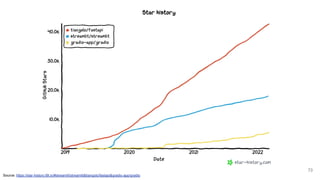
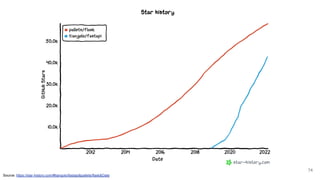
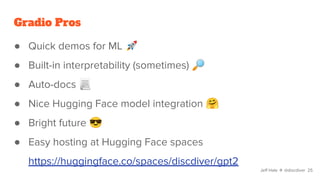
The document discusses various Python tools for deploying machine learning models faster, focusing on Gradio, Streamlit, and FastAPI. It provides demonstrations of each tool with examples such as creating interfaces for data visualization and model prediction, emphasizing the pros and cons of each framework. The presentation encourages users to choose tools based on their needs and suggests options for quick deployment and ease of use.










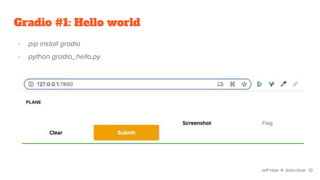
![Gradio #1: Hello world
import gradio as gr
def hello(plane):
return f"I'm an ultralight {plane} 🛩"
iface = gr.Interface(
fn=hello,
inputs=['text'],
outputs=['text']
).launch()
Jeff Hale ✈ @discdiver 11](https://image.slidesharecdn.com/pythontoolstodeployyourmachinelearningmodelsfaster-220309004940/85/Python-tools-to-deploy-your-machine-learning-models-faster-11-320.jpg)

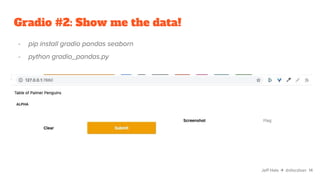
![Gradio #2: Show me the data!
def show_pens(alpha):
return pd.read_csv(
'https://raw.githubusercontent…/penguins.csv')
iface = gr.Interface(
fn=show_pens,
inputs=['text'],
outputs=[gr.outputs.Dataframe()],
description="Table of Palmer Penguins"
).launch(share=True)
Jeff Hale ✈ @discdiver 13](https://image.slidesharecdn.com/pythontoolstodeployyourmachinelearningmodelsfaster-220309004940/85/Python-tools-to-deploy-your-machine-learning-models-faster-13-320.jpg)


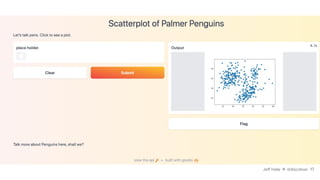
![Gradio #3: Plot it
def plot_pens(place_holder):
"""scatter plot penguin chars using matplotlib"""
df_pens = pd.read_csv("https://raw.githubuser…/penguins.csv")
fig = plt.figure()
plt.scatter(
x=df_pens["bill_length_mm"], y=df_pens["bill_depth_mm"])
return fig
Jeff Hale ✈ @discdiver 18](https://image.slidesharecdn.com/pythontoolstodeployyourmachinelearningmodelsfaster-220309004940/85/Python-tools-to-deploy-your-machine-learning-models-faster-18-320.jpg)
![Gradio #3: Plot it
iface = gr.Interface(
fn=plot_pens,
layout="vertical",
inputs=["checkbox"],
outputs=["plot"],
title="Scatterplot of Palmer Penguins",
description="Let's talk pens. Click to see a plot.",
article="Talk more about Penguins here, shall we?",
theme="peach",
live=True,
).launch()
Jeff Hale ✈ @discdiver 19](https://image.slidesharecdn.com/pythontoolstodeployyourmachinelearningmodelsfaster-220309004940/85/Python-tools-to-deploy-your-machine-learning-models-faster-19-320.jpg)













![Streamlit #3: Plotting
choice = st.radio("Select color", ["species", "island"])
fig = px.scatter_3d(
data_frame=df_pens,
x="bill_depth_mm",
y="bill_length_mm",
z="body_mass_g",
color=choice,
title="Penguins in 3D!",
)
fig Jeff Hale ✈ @discdiver 36](https://image.slidesharecdn.com/pythontoolstodeployyourmachinelearningmodelsfaster-220309004940/85/Python-tools-to-deploy-your-machine-learning-models-faster-36-320.jpg)

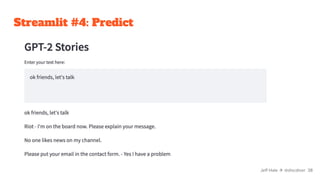
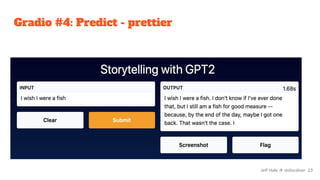
![Streamlit #4: Predict
import streamlit as st
from transformers import pipeline
st.header("GPT-2 Stories")
input_text = st.text_area("Enter your text here:")
generator = pipeline("text-generation", model="gpt2")
output = generator(input_text, max_length=100)
output[0]["generated_text"]
Jeff Hale ✈ @discdiver 39](https://image.slidesharecdn.com/pythontoolstodeployyourmachinelearningmodelsfaster-220309004940/85/Python-tools-to-deploy-your-machine-learning-models-faster-39-320.jpg)

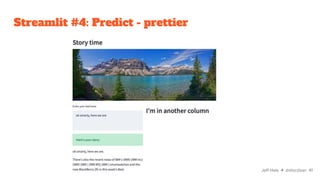
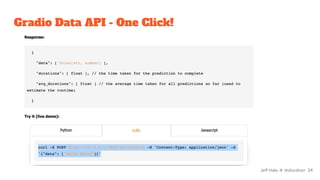
![Streamlit #4: Predict - prettier
st.header("Story time")
st.image("https://cdn.pixabay.com/photo/2017/07/12/19/03/highway-2497900_960_720.jpg")
col1, col2 = st.columns(2)
with col1:
input_text = st.text_area("Enter your text here:")
with st.spinner("Generating story..."):
generator = pipeline("text-generation", model="gpt2")
if input_text:
generated_text = generator(input_text, max_length=60)
st.success("Here's your story:")
generated_text[0]["generated_text"]
with col2:
st.header("I'm in another column") Jeff Hale ✈ @discdiver 42](https://image.slidesharecdn.com/pythontoolstodeployyourmachinelearningmodelsfaster-220309004940/85/Python-tools-to-deploy-your-machine-learning-models-faster-42-320.jpg)