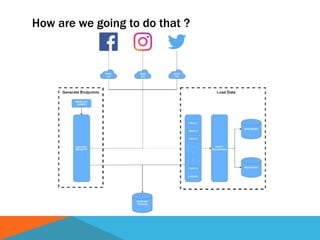
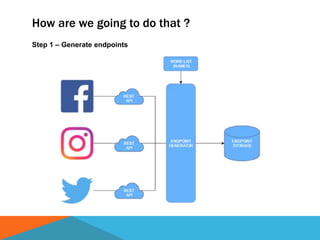
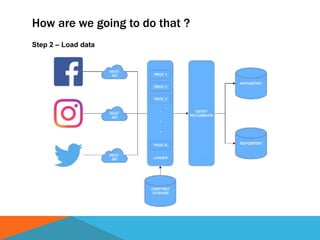
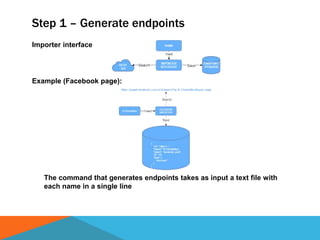
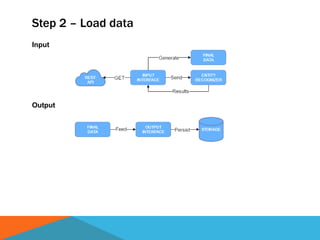
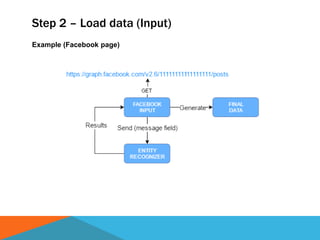
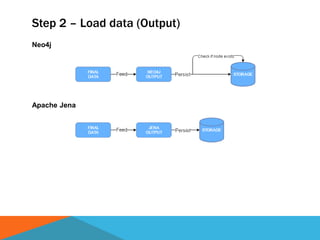
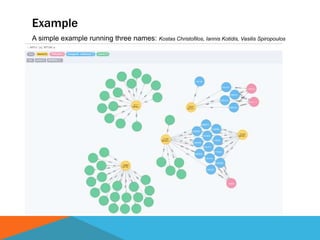
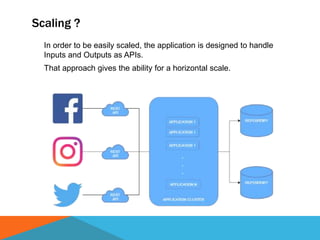
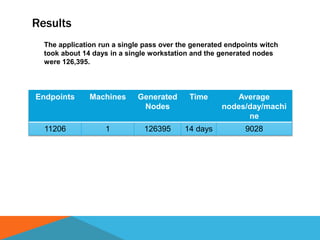
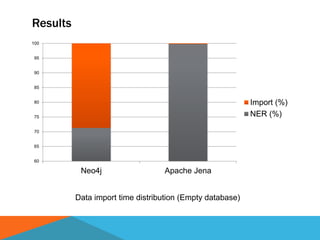
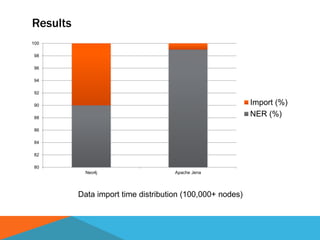
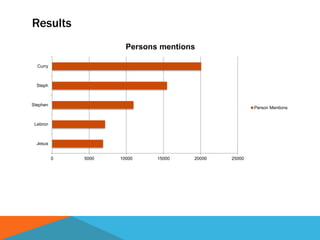
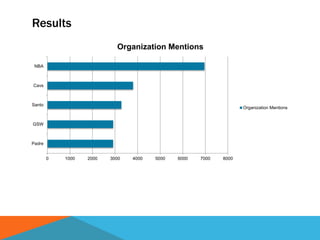
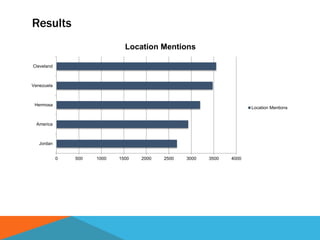
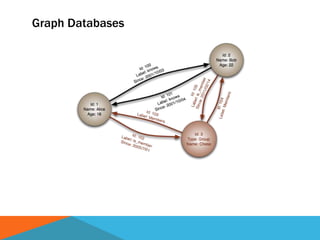
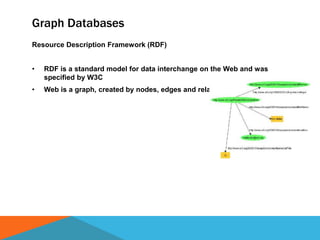
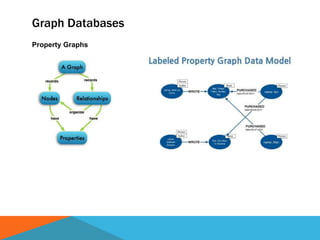
The document discusses a system designed to gather and analyze data from various APIs by creating a repository of mixed services data. It outlines a step-by-step process for generating endpoints, loading data, and recognizing entities, resulting in comprehensive databases using technologies like Neo4j and Apache Jena. Additionally, it highlights the potential for future extensions, such as incorporating new APIs and implementing centralized logging for better monitoring.