Download to read offline





















![elasSmate
Date 2182020
Page .
QS LITTLE'SLALD
L_A avg. ma spent b each pacdet
Qvg.t pockek/Aime
Cvg. H packek|austamers
K=Vz
E EY. Ez X
not aluwauE Costemers Qrived
roein lo,t1):At
avg Rach costomRn sperds w unit of ma
total tme spent o ol the
E D0Stomors thosa uoha arcivedin to,t].
L
Fotal time Spnt by thae
Customers : lt
t Lt Atw
tmtn 2mA g0ee
temy mt 5m
L Au
t lau](https://image.slidesharecdn.com/queuingtheory-201030182625/85/Queuing-theory-Notes-25-320.jpg)





















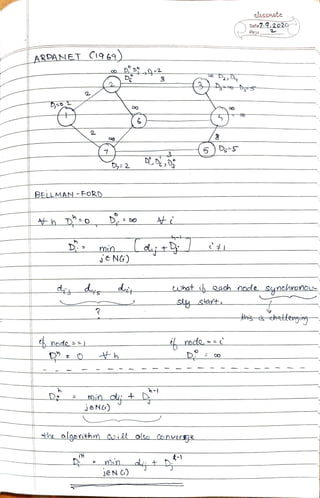


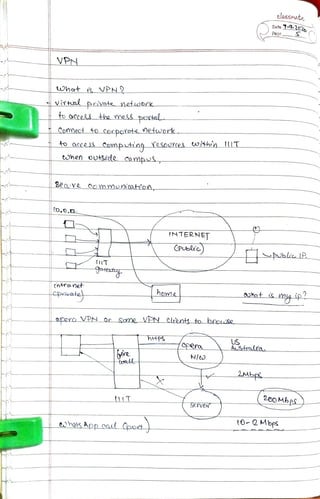
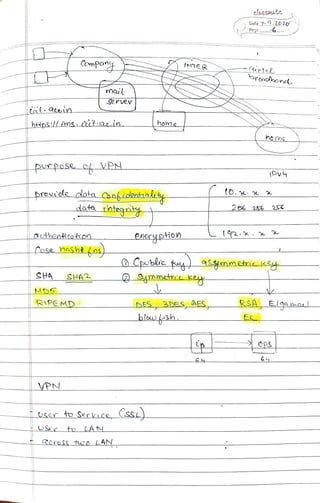
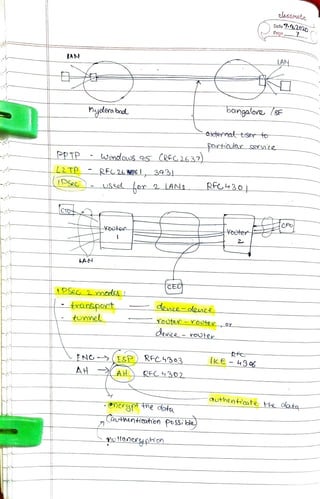


The document discusses queuing theory and its applications in telecommunications and networking. It covers various concepts including probability, random variables, Poisson processes, and service rates, highlighting their mathematical properties and implications for system performance. Additionally, it summarizes the importance of these theories in analyzing and optimizing service systems and customer wait times.





















































