This project report focuses on the association rule-apriori algorithm, a significant method in data mining for discovering relationships among items in large datasets. It provides an overview of the algorithm's principles, optimization techniques, implementations, and its applications in various domains like retail and healthcare. The report includes detailed discussions on support, confidence, and lift metrics, along with challenges and future directions in the field of association rule mining.
![ASSOCIATION RULE-APPRIORI ALGORITHM
A PROJECT REPORT
Submitted by
Vastav [Reg No: RA21003010093]
Sampath Kumar[RA2111003010109]
Under the Guidance of
DR. S. BABU
Associate Professor, Department of Data Science and Business Systems
In partial fulfilment of the requirements for the degree of
BACHELOR OF TECHNOLOGY in COMPUTER SCIENCE
AND ENGINEERING
SCHOOL OF COMPUTING
COLLEGE OF ENGINEERING AMD TECHNOLOGY
SRM INSTITUTE OF SCIENCE AND TECHNOLOGY
(under section 3 of UGC Act,1956)
S.R.M NAGAR, KATTANKULATHUR-603203 CHENGALPATTU
DISTRICT
APRIL 2024](https://image.slidesharecdn.com/project-10993-240712031038-ec594879/75/PROJECT-109-93-pdf-data-miiining-project-1-2048.jpg)

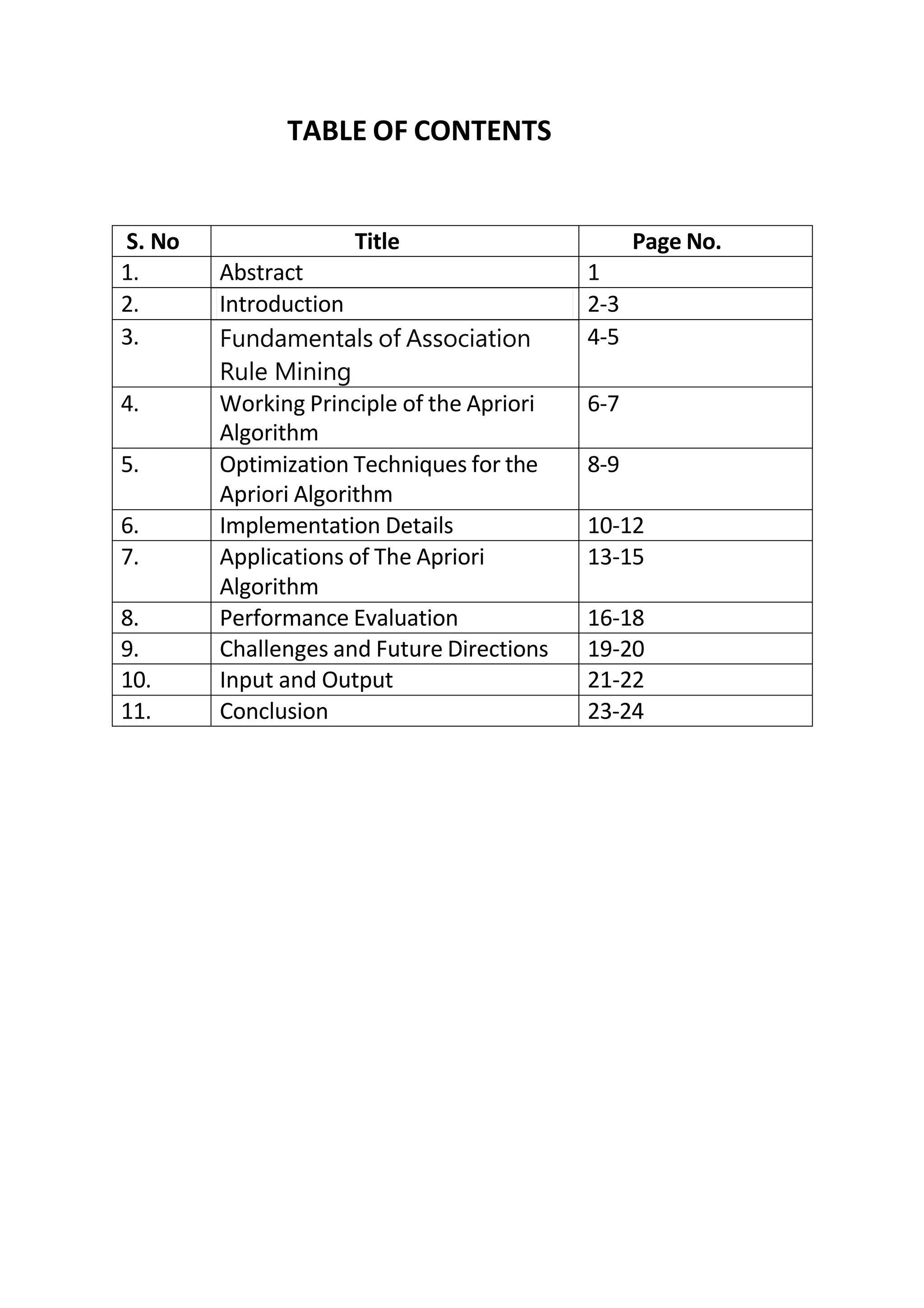




















![Best rules found:
1. outlook=overcast 4 ==> play=yes 4 <conf:(1)> lift:(1.56) lev:(0.1) [1] conv:(1.43)
2. temperature=cool 4 ==> humidity=normal 4 <conf:(1)> lift:(2) lev:(0.14) [2] conv:(2)
3. humidity=normal windy=FALSE 4 ==> play=yes 4 <conf:(1)> lift:(1.56) lev:(0.1) [1]
conv:(1.43)
4. outlook=sunny play=no 3 ==> humidity=high 3 <conf:(1)> lift:(2) lev:(0.11) [1] conv:(1.5)
5. outlook=sunny humidity=high 3 ==> play=no 3 <conf:(1)> lift:(2.8) lev:(0.14) [1]
conv:(1.93)](https://image.slidesharecdn.com/project-10993-240712031038-ec594879/75/PROJECT-109-93-pdf-data-miiining-project-24-2048.jpg)

















































