Download to read offline

















![Feature EngineeringTrials
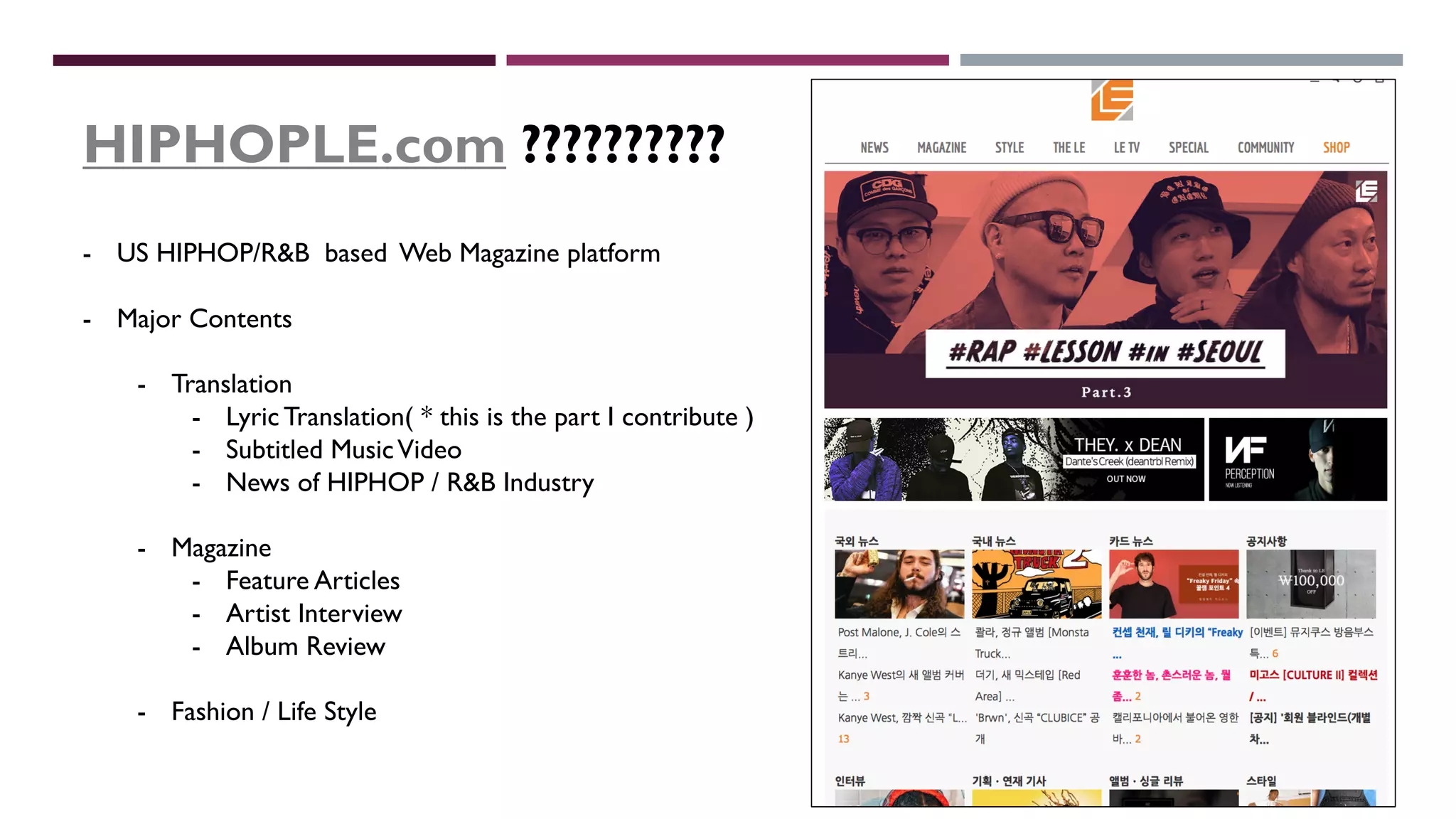
Feature Type Descriptions
Performance
Improvement
Genre One-Hot Encoding Create DummyVariable with One-Hot Encoding O
Ratings NullValue Imputation
