Introduction of Q4MQ4M stands for Queue for MySQL Q4M の意は「 Queue for MySQL 」 A pluggable storage engine of MySQL 5.1 MySQL 5.1 用のプラガブルストレージエンジン Access & administration by SQL SQL を用いたアクセスと管理
4.
Design Goals ofQ4M Robust ( 堅牢性 ) No data loss on OS crash or power failure OS クラッシュや停電時にデータロスが発生しない Fast ( 高速性 ) Optimized for speed Flexible ( 柔軟性 ) Use of SQL for access and administration, including JOINs with other storage engines
5.
What is aMessage Queue? from Distributed Systems (Tanenbaum / Van Steen)
6.
What is aMessage Queue? Middleware for persistent asynchronous communication 持続的な非同期コミュニケーションのためのミドルウェア A.k.a. Message-Oriented Middleware 別名 : MOM
7.
Message Queue (cont.)MQ is an intermediate storage MQ は中間的なストレージ vs. RDBMS (long-term persistent storage) vs. RDBMS ( 永続的なストレージ ) Senders and/or receivers may go down 送受信プロセスが任意に停止可能
8.
Minimal Configuration ofa MQ ( 最小構成 ) Senders and receivers access a single queue 送信プロセスと受信プロセスが同一のキューにアクセス Sender Receiver Queue
9.
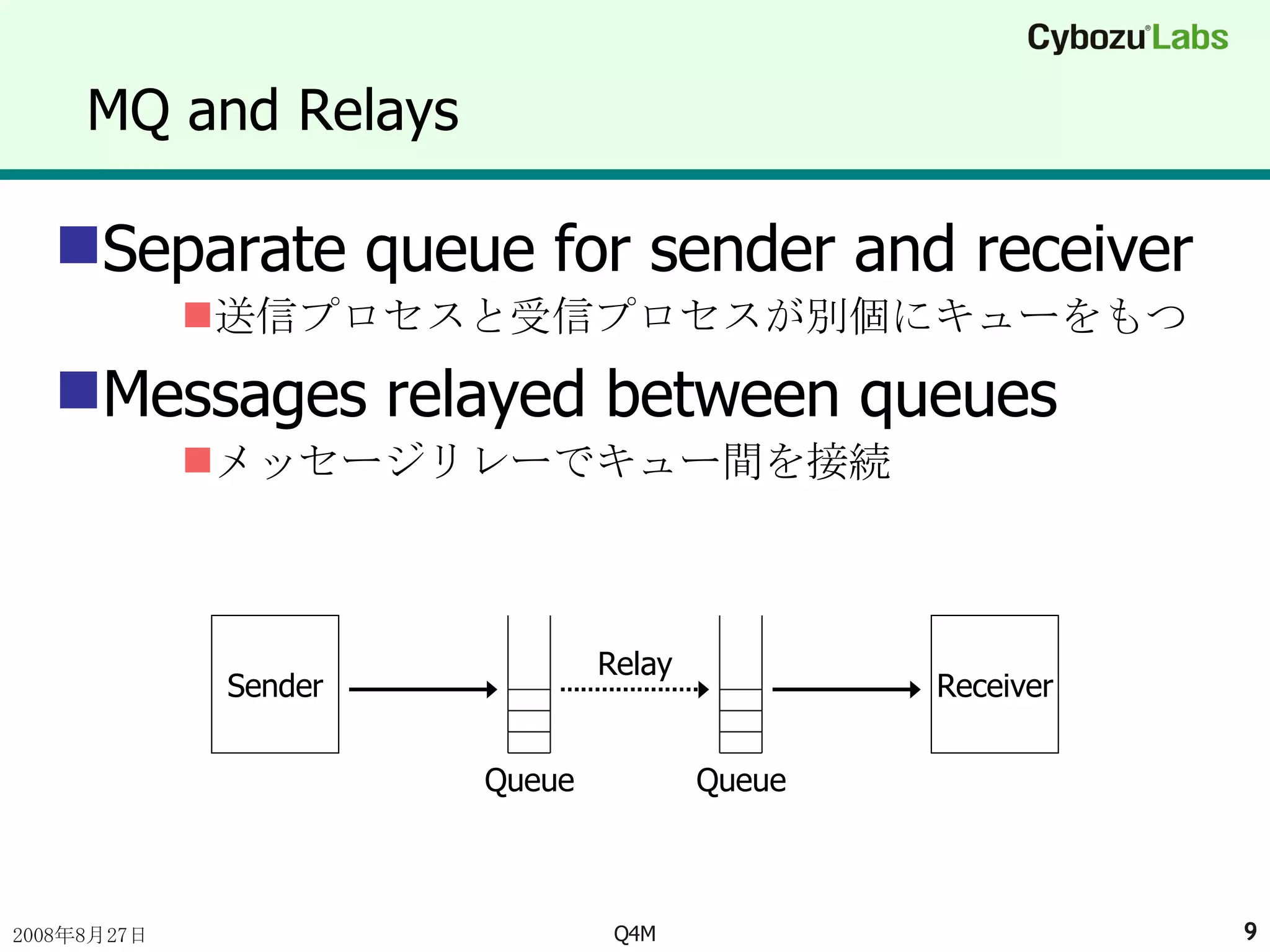
MQ and RelaysSeparate queue for sender and receiver 送信プロセスと受信プロセスが別個にキューをもつ Messages relayed between queues メッセージリレーでキュー間を接続 Sender Receiver Relay Queue Queue
10.
