Download as PDF, PPTX
































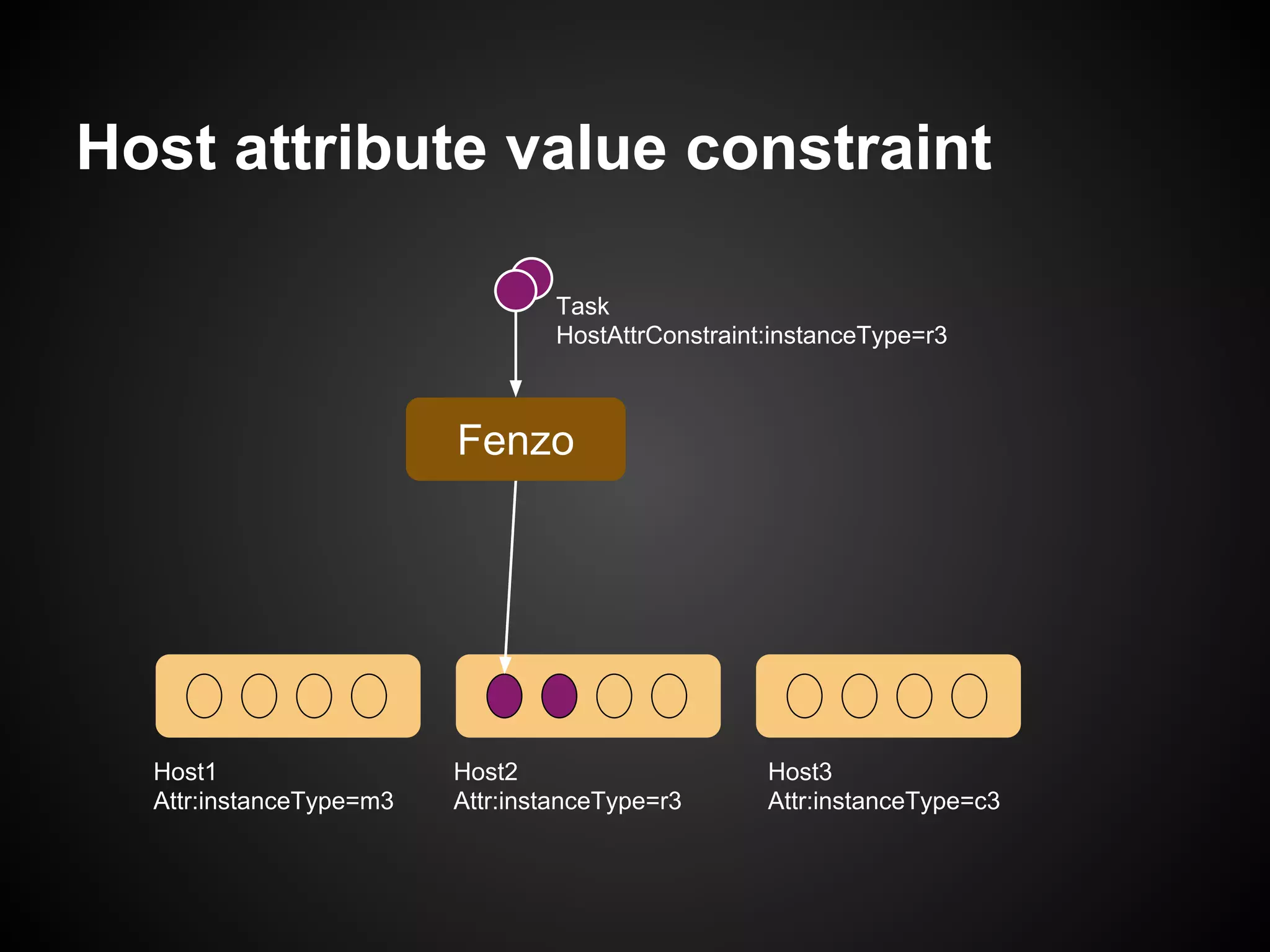
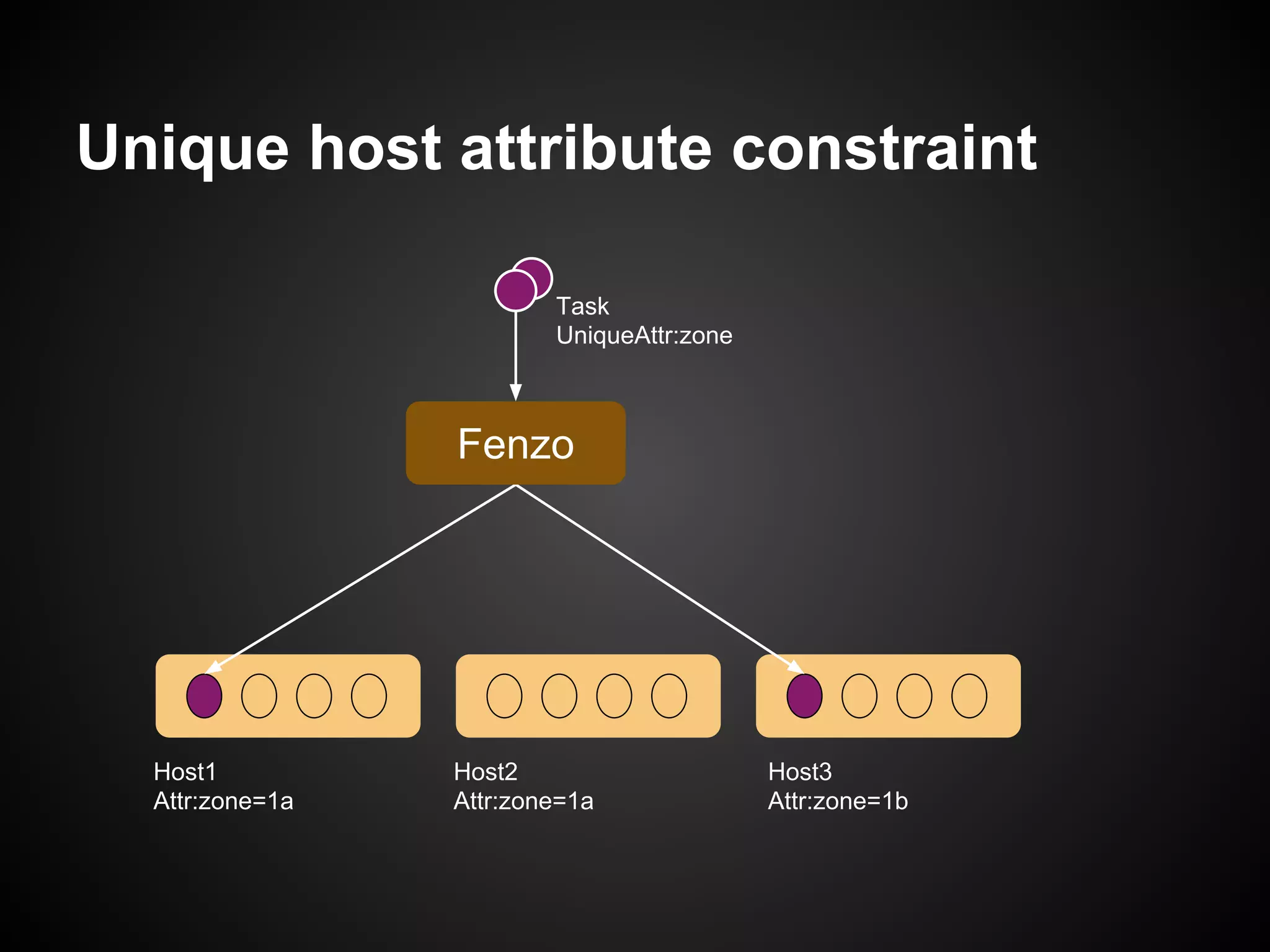
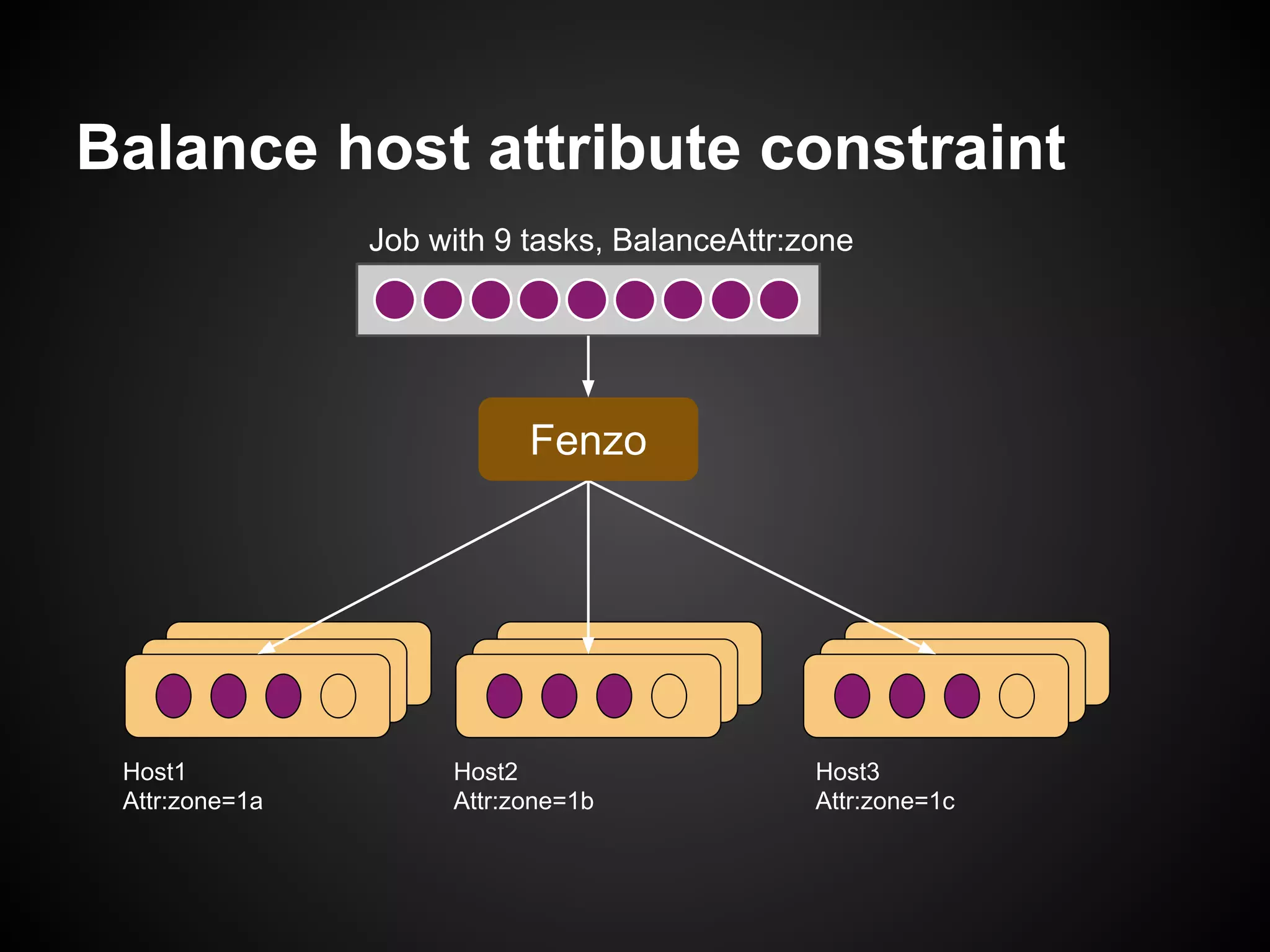














