More Related Content

PDF
MHA for MySQLとDeNAのオープンソースの話 
PPT

PPTX

PDF

PDF

PDF
MySQL 5.6新機能解説@dbtechshowcase2012 
PDF

PDF
MySQL ガチBeginnerがやってみたことと反省したこと What's hot

PDF
MHAの次を目指す mikasafabric for MySQL 
KEY
My sql casual_in_fukuoka_vol1 
PDF

PDF
What's New in MySQL 5.7 Security 
PDF
tcpdump & xtrabackup @ MySQL Casual Talks #1 
PDF

PDF
Art of MySQL Replication. 
PDF

PDF

PPTX

PPTX

PDF

PDF
MySQL Cluster 7.4で楽しむスケールアウト @DB Tech Showcase 2015/06 
PDF

PDF
MySQL5.7 GA の Multi-threaded slave 
PDF
MySQL5.7とMariaDB10.1の性能比較(簡易) 
PPT

PPTX

PDF
Similar to Introducing MySQL MHA (JP/LT)

KEY

PDF

PDF

PDF

PDF

PDF
JPUGしくみ+アプリケーション勉強会(第25回) 
PDF
大規模ソーシャルゲーム開発から学んだPHP&MySQL実践テクニック 
PDF

PDF
ゆるふわLinux-HA 〜PostgreSQL編〜 
PDF

PDF
PostgreSQLアーキテクチャ入門(PostgreSQL Conference 2012) 
PDF

PDF
PostgreSQLアーキテクチャ入門(INSIGHT OUT 2011) 
ODP
MySQl 5.6新機能解説@第一回 中国地方DB勉強会 
PDF
Pacemaker+PostgreSQLレプリケーションで共有ディスクレス高信頼クラスタの構築@OSC 2013 Tokyo/Spring 
PDF
MySQL Binlog Events でストリーム処理してみた #MySQLUC15 
PDF
サーバーが完膚なきまでに死んでもMySQLのデータを失わないための表技 
PDF
Yahoo! JAPANのプライベートRDBクラウドとマルチライター型 MySQL #dbts2017 #dbtsOSS 
PDF
Principles of Transaction Processing Second Edition 9章 4~9節 
PDF
5ステップで始めるPostgreSQLレプリケーション@hbstudy#13 More from Yoshinori Matsunobu

PDF
RocksDB Performance and Reliability Practices 
PPTX
Consistency between Engine and Binlog under Reduced Durability 
PDF
MyRocks introduction and production deployment 
PDF

PDF

PDF
MySQL for Large Scale Social Games 
PDF
Automated master failover 
PDF
Linux and H/W optimizations for MySQL 
PDF