Merits of MessageRelays ( リレーの意義 ) Destination can be easily changed 宛先の変更が容易 Relays may transfer messages to different locations depending on the header ヘッダを見て転送先を変えるとか Robustness against network failure ネットワーク障害の影響を受けない Logging and Multicasting, etc. ロギングやマルチキャストが可能
11.
Message Brokers Transform(filter) messages within the relay agent リレーエージェント内でメッセージの変換を行う Publish / subscribe model Separation between logic and data transfer ロジックとデータ転送の分離
12.
Q4M as aMessage Queue (MQ としての Q4M) Q4M (can) support all models Q4M は全モデルに対応 ( 可能 ) Message transfer by q4m-forward メッセージ転送は q4m-forward で APIs for routers and message brokers ルータやメッセージブローカ用の API Q4M-forward is built upon those APIs Q4M-forward は、それら API を使用して開発
Internal Architecture ofQ4M Q4M maps queries from multiple threads to single I/O requests Q4M は複数スレッドからの SQL クエリを単一の I/O 処理にグループ化 Spawn multiple clients for maximum performance 多数のクライアントを同時実行することで、パフォーマンスを最大限に発揮
15.
Benchmark Troughput Test7,655 mess./sec. (avg. 256 bytes/mess.) Linux 2.6; x86_64; Opteron 2218x2 --with-sync=fdatasync --with-delete=msync $ VAR_LENGTH=504 CONCURRENCY=50 MESSAGES=100000 DBI='dbi:mysql:test;mysql_socket=/tmp/mysql51.sock' DBI_USER=root MYSQL_SOCKET='/tmp/mysql51.sock' USE_C_CLIENT=1 t/05-multirw.t 1..4 ok 1 - check number of messages ok 2 - min value of received message ok 3 - max value of received message ok 4 - should have no rows in table Multi-reader-writer benchmark result: Number of messages: 100000 Number of readers: 50 Elapsed: 13.063 seconds Throughput: 7655.070 mess./sec.
16.
Benchmark (cont.) Nosync. to disk 23,637 mess./sec. (256 bytes/mess.) --with-sync=no --with-delete=msync
OWNER Mode andNON-OWNER Mode (cont.) Within OWNER mode, only the owned row are visible OWNER モードでは、所有中の行のみが見える Within NON-OWNER mode, rows owned by other connections are invisible NON-OWNER モードでは、他の接続が所有している行は見えない
22.
Function for EnteringOWNER Mode queue_wait Used to enter OWNER mode OWNER モードに ( 再 ) 切替するために使用 When called within OWNER mode, the owned row is deleted
23.
queue_wait Two formsqueue_wait(tbl_cond) queue_wait(tbl_cond,[tbl_cond…,timeout])
24.
queue_wait(tbl_cond) Wait max.60 seconds until any data becomes available on given table under given condition 最大 60 秒間、指定された条件に合致する行が指定されたテーブルに登録されるまでブロック Returns 1 if successful, 0 if no data 成功すれば 1 、データがなければ 0 Enters OWNER mode even if no data データがない場合でも OWNER モードへ切り替わる
25.
queue_wait(tbl_cond) Table name(and optionally condition) should be specified テーブル名と ( オプションで条件 ) を指定 Only numeric columns may be used within condition 条件節では数値型のカラムのみ使用可能 See queue_share_t::init_fixed_fields tbl_cond ::= table [ “:” cond]
queue_wait(tbl_cond,[tbl_cond…,timeout]) Accepts multipletables and timeout 複数のテーブルとタイムアウトを指定可能 Data searched from leftmost table to right データは左端のテーブルから右方向に探索 Returns table index (the leftmost table is 1) of the newly owned row 獲得した行の属するテーブルのインデックス ( 左端のテーブルが 1) を返す
28.
