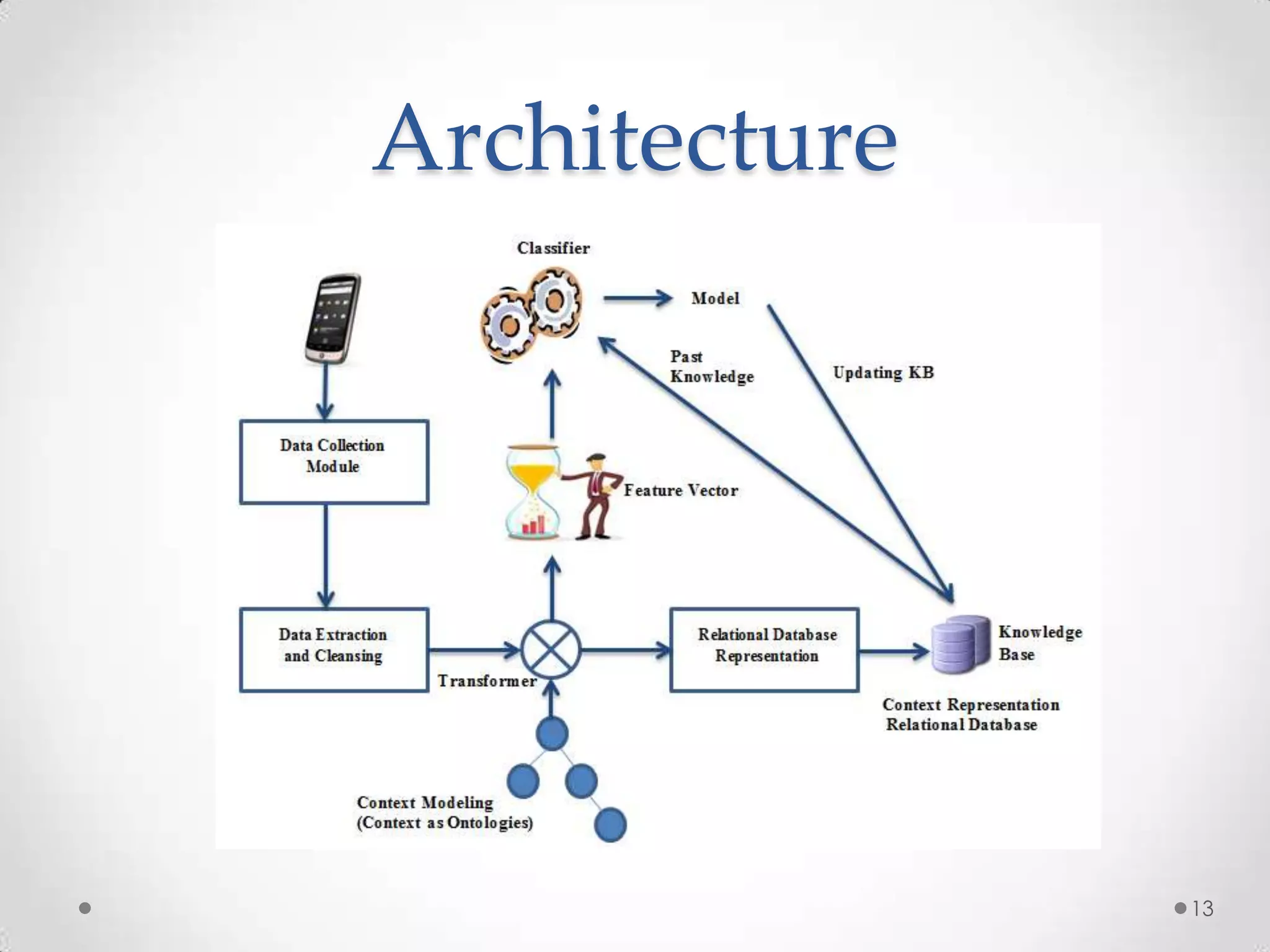
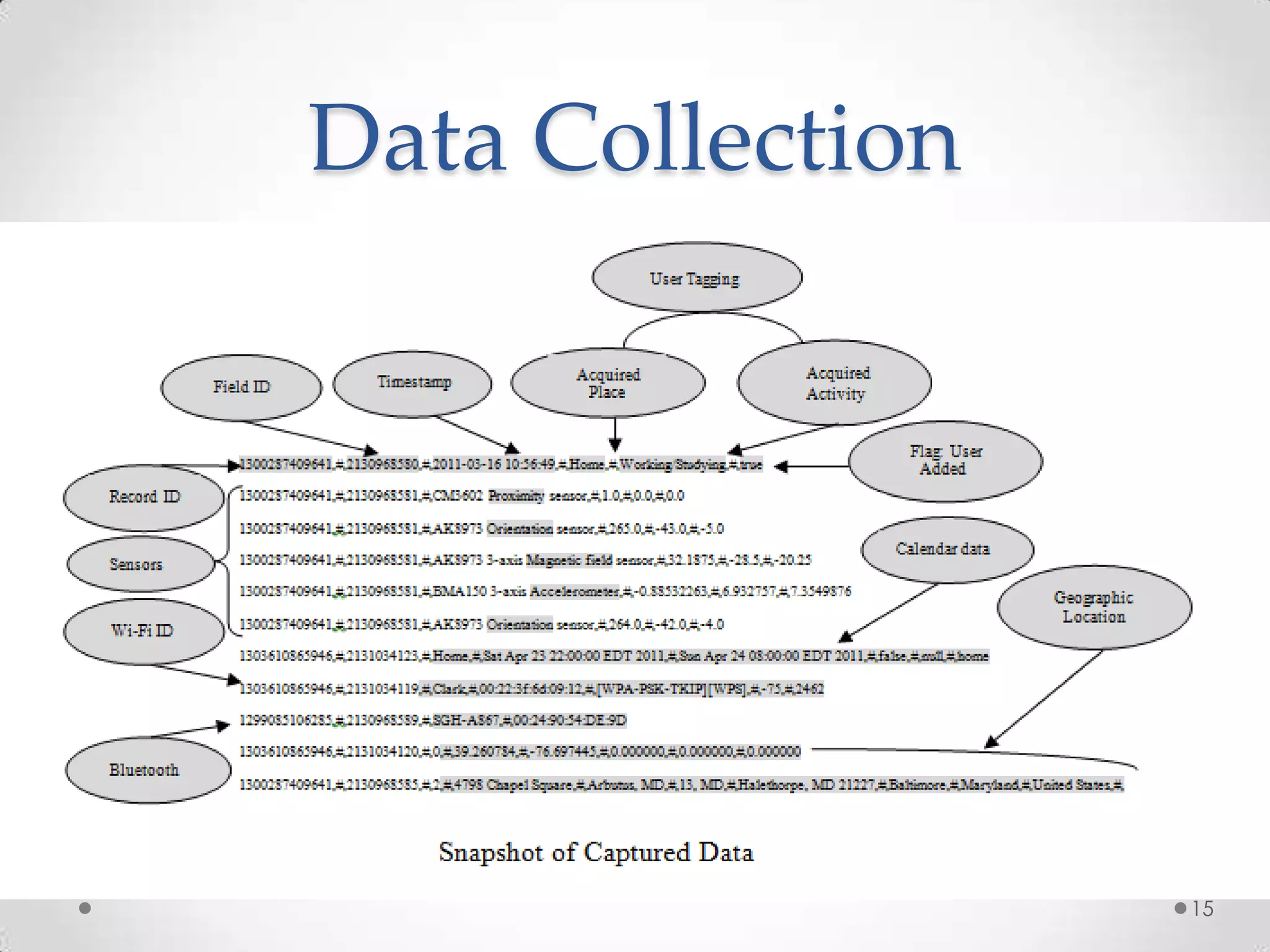
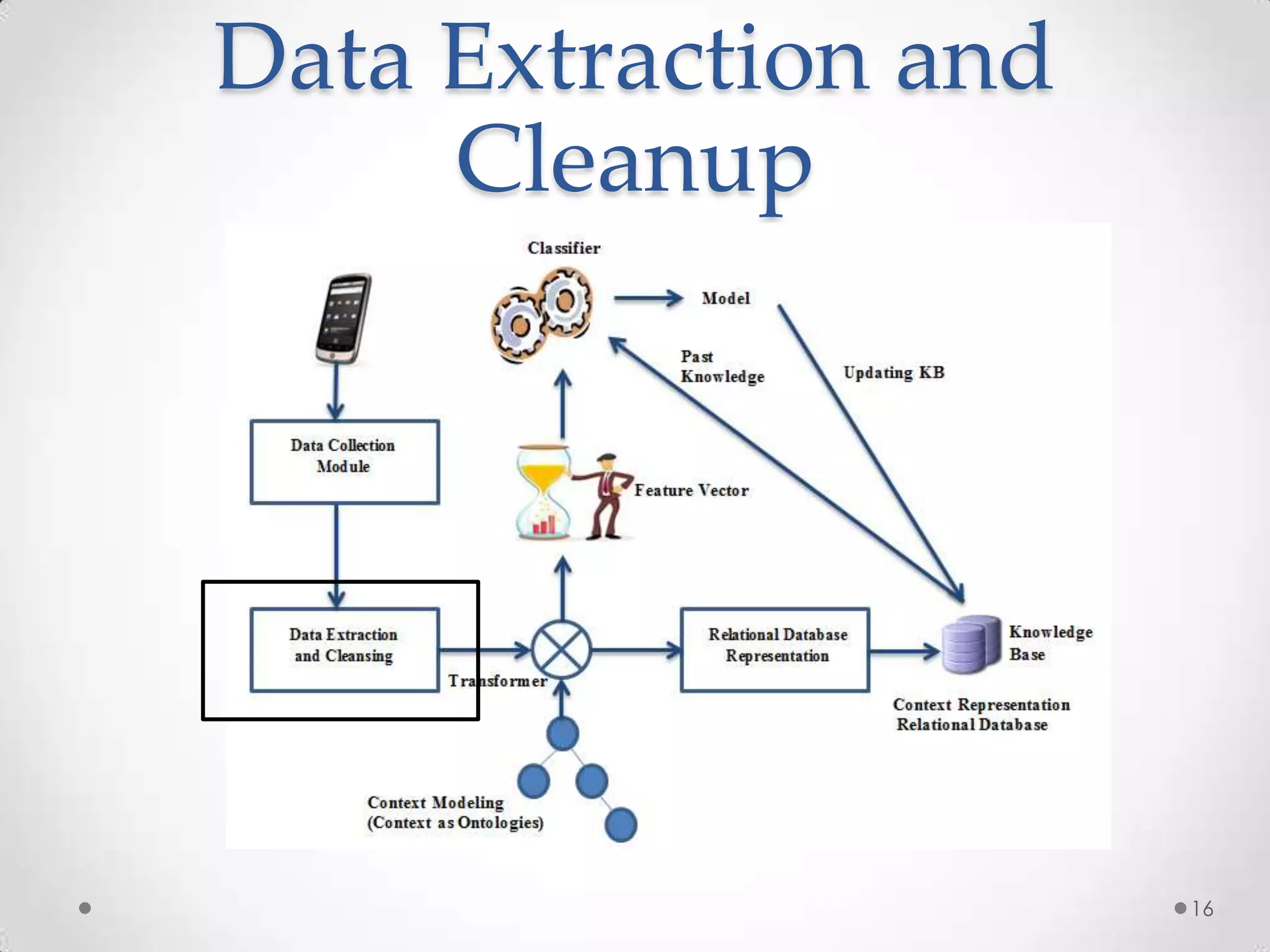
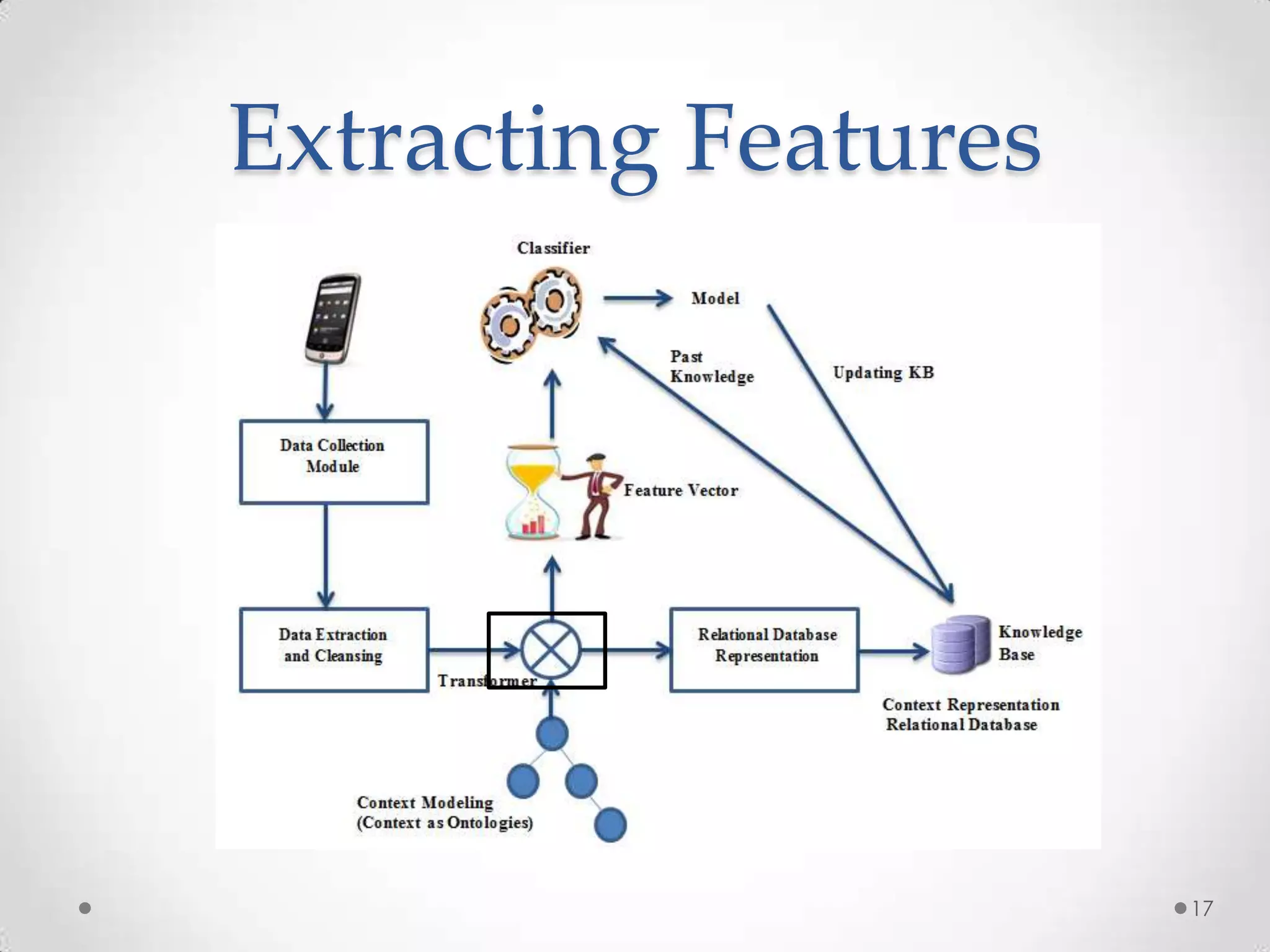
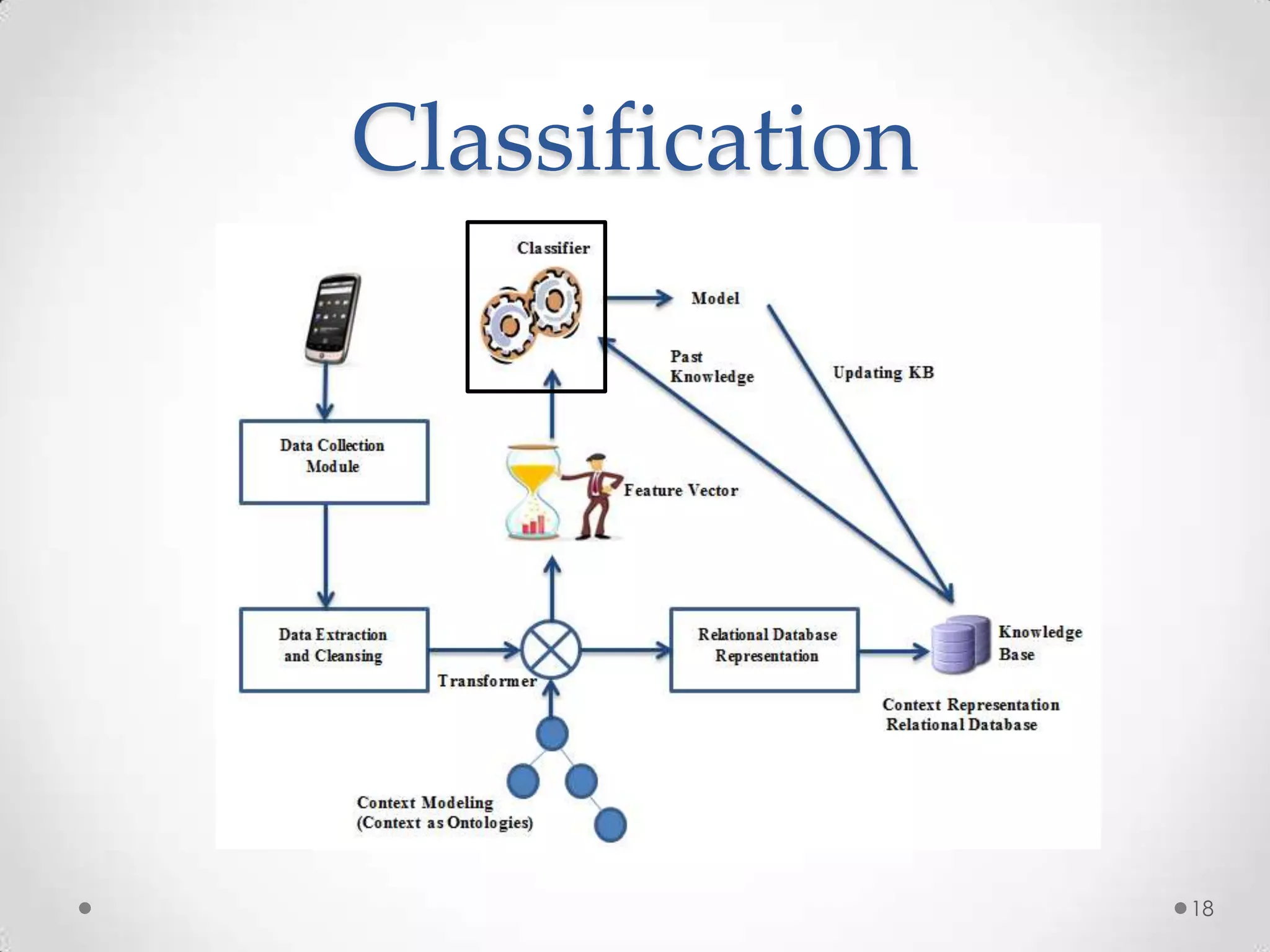
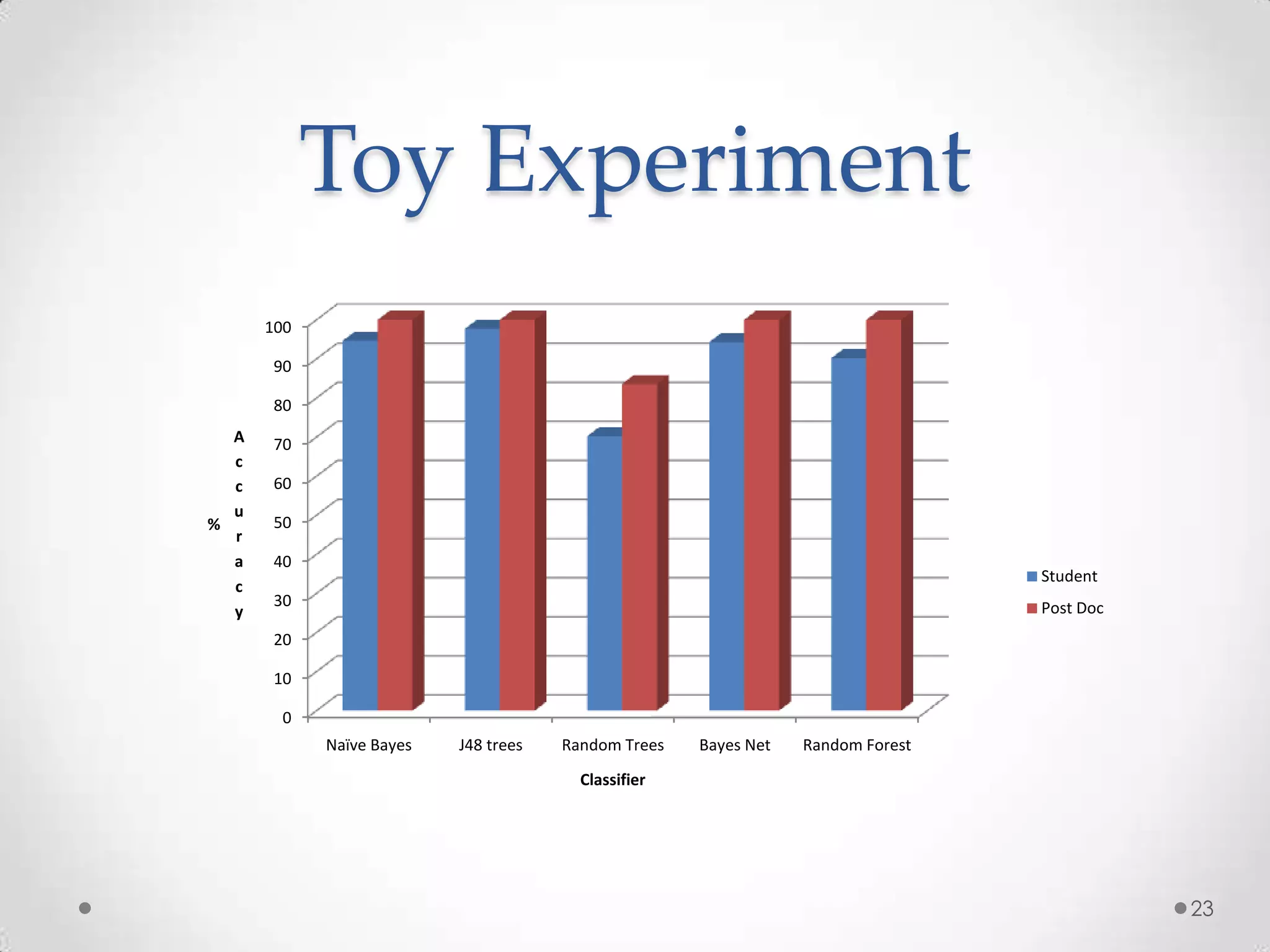
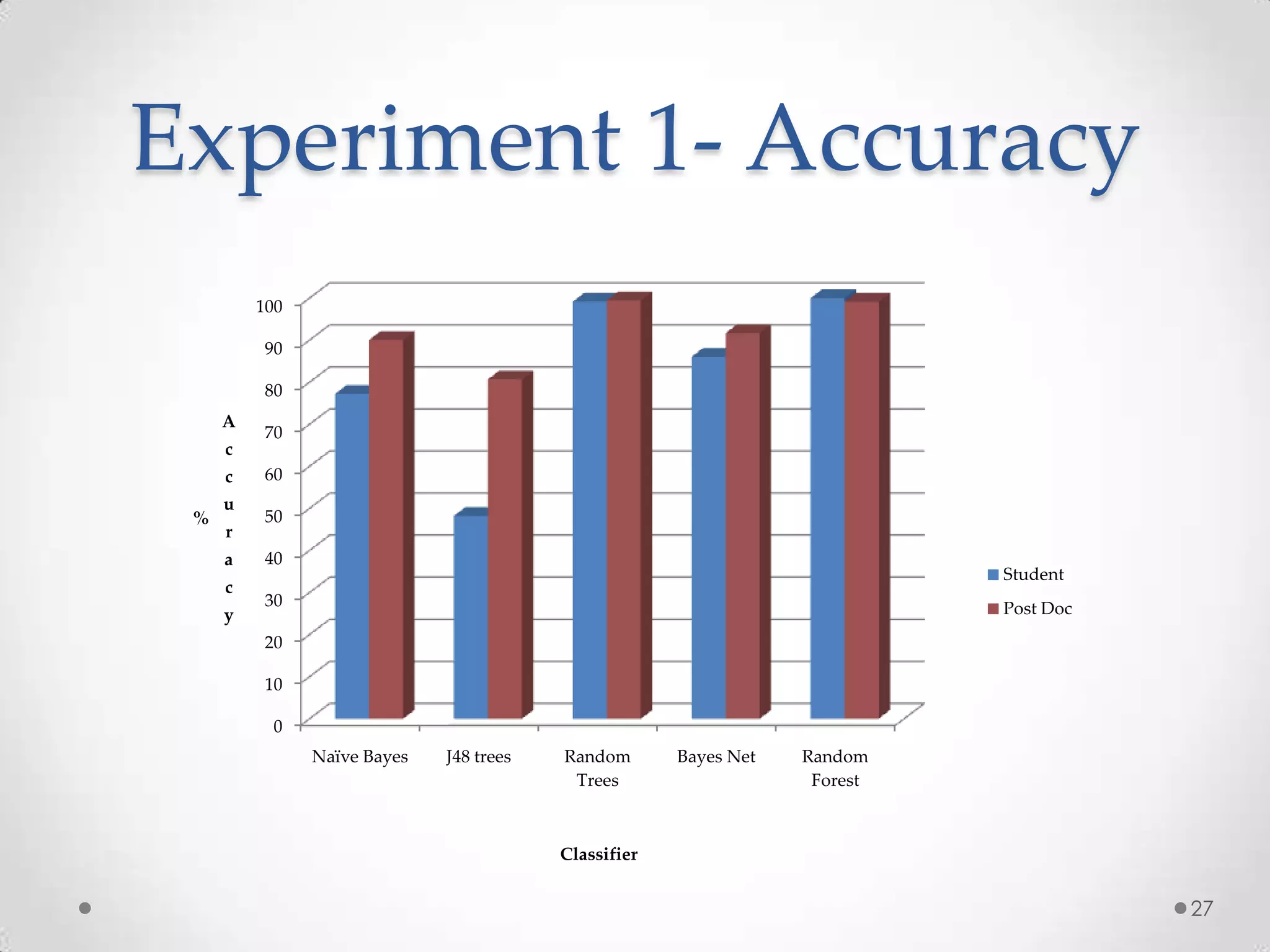
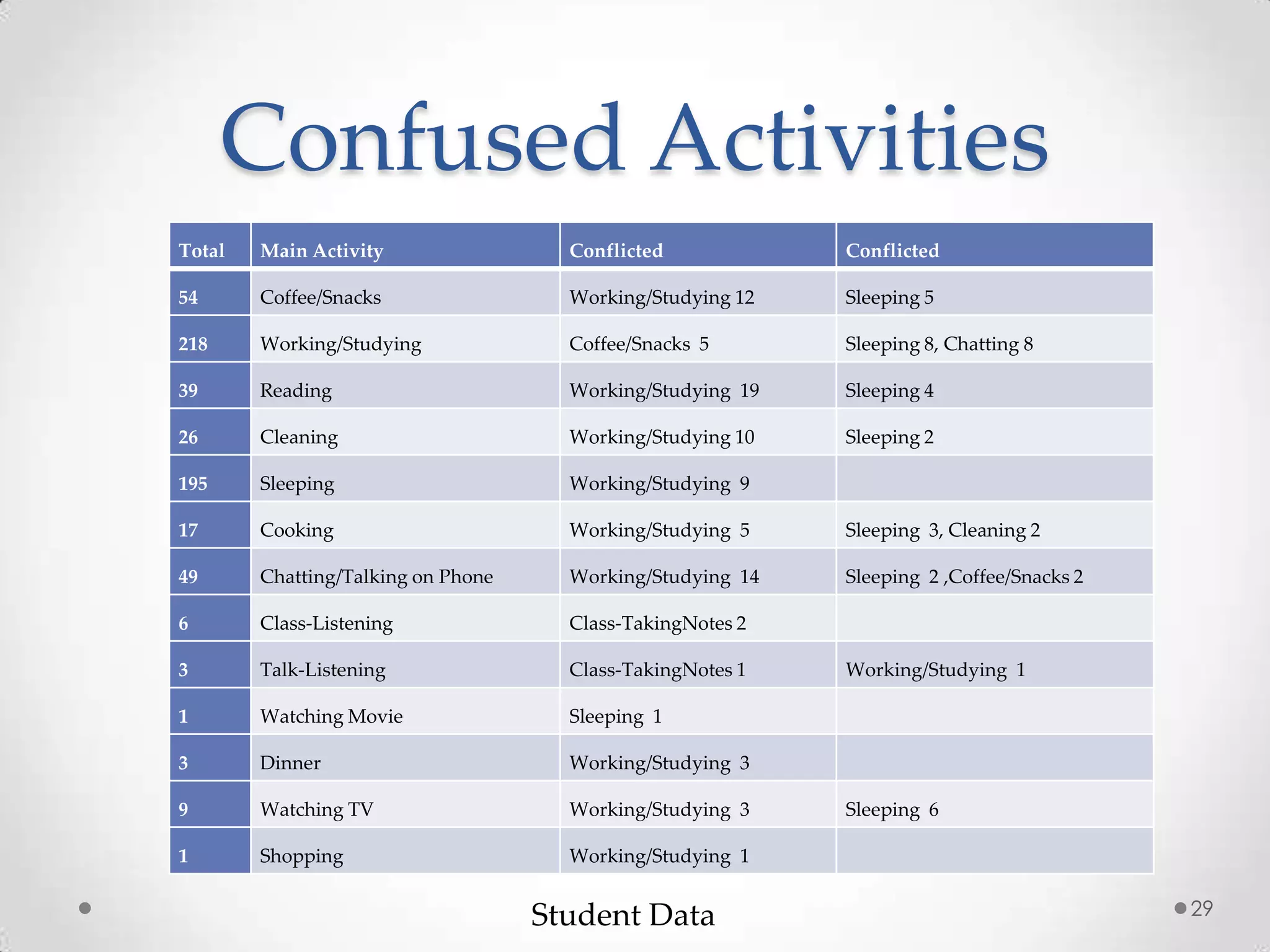
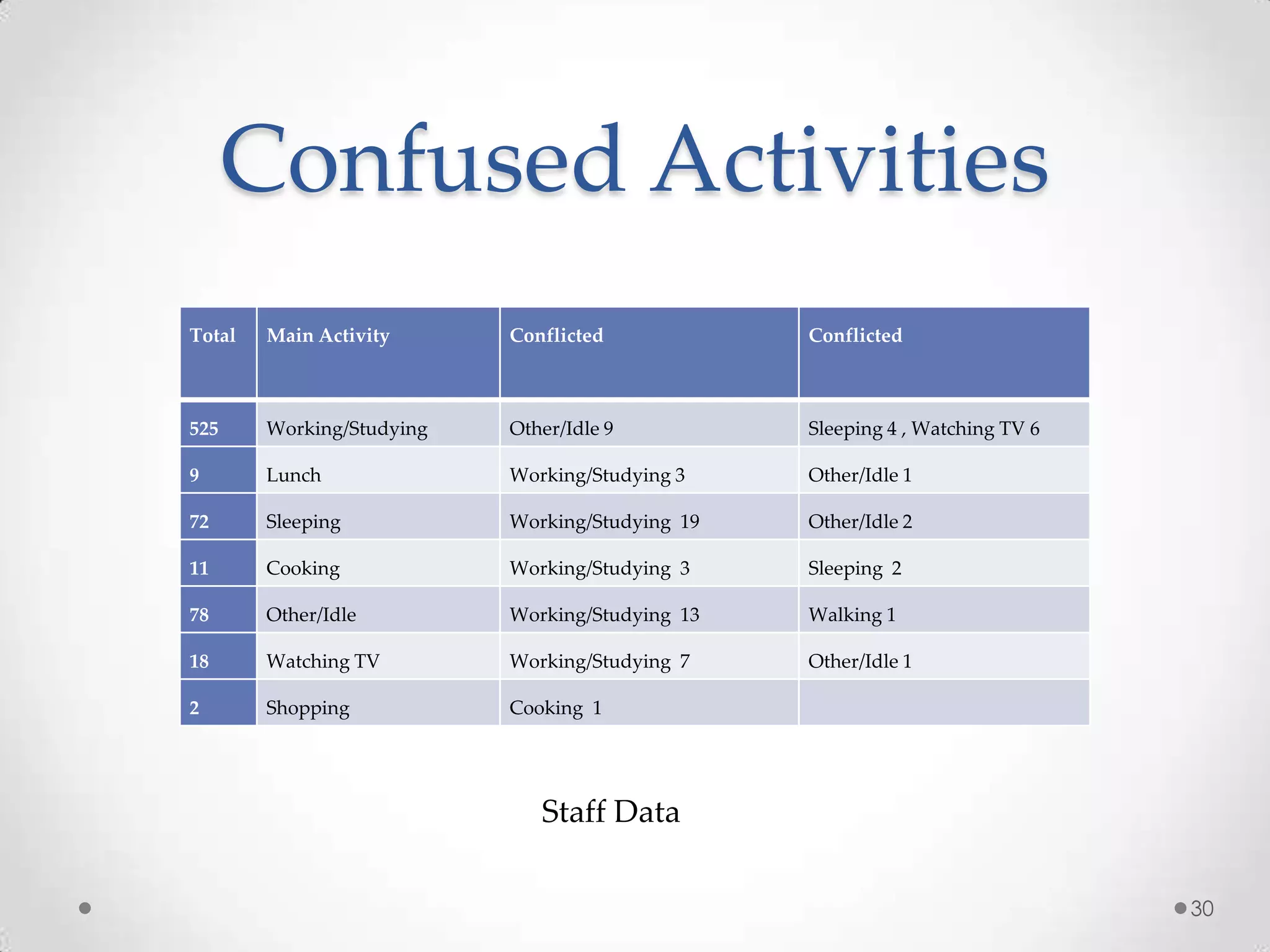
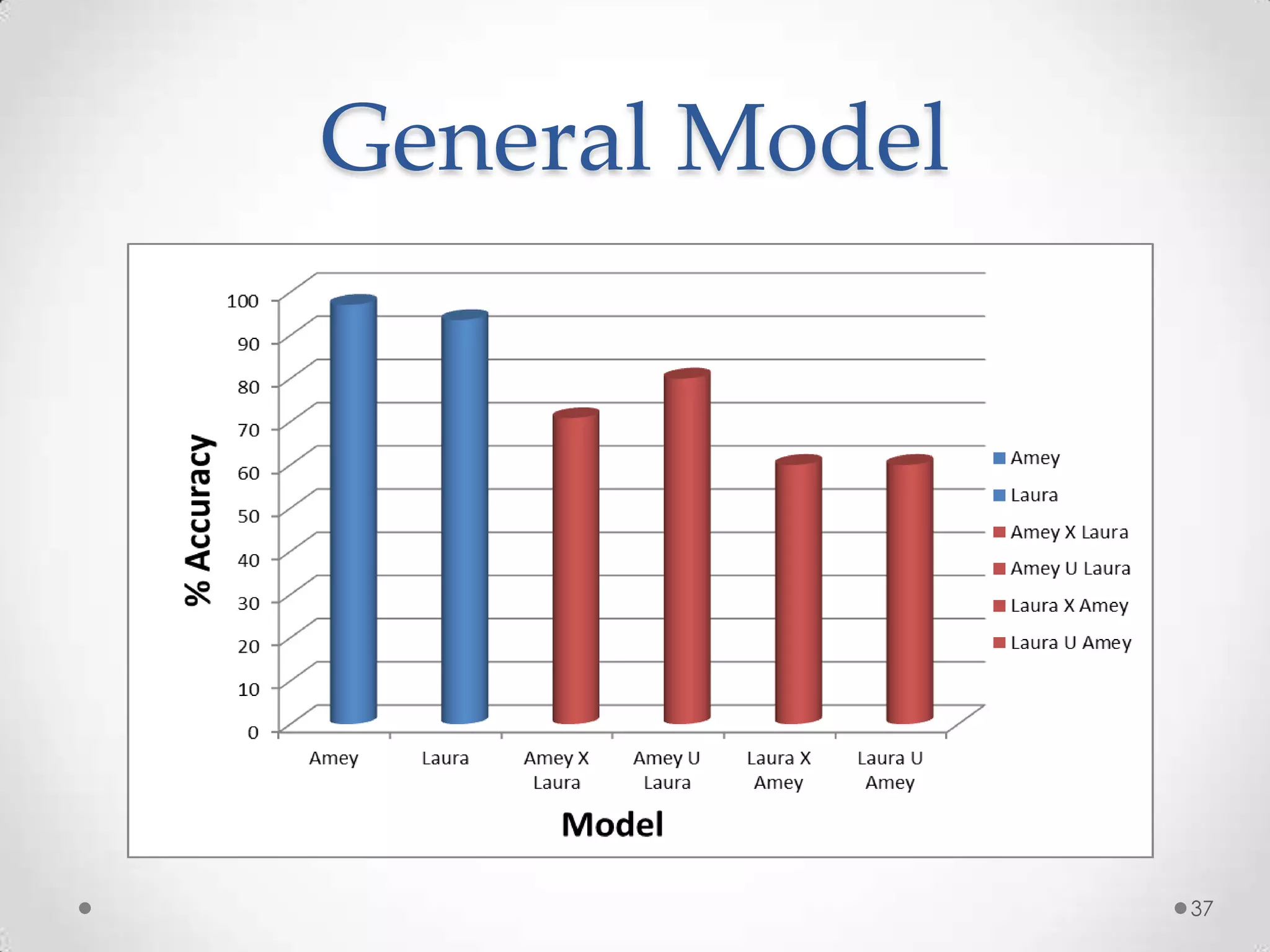
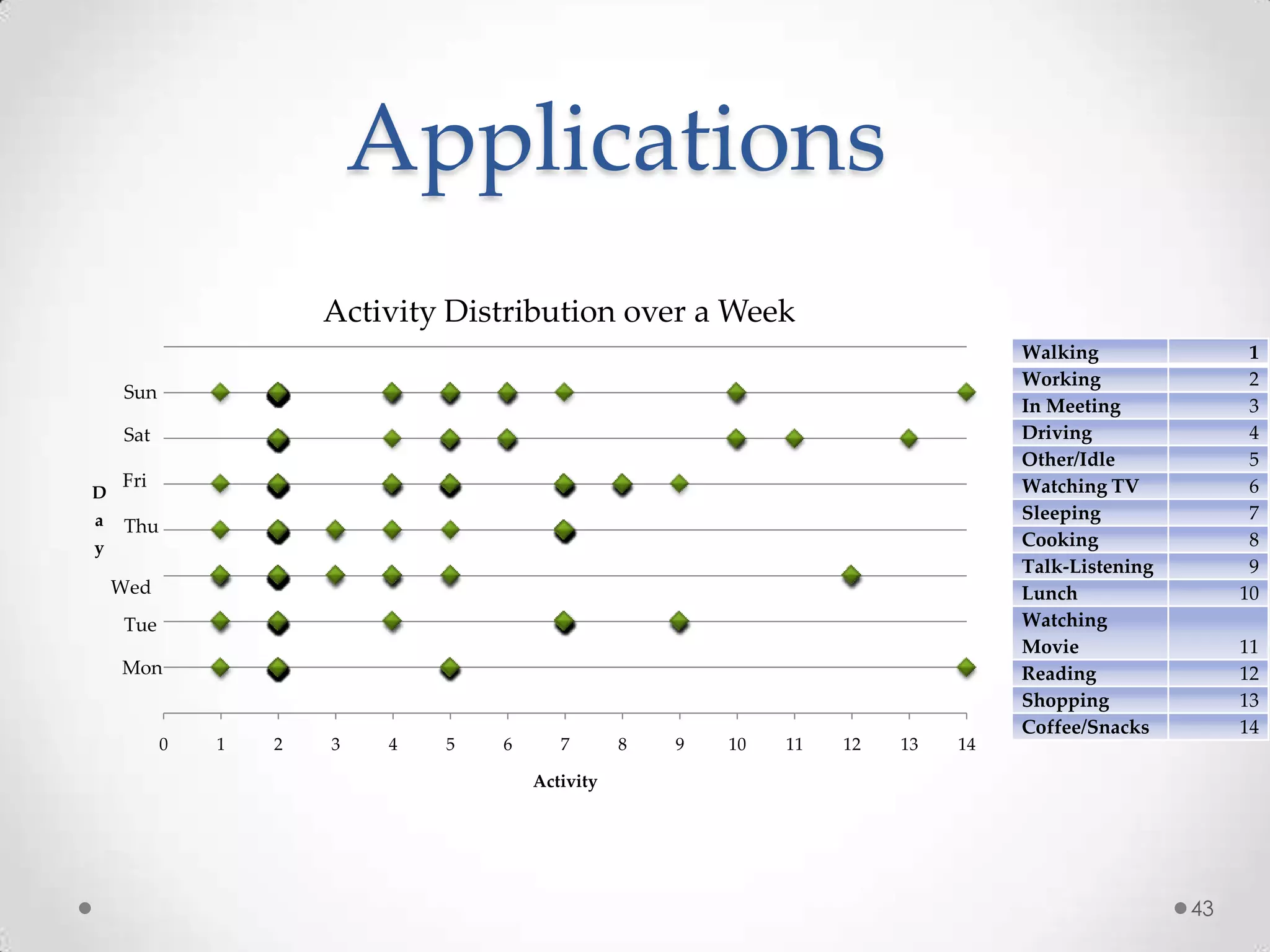
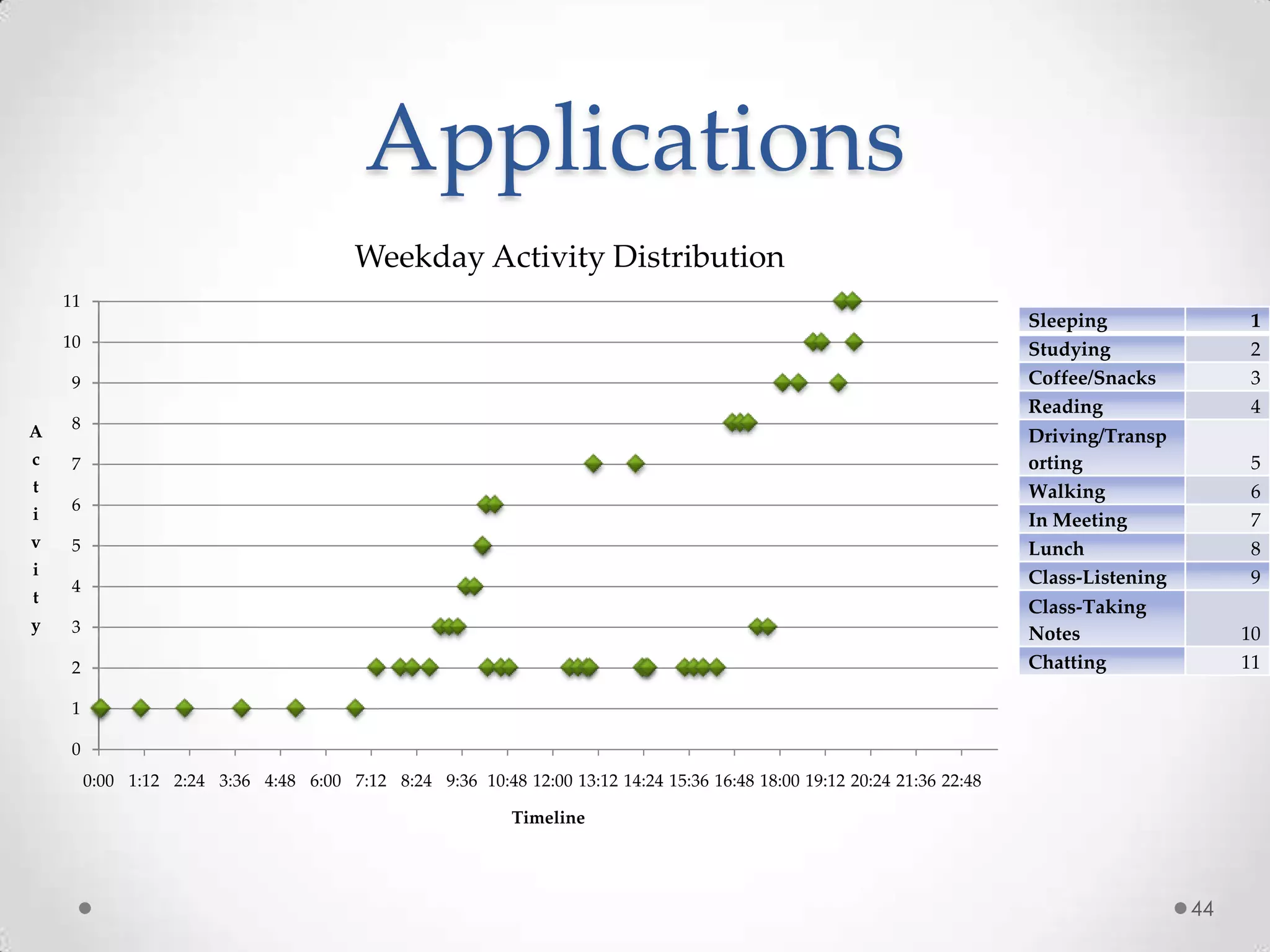
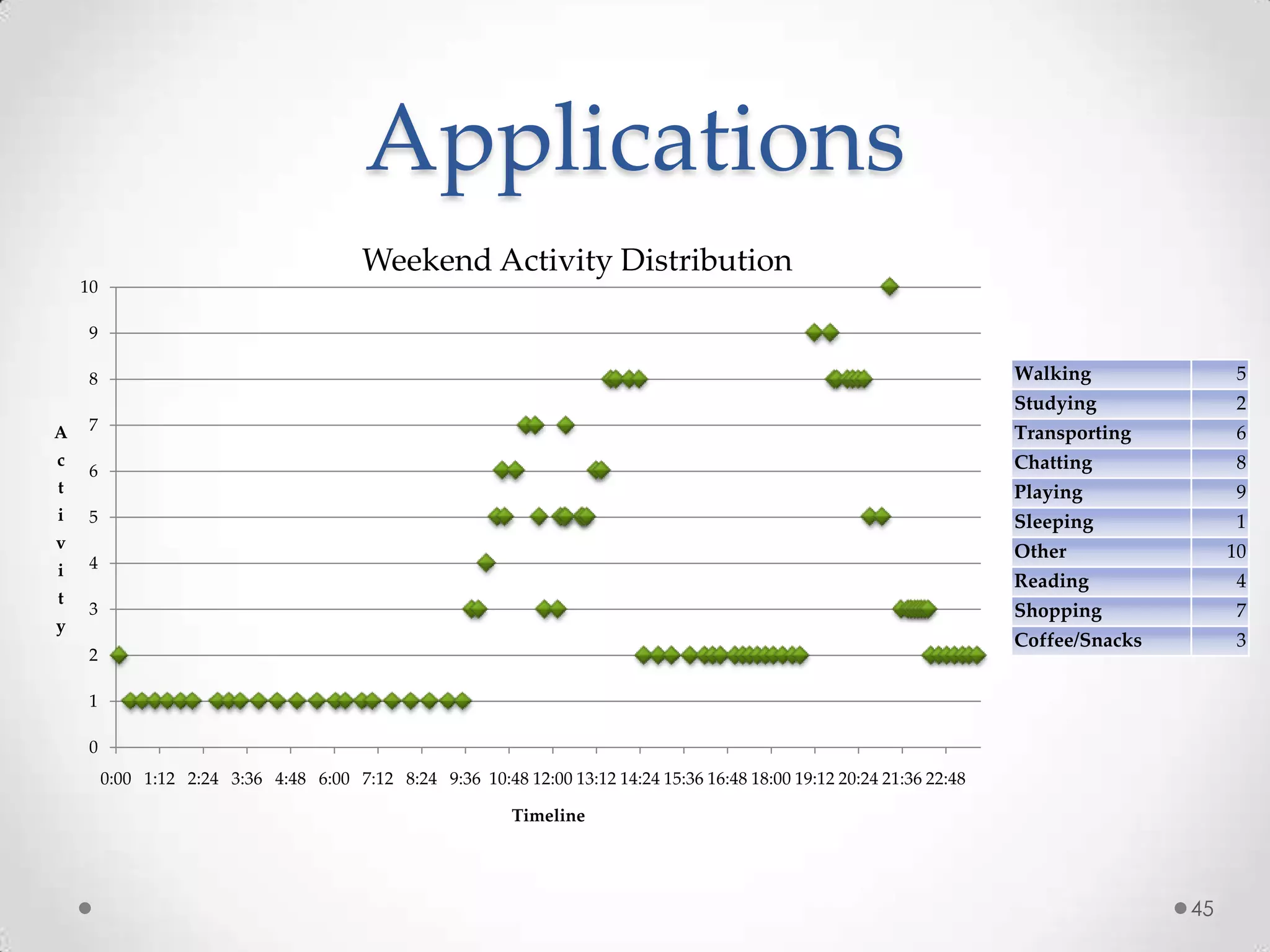
