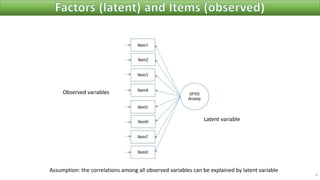
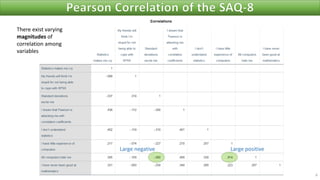
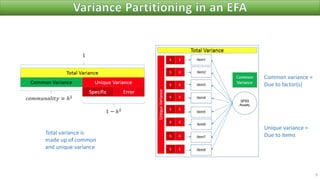
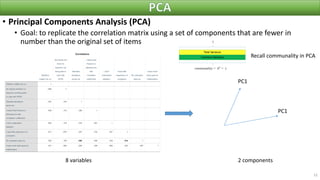
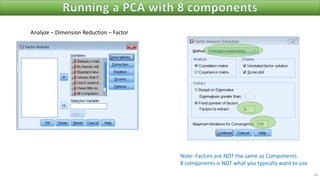
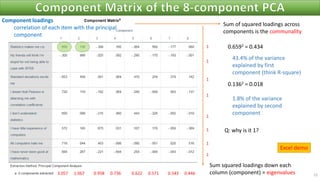
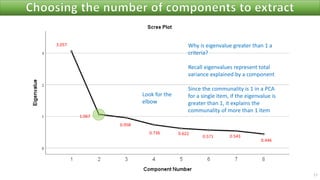
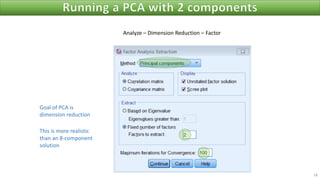
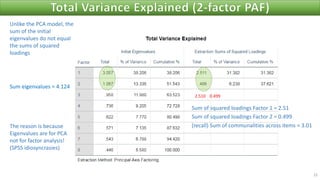
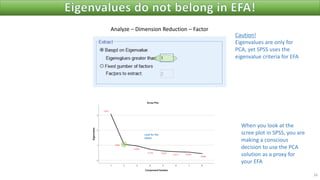
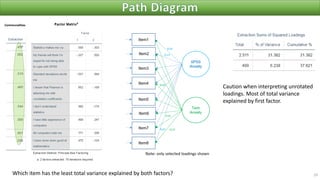
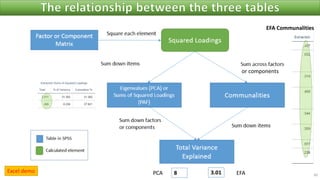
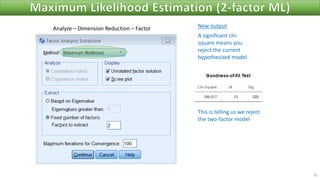
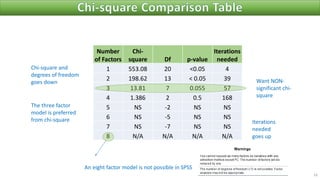
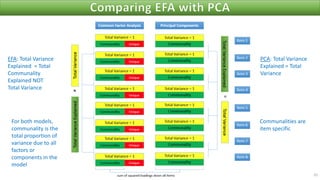
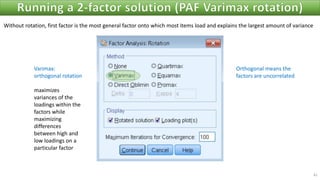
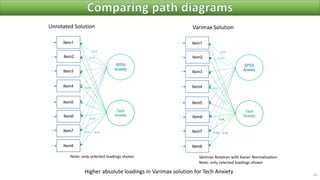
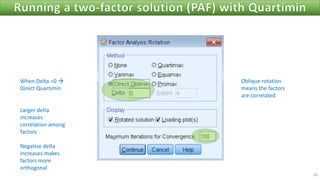
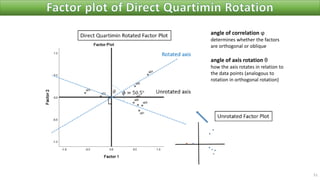
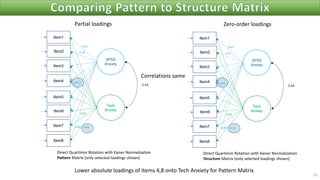
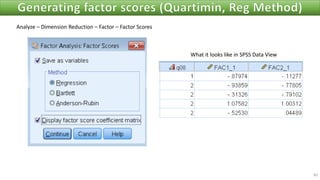
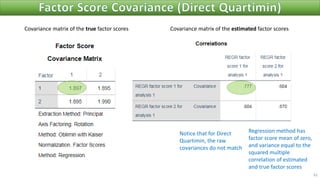
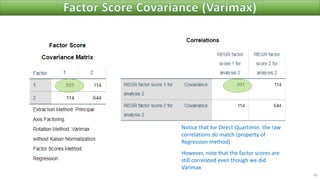
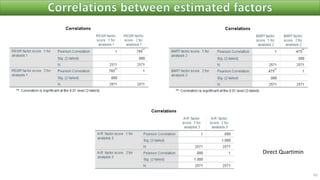
The document discusses factor analysis techniques in SPSS, specifically focusing on Principal Components Analysis (PCA) and Exploratory Factor Analysis (EFA). It covers the extraction of factors, the variance explained by components, the importance of eigenvalues, and methods for achieving simple structure through rotation. Additionally, it highlights differences between PCA and EFA, item loadings, and the interpretation of factor scores and matrices.