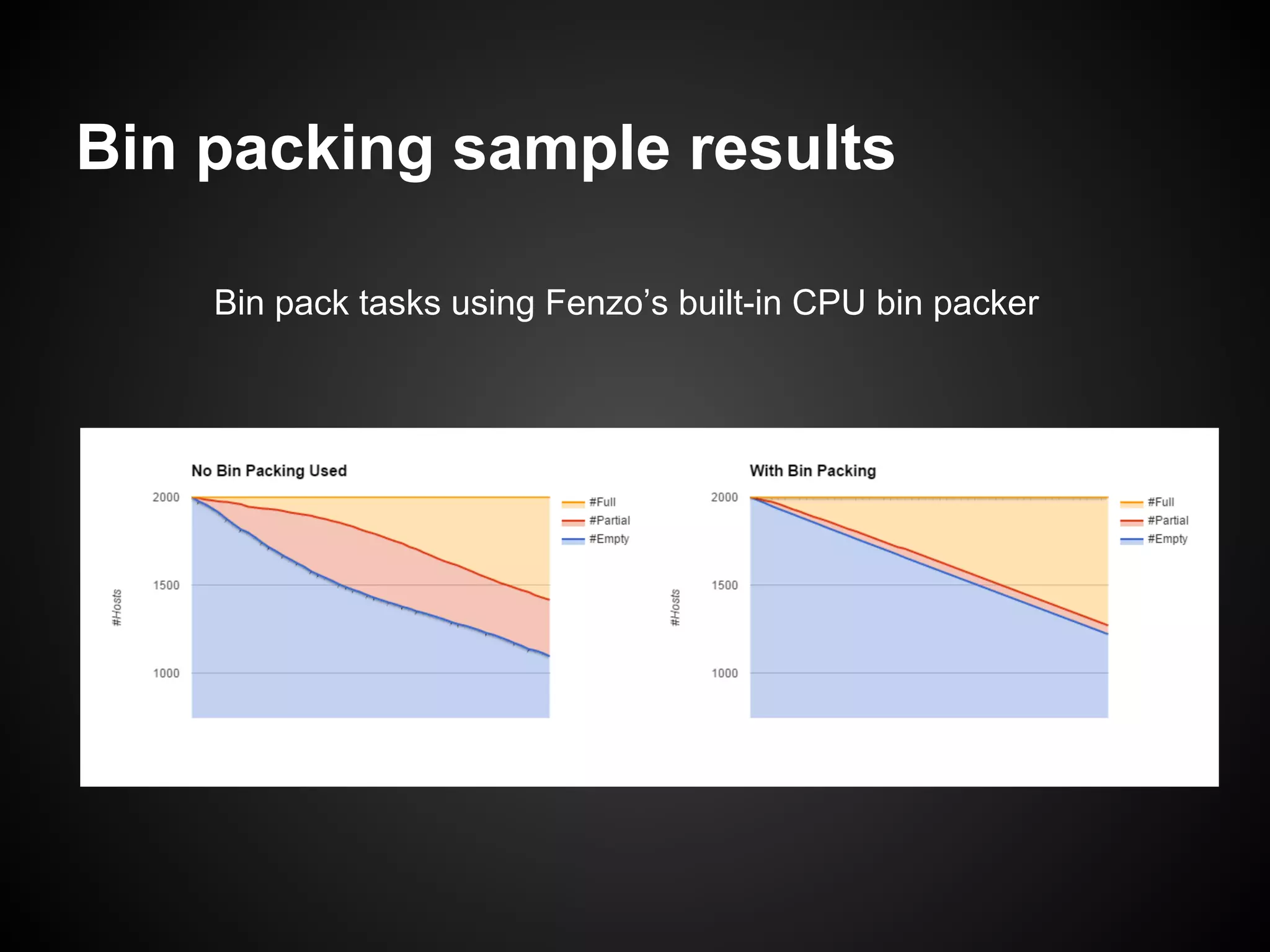



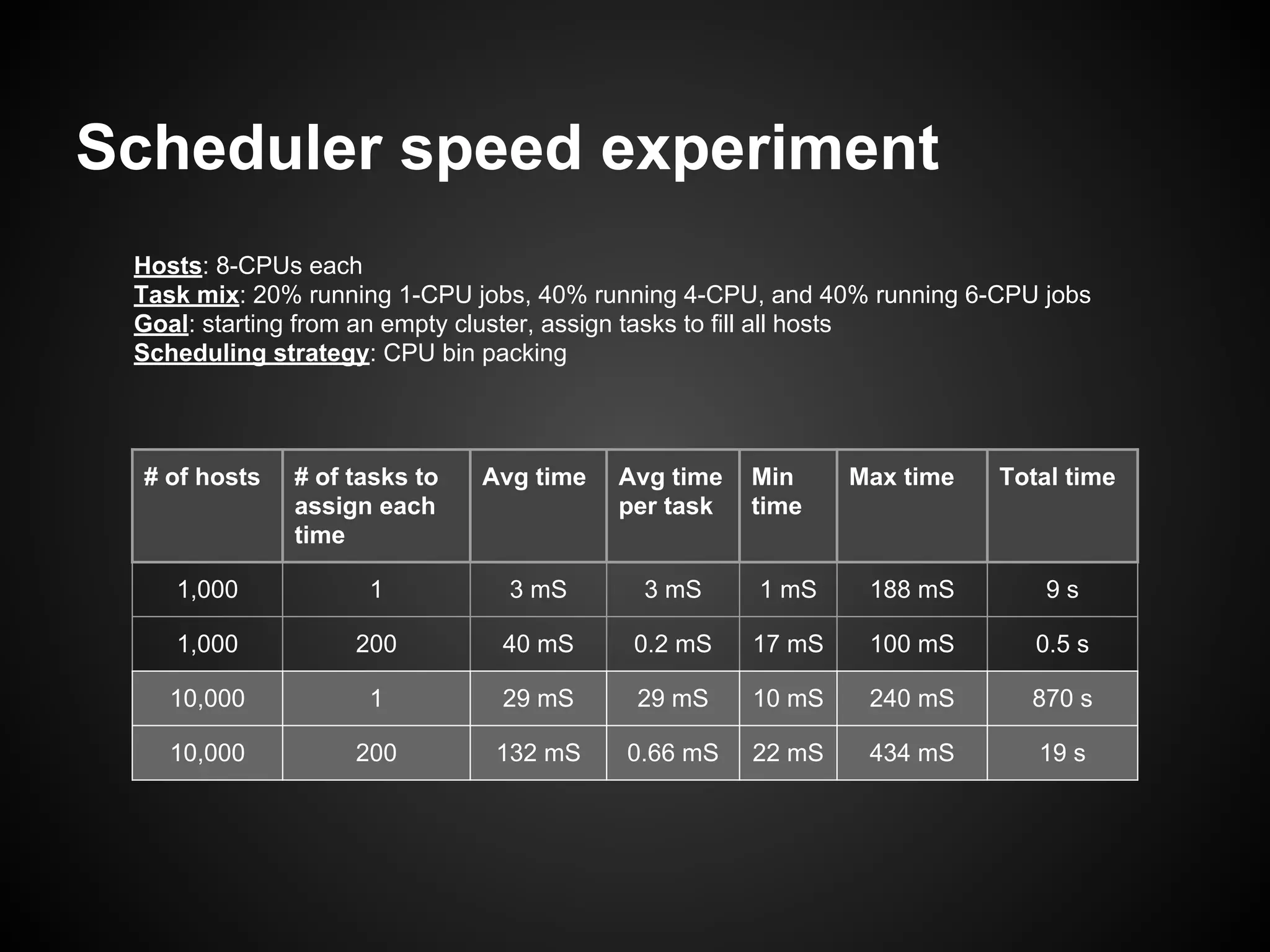







The document discusses the use of Apache Mesos for heterogeneous resource scheduling in cloud-native frameworks, focusing on the Fenzo scheduler library utilized by Netflix. It highlights Fenzo's capabilities, including resource granularity, task placement constraints, and cluster autoscaling strategies, while addressing the challenges of developing a new framework for handling diverse workloads. The document also provides insights into the library's performance metrics, scheduling optimizations, and future directions for enhancing task management and integrating new Mesos features.


































