Fill in “ 0 ” rating score for the album that didn’t
received any ratings
O
Buzz
Rating
SNS Followers
Binning
- Binning the range of numeric values
- Create DummyVariables for each bin
X
SNS Followers Ratio
- [ Follower of Each SNS /Total Followers ]
- Calculate Ratio for each SNS platform
X
SNS Followers Re-Grouping
- Private SNS (Twitter, Instagram)
- Page & Channel based SNS (Facebook,Youtube)
- Music based SNS (Soundcloud, Spotify)
X](https://image.slidesharecdn.com/projectovervieweng-180511161523/75/Project-overview-eng-23-2048.jpg)

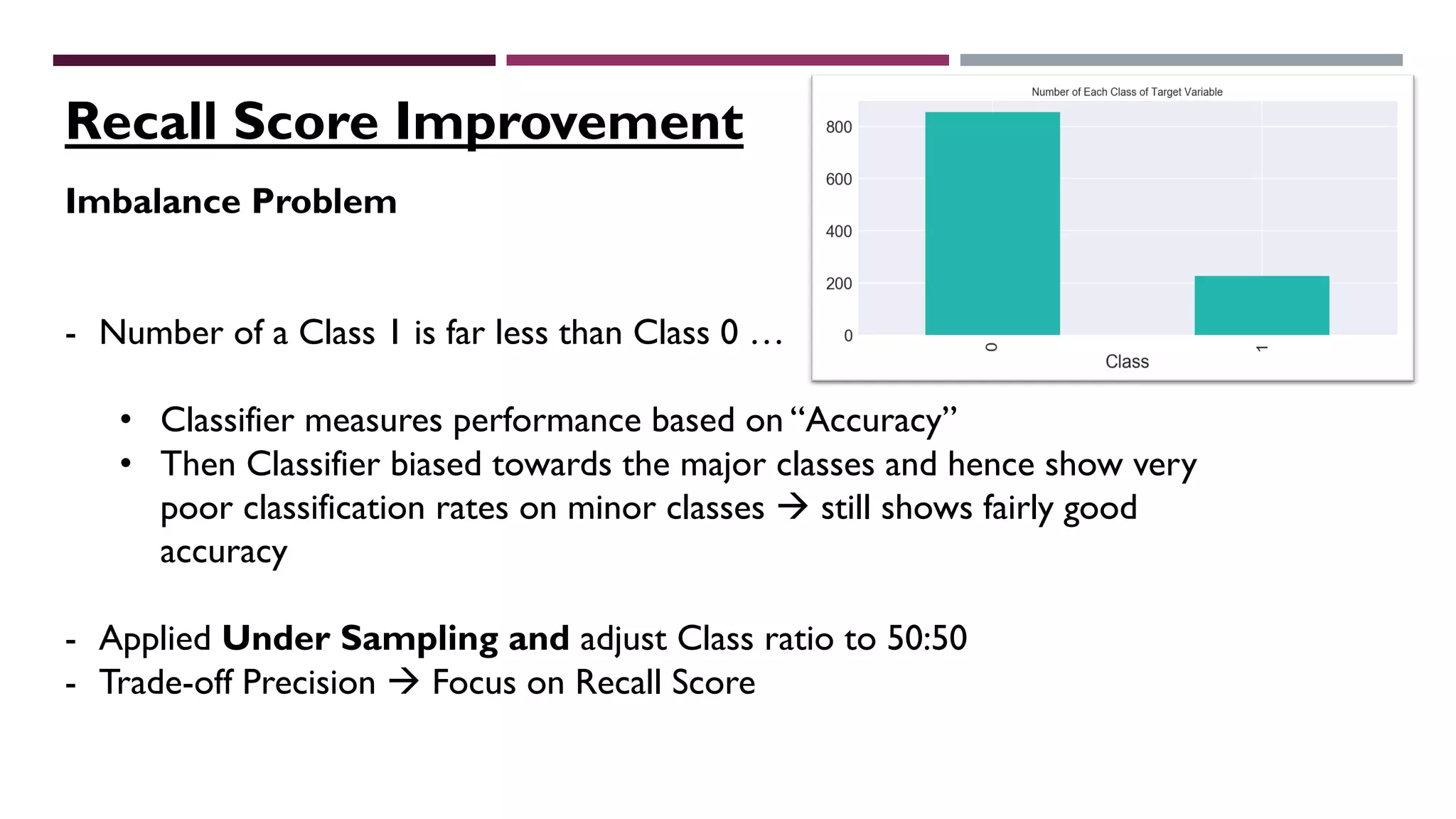
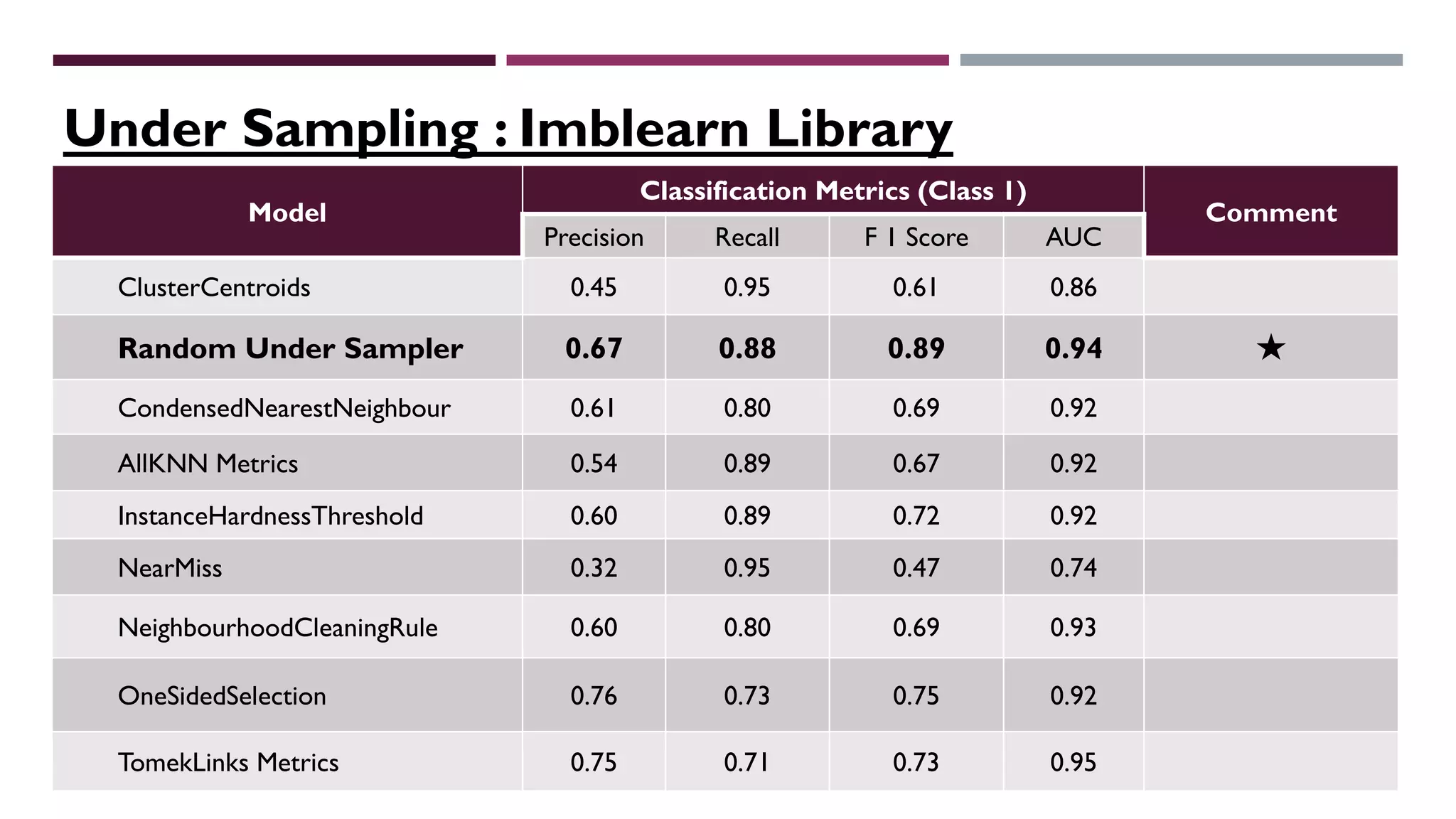
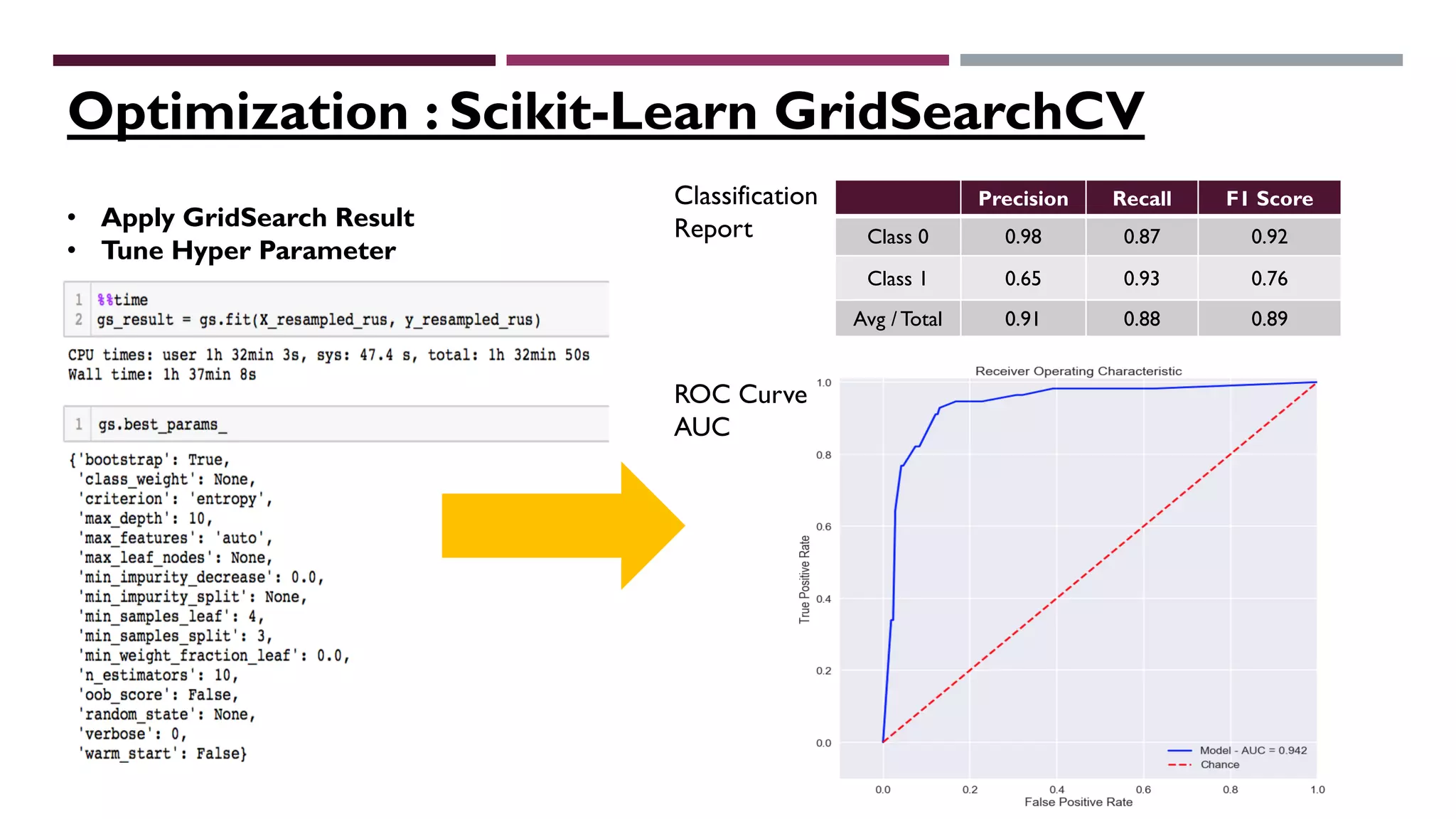

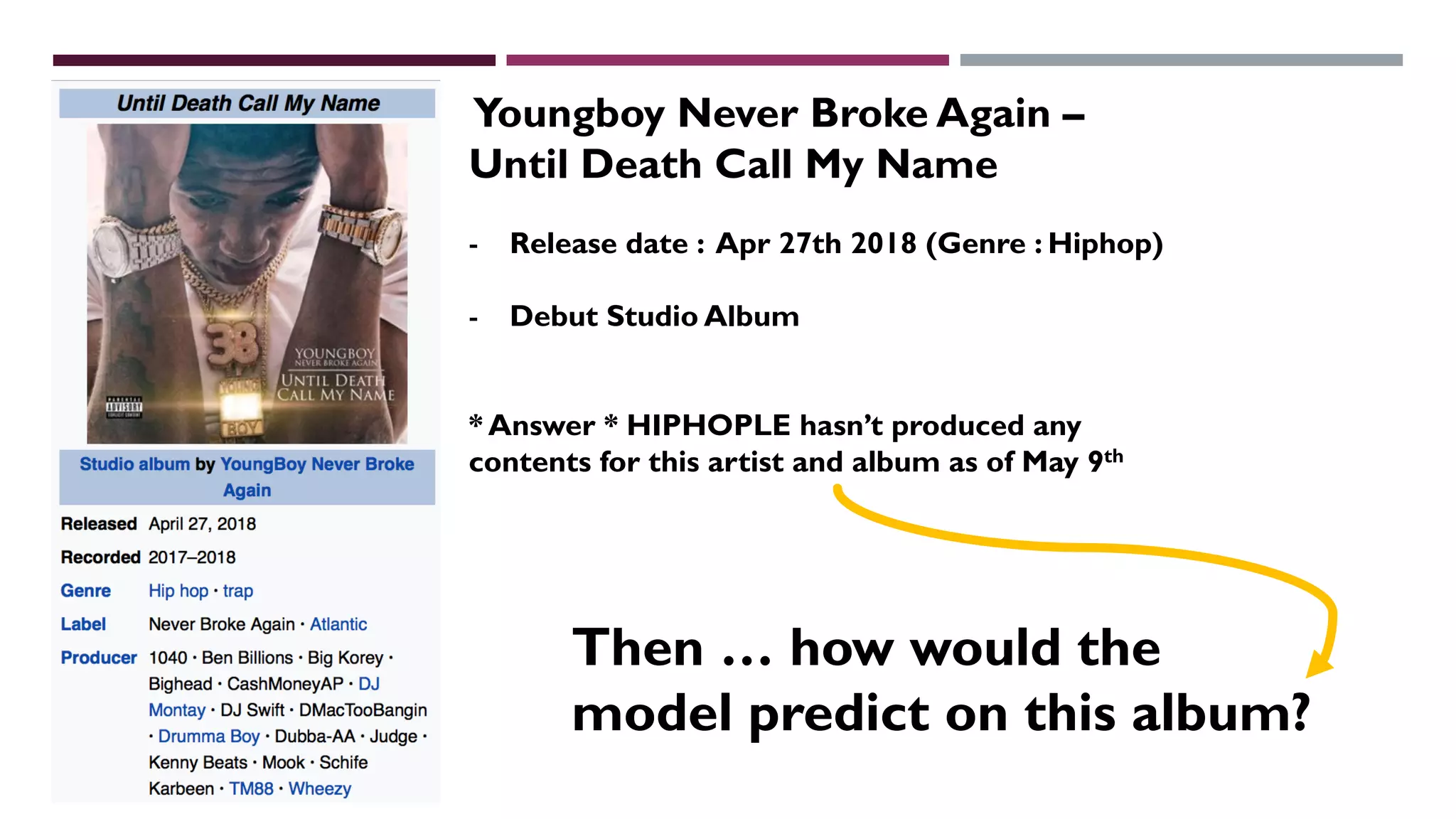
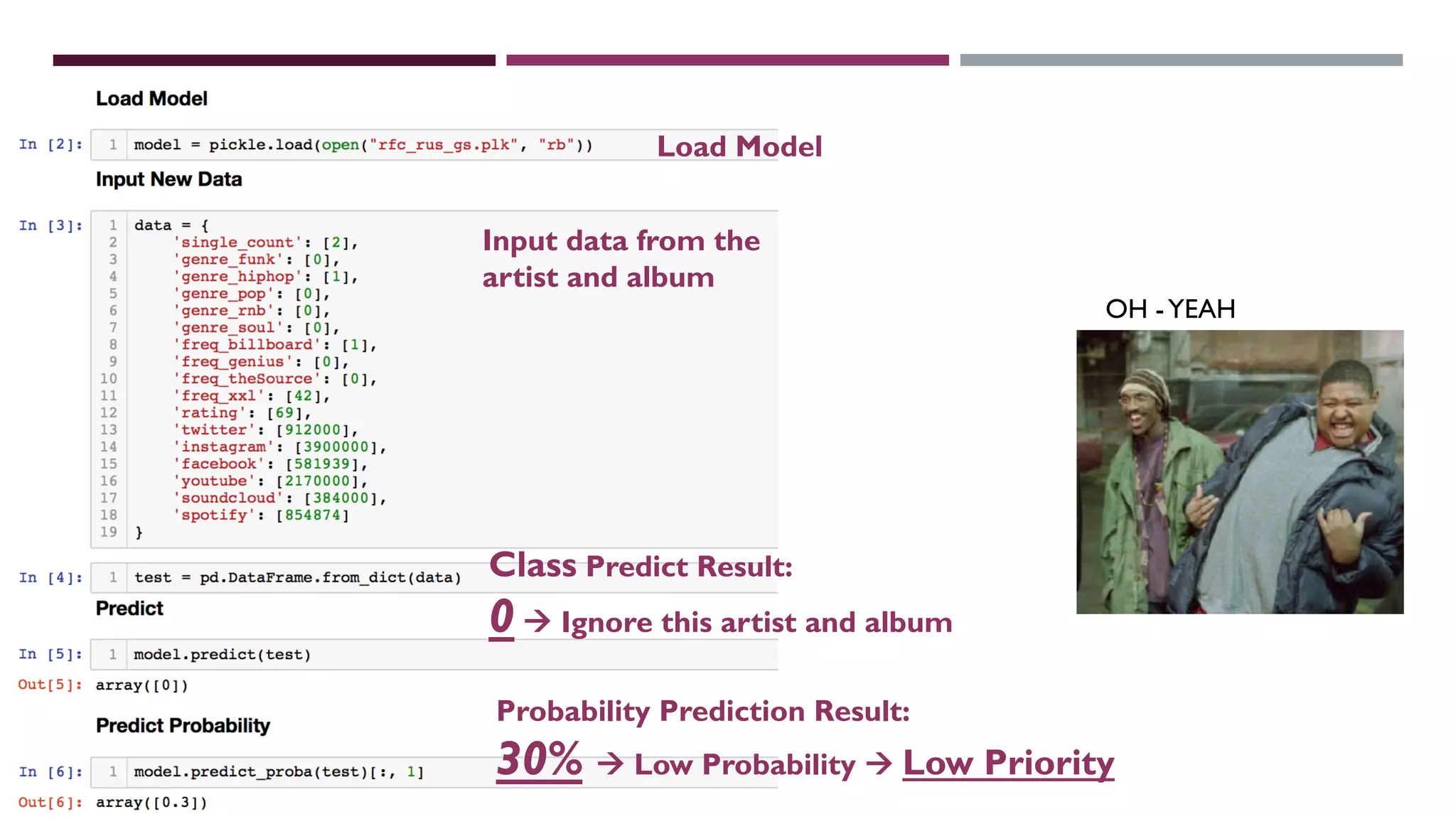