The document summarizes Radhika Dharurkar's Masters thesis defense on context-aware middleware for activity recognition. It provides an overview of her motivation, approach, implementation, experiments and results. Her work involved developing a prototype system that can predict 10 activities using data from smartphone sensors and other sources with better than average precision. Experiments were conducted collecting data from 2 users over 2 weeks to evaluate different classification algorithms on recognizing activities like working, studying, sleeping, etc. The most confused activities in classification were working/studying with others like coffee/snacks and sleeping.




















![Experiment 2- Confusion
Matrix
a b c d e f g h i j k <-- classified as
677 1 0 0 0 0 4 0 0 0 2 | a = [Sleeping]
0 186 0 0 20 0 3 0 5 0 0 | b = [Walking]
0 0 27 0 0 0 0 0 0 0 0 | c = [In Meeting]
0 2 0 65 0 4 0 0 0 0 0 | d = [Playing]
0 37 0 0 37 0 0 0 4 0 0 | e = [Driving/Transporting]
0 0 0 2 0 146 1 0 0 2 0 | f = [Class-Listening]
8 0 0 0 0 2 52 2 0 0 8 | g = [Lunch]
9 0 0 0 0 0 8 11 0 0 0 | h = [Cooking]
0 11 0 0 6 0 0 0 13 0 0 | i = [Shopping]
0 2 0 0 0 5 0 0 0 7 0 | j = [Talk-Listening]
