Download to read offline




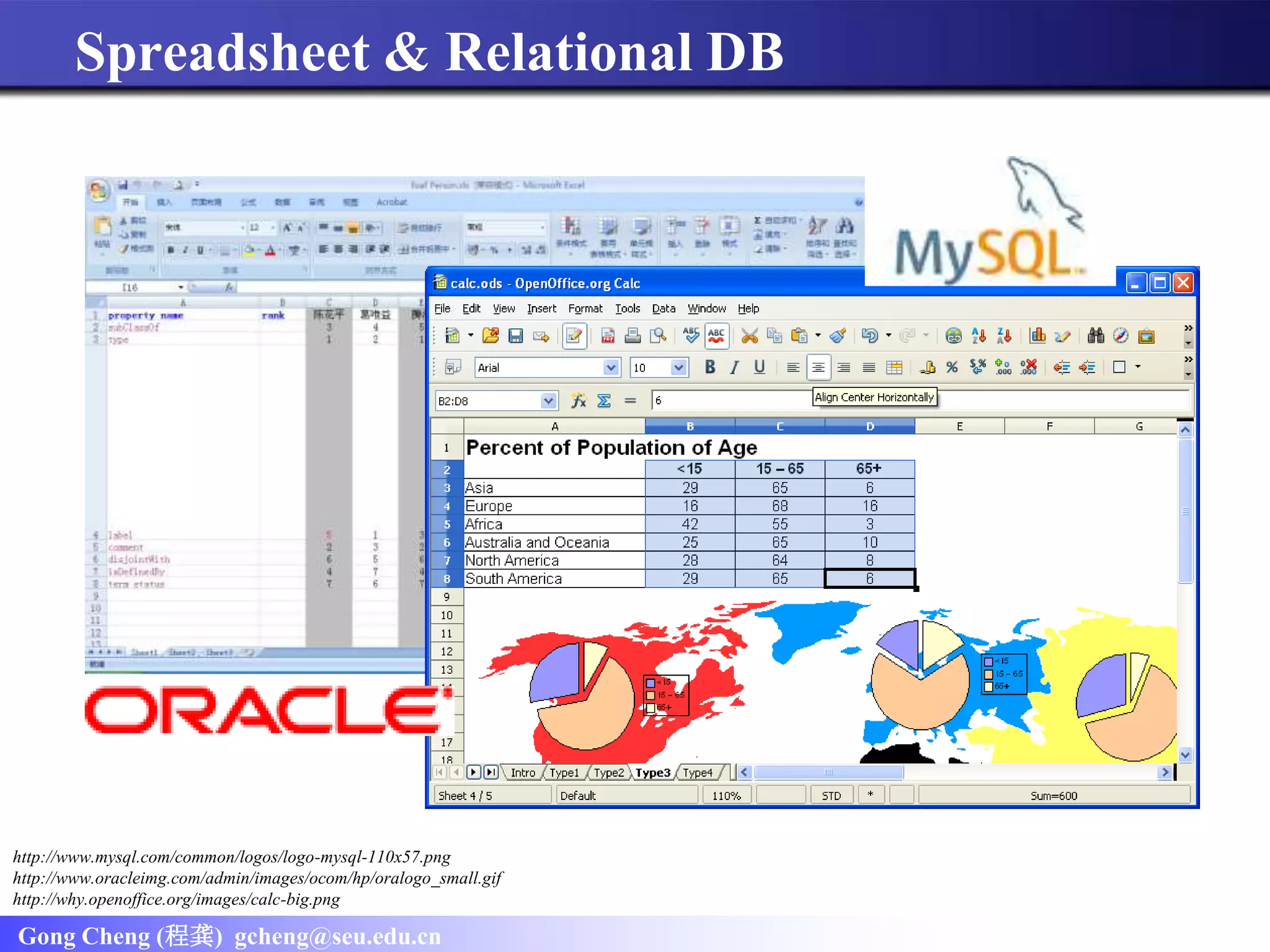





Falcons Explorer is a tool designed for end-user programming that facilitates the exploration of RDF data using a tabular and relational interface. It aims to make working with RDF data as accessible as using spreadsheets or relational databases, addressing the gap in user familiarity with RDF. The tool allows users to browse, search, and query RDF data similarly to traditional database management systems.
















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)


