Functions for ExitingOWNER Mode queue_end Deletes the owned row and exits OWNER mode 所有中の行を削除して OWNER モードを脱出 queue_abort Releases (instead of deleting) the owned row and exits OWNER mode 所有中の行を非所有状態に変更して OWNER モードを脱出 Close of a MySQL connection does the same thing MySQL の接続切断時も同様
29.
Receiving a Message(revisited) while (1) { SELECT queue_wait(‘queue’);; my @row = SELECT ROW * FROM queue; or next; if (consume_row(@row) != SUCCESS) { exit(1); } }
30.
Restrictions in SQLof Q4M No indexes No UPDATE Why need UPDATE a queue row? キューのデータを UPDATE する必要なんてない SELECT and DELETE are supported for queue administration SELECT DELETE を使ってキューを管理可能 ex. select count(*) from queue;
31.
Why no IndexesSupport? There is generally no reason to support indexes with mysql-based queues, since mysql cannot handle a large number of connections requesting data under various conditions インデックスが必要になるほど多様な条件を指定して同時に購読できるほど、 mysql の同時接続数は大きくない
32.
Why no IndexesSupport? Instead use conditional subscription Conditional subscription 機能を使うべき Or route data after reading from Q4M あるいは Q4M からデータを読んだ後にルーティングすべき
33.
Configuration Options ofQ4M --with-sync=no|fsync|fdatasync|fcntl Controls synchronization to disk, see --help for detail --enable-mmap Mmap’ed reads lead to higher throughput --enable-mmap-writes DELETEs commited using mmap(PROT_WRITE) and msync, recommended on linux>=2.6.20 if you need really high performance
Connecting Distant ServersPathtraq uses Q4M queues and a relay to communicate with its content analysis service running in a different iDC Pathtraq では、 Q4M キューとメッセージリレーを使用して、別の iDC にあるコンテンツ分析サービスと接続している Content Analysis Service Pathtraq DB MySQL conn. over SSL,gzip Queue Queue
37.
User Notifications Forsending notifications from web services ウェブサービスでユーザ通知送信のために使用可能 DB App. Logic SMTP Agent IM Agent Queue(s)
38.