PDF
More mastering the art of indexing 
PDF
SSD Deployment Strategies for MySQL 
PDF
Linux performance tuning & stabilization tips (mysqlconf2010) 
PPT
�Linux/DB Tuning (DevSumi2010, Japanese) Introducing MySQL MHA (JP/LT)
- 1.
MySQL Master HighAvailability
manager and tools (MySQL MHA)
株式会社 ディー・エヌ・エー
MySQL Geek, Oracle ACE Director
松信 嘉範 (MATSUNOBU Yoshinori)
Twitter: @matsunobu
1
- 2.
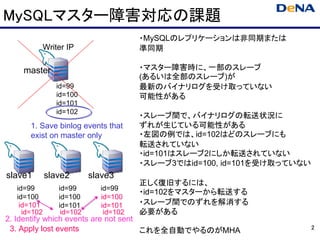
MySQLマスター障害対応の課題
・MySQLのレプリケーションは非同期または
Writer IP 準同期
master ・マスター障害時に、一部のスレーブ
(あるいは全部のスレーブ)が
id=99 最新のバイナリログを受け取っていない
id=100 可能性がある
id=101
id=102
・スレーブ間で、バイナリログの転送状況に
1. Save binlog events that ずれが生じている可能性がある
exist on master only ・左図の例では、id=102はどのスレーブにも
転送されていない
・id=101はスレーブ2にしか転送されていない
・スレーブ3ではid=100, id=101を受け取っていない
slave1 slave2 slave3
正しく復旧するには、
id=99 id=99 id=99
・id=102をマスターから転送する
id=100 id=100 id=100
id=101 id=101 id=101 ・スレーブ間でのずれを解消する
id=102 id=102 id=102 必要がある
2. Identify which events are not sent
3. Apply lost events 2
これを全自動でやるのがMHA
- 3.
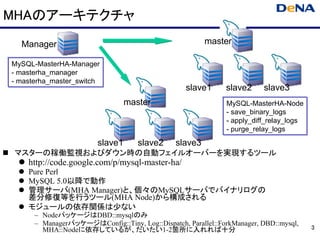
MHAのアーキテクチャ
Manager master
MySQL-MasterHA-Manager
- masterha_manager
- masterha_master_switch
slave1 slave2 slave3
master MySQL-MasterHA-Node
- save_binary_logs
- apply_diff_relay_logs
- purge_relay_logs
slave1 slave2 slave3
マスターの稼働監視およびダウン時の自動フェイルオーバーを実現するツール
http://code.google.com/p/mysql-master-ha/
Pure Perl
MySQL 5.0以降で動作
管理サーバ(MHA Manager)と、個々のMySQLサーバでバイナリログの
差分修復等を行うツール(MHA Node)から構成される
モジュールの依存関係は少ない
– NodeパッケージはDBD::mysqlのみ
– ManagerパッケージはConfig::Tiny, Log::Dispatch, Parallel::ForkManager, DBD::mysql,
MHA::Nodeに依存しているが、だいたい1-2箇所に入れれば十分 3
- 4.
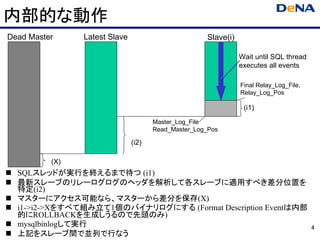
内部的な動作
Dead Master Latest Slave Slave(i)
Wait until SQL thread
executes all events
Final Relay_Log_File,
Relay_Log_Pos
(i1)
Master_Log_File
Read_Master_Log_Pos
(i2)
(X)
SQLスレッドが実行を終えるまで待つ (i1)
最新スレーブのリレーログログのヘッダを解析して各スレーブに適用すべき差分位置を
特定(i2)
マスターにアクセス可能なら、マスターから差分を保存(X)
i1->i2->Xをすべて組み立て1個のバイナリログにする (Format Description Eventは内部
的にROLLBACKを生成しうるので先頭のみ)
mysqlbinlogして実行 4
上記をスレーブ間で並列で行なう
- 5.
主要な拡張ポイント
shutdown_script
電源強制OFFなど
フェイルオーバーの直前に呼ばれる
master_ip_failover_script
マスターIPアドレスの更新(Virtual IPを更新したり、アプリケーション
から見ているマッピングテーブルを更新したり)
フェイルオーバーの直前と、マスター復旧後に呼ばれる
report_script: フェイルオーバーの可否と詳細情報をメール通
知したり
フェイルオーバーの終了後に呼ばれる
5
- 6.
ほかの方法との比較
Pacemaker +DRBDに対する優位性
スタンバイサーバが要らず、全サーバを有効活用できる
フェイルオーバー時間が高速(検知に10秒程度、切り替えに4秒程度)
– アクティブ/スタンバイ型ならクラッシュリカバリに1分単位は見ないといけない
既存環境にそのまま入れることができる
MySQL Cluster / Galeraに対する優位性
難しくない (当社比)
既存環境にそのまま入れることができる
MySQL-MMMに対する優位性
MySQL-MMMはそもそもHAソリューションではない
– 稼働監視のNW経路が1本しかない
– マスター障害の状況によっては高確率で切り替えが止まる
– 差分修復をしていない
– 多数のVirtual IPが必須
– 切り替えが連続して起こる可能性があり、それを防ぐ手段が無い
その他の特徴
任意のスレーブを新マスターにできる (最新でなくても)
フェイルバックをするのが面倒。障害マスターへの復旧には多くの場合作り直しが必要
– Fully durable settings (innodb_flush_log_at_trx_commit=1, innodb_support_xa=1
sync_binlog=1)でなければほかのHAソリューションでも同じ欠点がある 6
- 7.
FAQ
どこで使ってるの?
Mobageのサービスで全面的に使っています (150系統以上)
DeNAに入社すれば動いている様子が見れます
日本語のドキュメントは?
英語版を作って力尽きました
DeNAに入社すれば日本語版Wikiが見れます
テストケースが見当たらないんだけど
100個くらいあるんですが、まだ公開してません
DeNA環境依存のものは公開できないので。
DeNAに入社すれば見れます
拡張ポイントのサンプルコードが動かない
サンプルなので。
DeNAに入社すれば本番環境で動いてるものが見れます
* 興味のある方は(Matsunobu.Yoshinori@dena.jp or
Yoshinori.Matsunobu@gmail.com)にご連絡ください
7