5 0 0 0 0 0 1 0 0 0 34 | k = [Watching Movie]
33](https://image.slidesharecdn.com/radhikathesis-13338165318315-phpapp02-120407113835-phpapp02/75/Radhika-Thesis-33-2048.jpg)






![Example J48+Bagging
Afternoon = False
Place = Home: Sleeping (9.0/2.0) | Evening = False
Place = ITE346: In Meeting (1.0) | | Place = Outdoors: Walking (1.0)
Place = Outdoors | | Place = Elsewhere: Sleeping (0.0)
| G1 = False | Evening = True: Walking (4.0)
| | Morning = True: Walking (5.0/2.0) Afternoon = True
| | Morning = False: Driving/Transporting (17.0/2.0) | Wifi Id8 = True: In Meeting (3.0)
| G1 = True: Walking (2.0) | Wifi Id8 = False
Place = Home | | Place = Home: Lunch (0.0)
| Evening = False: Sleeping (20.0) | | Place = Restaurant: Lunch (4.0)
| Evening = True | | Place = Movie Theater: Watching Movie (2.0)
| | noise = '(-inf-28.19588]': Cooking (0.0) | | Place = Work/School: Working (1.0)
| | noise = '(28.19588-32.71862]': Cooking (2.0) | | Place = ITE346: Lunch (0.0)
| | noise = '(32.71862-inf)': Watching Movie (1.0) | | Place = Outdoors: Walking (1.0)
Place = Restaurant: Lunch (5.0) | | Place = ITE3338/ITE377: Lunch (0.0)