Asynchronous Updates Asynchronousupdates leads to faster response of web services 非同期更新に利用することでウェブサービスの応答性を向上可能 DB App. Logic DB Queue
39.
Scheduling Web CrawlersWeb crawlers with retry-on-error リトライ機能つき Web クローラー Example included in the Q4M distribution URL DB Spiders Re- scheduler Store Result Read URL If failed to fetch, store URL in retry queue Request Queue Retry Queue
40.
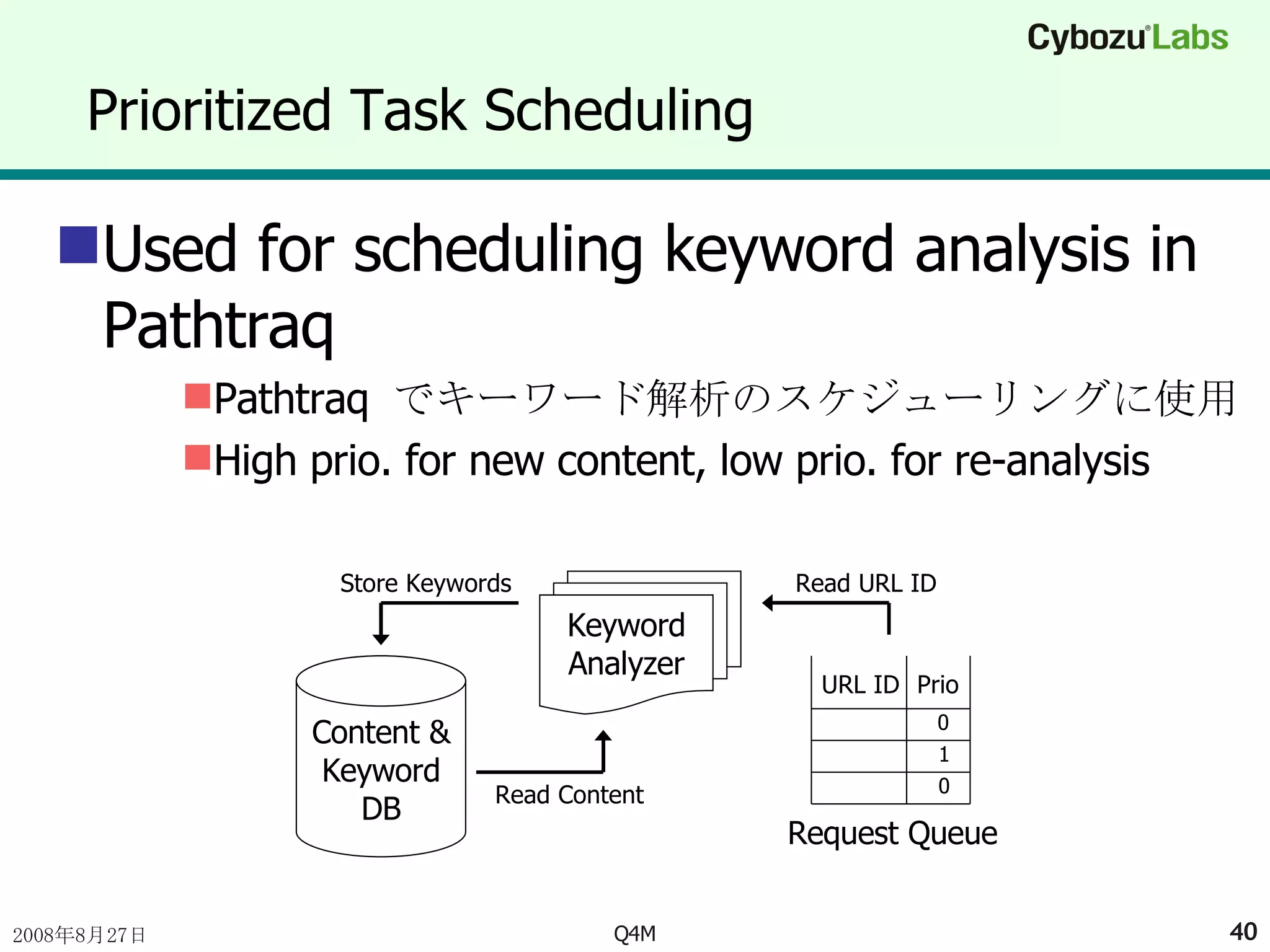
Prioritized Task SchedulingUsed for scheduling keyword analysis in Pathtraq Pathtraq でキーワード解析のスケジューリングに使用 High prio. for new content, low prio. for re-analysis Content & Keyword DB Request Queue Keyword Analyzer Store Keywords Read URL ID Read Content URL ID Prio 0 1 0
41.
Prioritized Task Scheduling(cont.) select queue_wait(’queue:prio<0’, ’ queue:prio=0’,’queue:prio>0’); # ugly part of not having indexes support… Content & Keyword DB Request Queue Keyword Analyzer Store Keywords Read URL ID Read Content URL ID Prio 0 1 0





















![queue_wait Two forms queue_wait(tbl_cond) queue_wait(tbl_cond,[tbl_cond…,timeout])](https://image.slidesharecdn.com/q4mmicroblogcon-1220078550045540-8/75/Q4M-Microblogcon-23-2048.jpg)

![queue_wait(tbl_cond) Table name (and optionally condition) should be specified テーブル名と ( オプションで条件 ) を指定 Only numeric columns may be used within condition 条件節では数値型のカラムのみ使用可能 See queue_share_t::init_fixed_fields tbl_cond ::= table [ “:” cond]](https://image.slidesharecdn.com/q4mmicroblogcon-1220078550045540-8/75/Q4M-Microblogcon-25-2048.jpg)

![queue_wait(tbl_cond,[tbl_cond…,timeout]) Accepts multiple tables and timeout 複数のテーブルとタイムアウトを指定可能 Data searched from leftmost table to right データは左端のテーブルから右方向に探索 Returns table index (the leftmost table is 1) of the newly owned row 獲得した行の属するテーブルのインデックス ( 左端のテーブルが 1) を返す](https://image.slidesharecdn.com/q4mmicroblogcon-1220078550045540-8/75/Q4M-Microblogcon-27-2048.jpg)