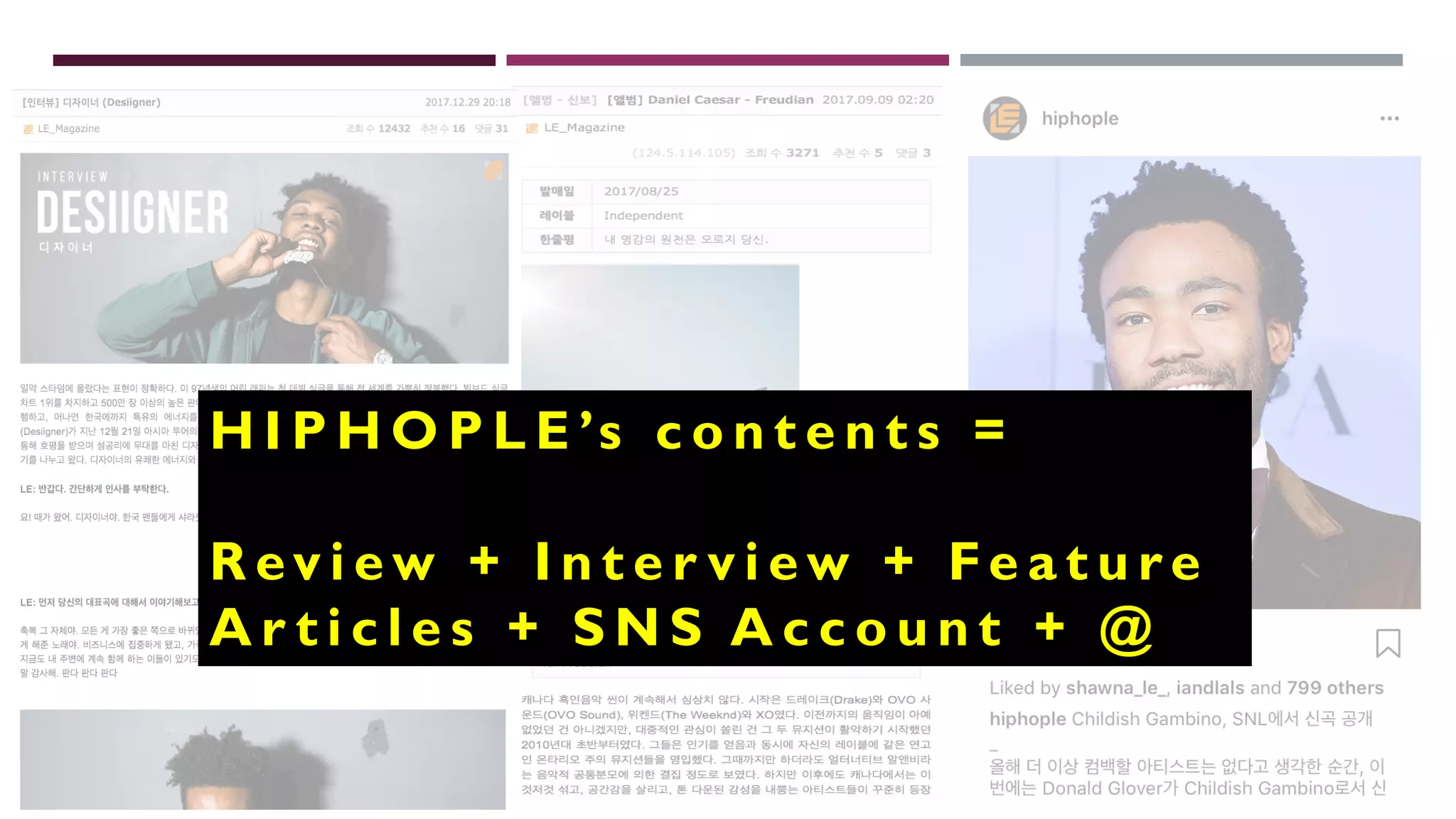
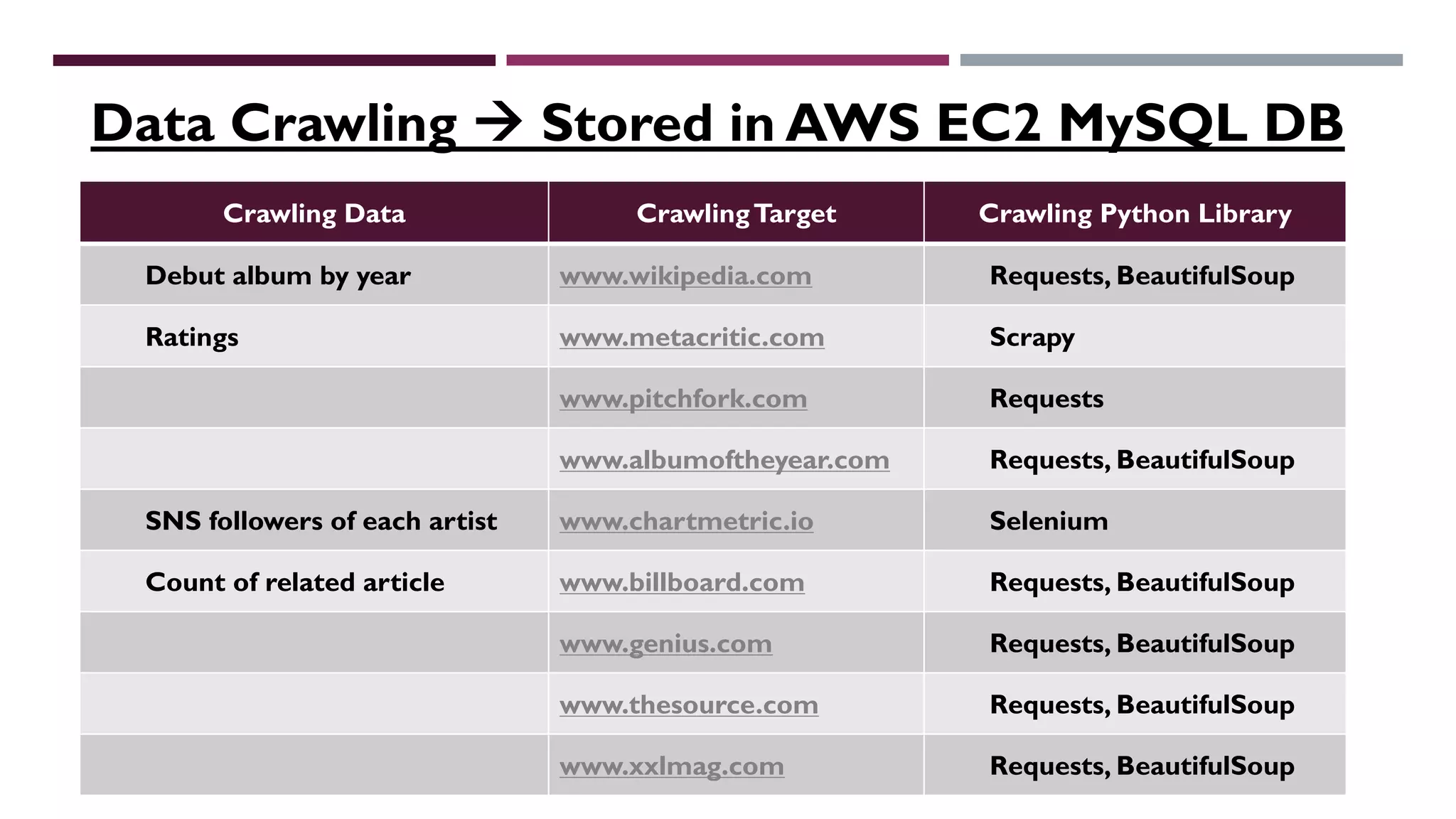
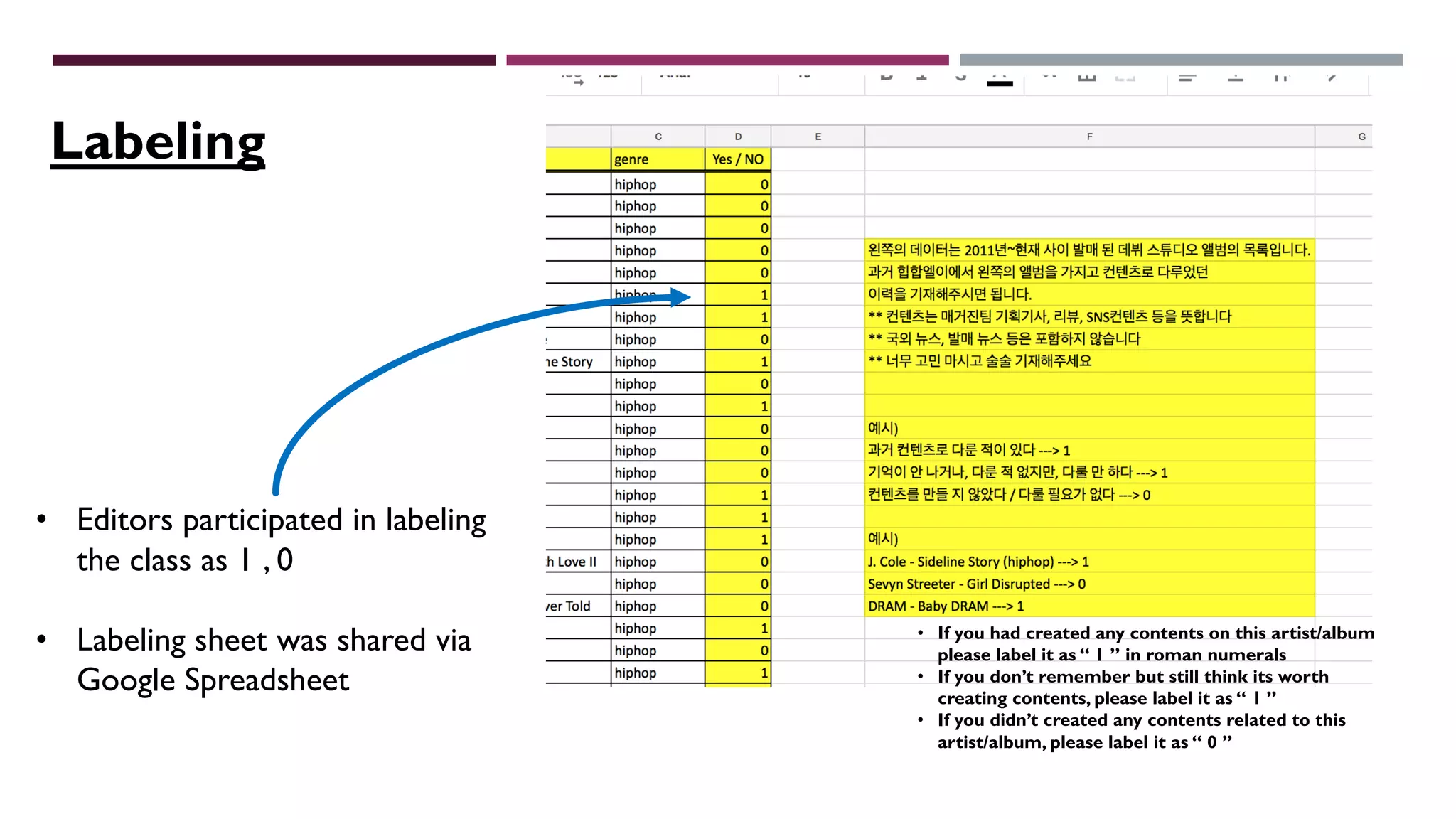
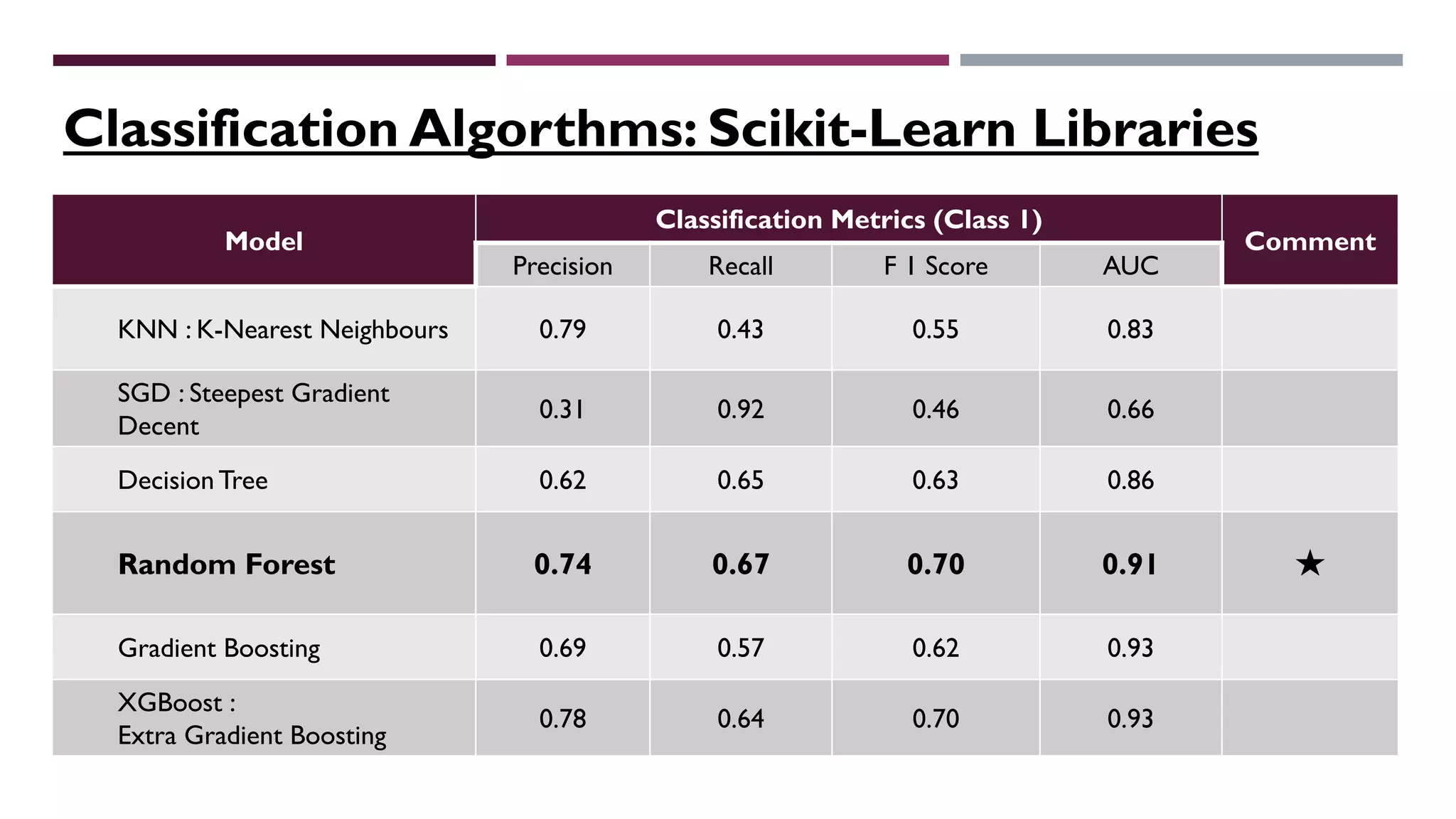
This document describes a machine learning project to classify debut artists as "worth creating content for" or "ignore" based on their attributes. The project uses a random forest classifier trained on data crawled from various music media sites. Features include genre, ratings, social media followers, and number of related articles. The random forest model achieved an F1 score of 0.7 and AUC of 0.91 for the "worth creating content" class. Further improvements could include handling data imbalances and integrating text analysis. A web app was also created to automate predictions.

















































![[DSC Europe 25] Danica Soc - The Science Behind Marketing: Experimentation me...](https://cdn.slidesharecdn.com/ss_thumbnails/c0nofsggs9gw5ucmallr-3-251216103155-56bd64d1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)