Place = Movie Theater: Watching Movie (2.0)
Place = Elsewhere: Walking (1.0)
Place = ITE325: Talk-Listening (4.0) Wifi Id8 = True: In Meeting (6.0/1.0)
Place = ITE3338/ITE377: In Meeting (2.0) Wifi Id8 = False
Place = Groceries store: Shopping (1.0) | Afternoon = False
| | Evening = False: Sleeping (24.0/1.0)
| | Evening = True: Walking (5.0)
loc2 = '(-inf-39.17259]': Watching Movie (2.0) | Afternoon = True
loc2 = '(39.17259-39.18528]': Sleeping (0.0) | | Place = Work/School: Working (1.0)
loc2 = '(39.18528-39.19797]': Lunch (4.0) | | Place = ITE346: Lunch (0.0)
loc2 = '(39.24873-39.26142]': Walking (9.0/2.0) | | Place = Outdoors: Walking (1.0)
| | Place = Home: Lunch (0.0)
| | Place = ITE3338/ITE377: Lunch (0.0)
41](https://image.slidesharecdn.com/radhikathesis-13338165318315-phpapp02-120407113835-phpapp02/75/Radhika-Thesis-41-2048.jpg)





![ES – Decision Trees
• Each node = attribute
• End leaf gives classification results
• Root node = Most information gain(Claude
Shannon) If there are equal numbers of yeses and
no's, then there is a great deal of entropy in that
value. In this situation, information reaches a
maximum Info = -SUMi=1tom p1logp1
• attr 2 yes, 3 no=I([2,3])= -2/5 x log 2/5 - 3/5 x log 3/5
• Average them n subtract frm I(whole)
50](https://image.slidesharecdn.com/radhikathesis-13338165318315-phpapp02-120407113835-phpapp02/75/Radhika-Thesis-50-2048.jpg)










![[SeNAmI'12] Towards a fuzzy-based multi-classifier selection module for activ...](https://cdn.slidesharecdn.com/ss_thumbnails/senami12towardsafuzzy-basedmulti-classifierselectionmoduleforactivityrecognitionapplications-120611064457-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

















