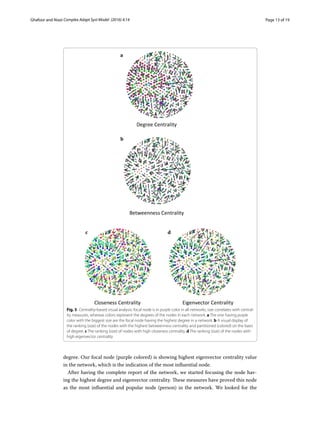
The document proposes a methodology for using social network analysis to better understand human behaviors and elicit software requirements for online social networks. It begins with background on online social networks and their failures. It then outlines a novel methodology involving collecting real-world social network data through questionnaires, analyzing the network's structural characteristics like centrality measures, and examining how friendship strength and everyday habits are associated. The case study found unexpected centrality results and demonstrated how social network analysis can provide insights for improved software requirement elicitation.