Download as PDF, PPTX



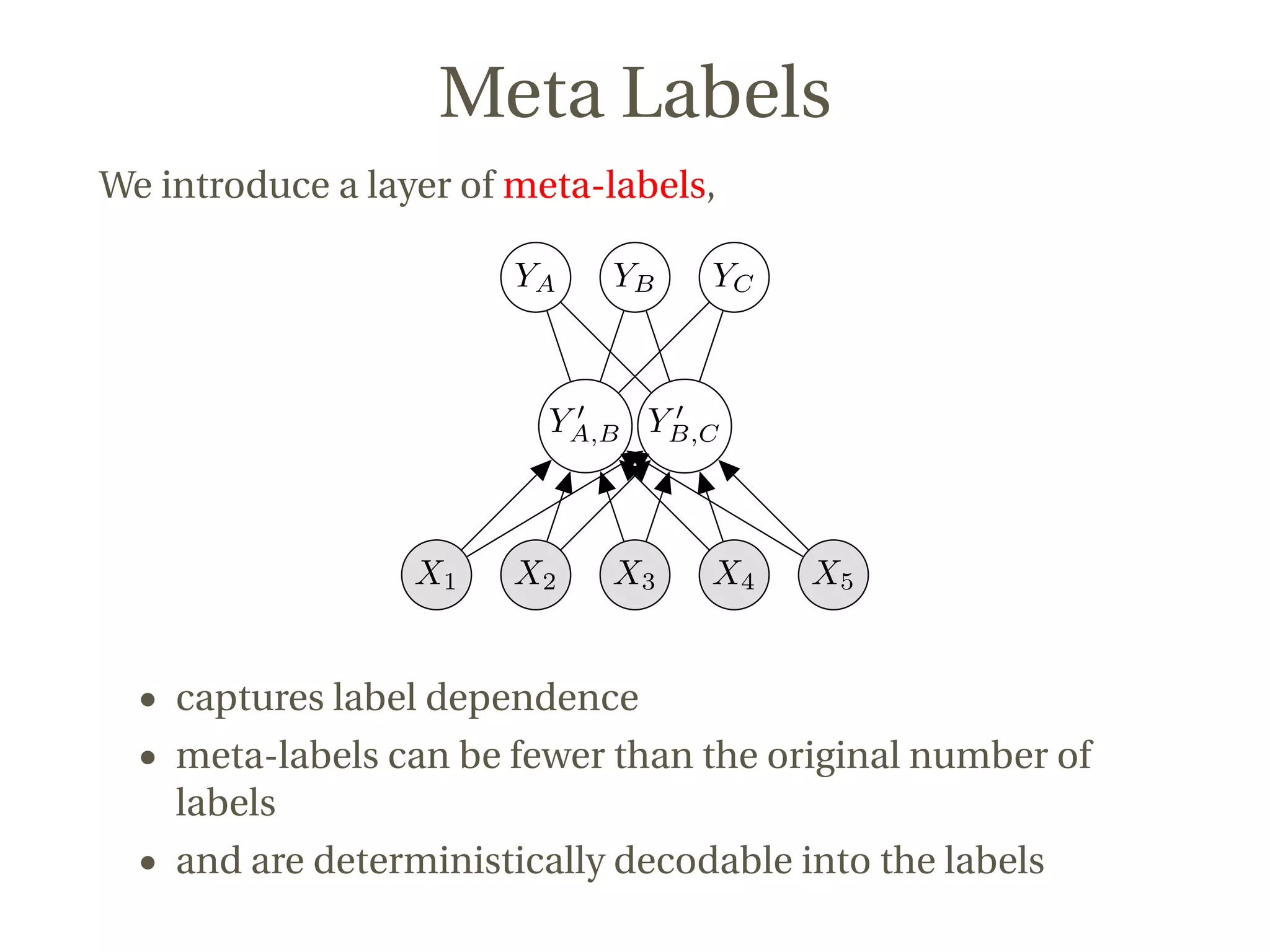
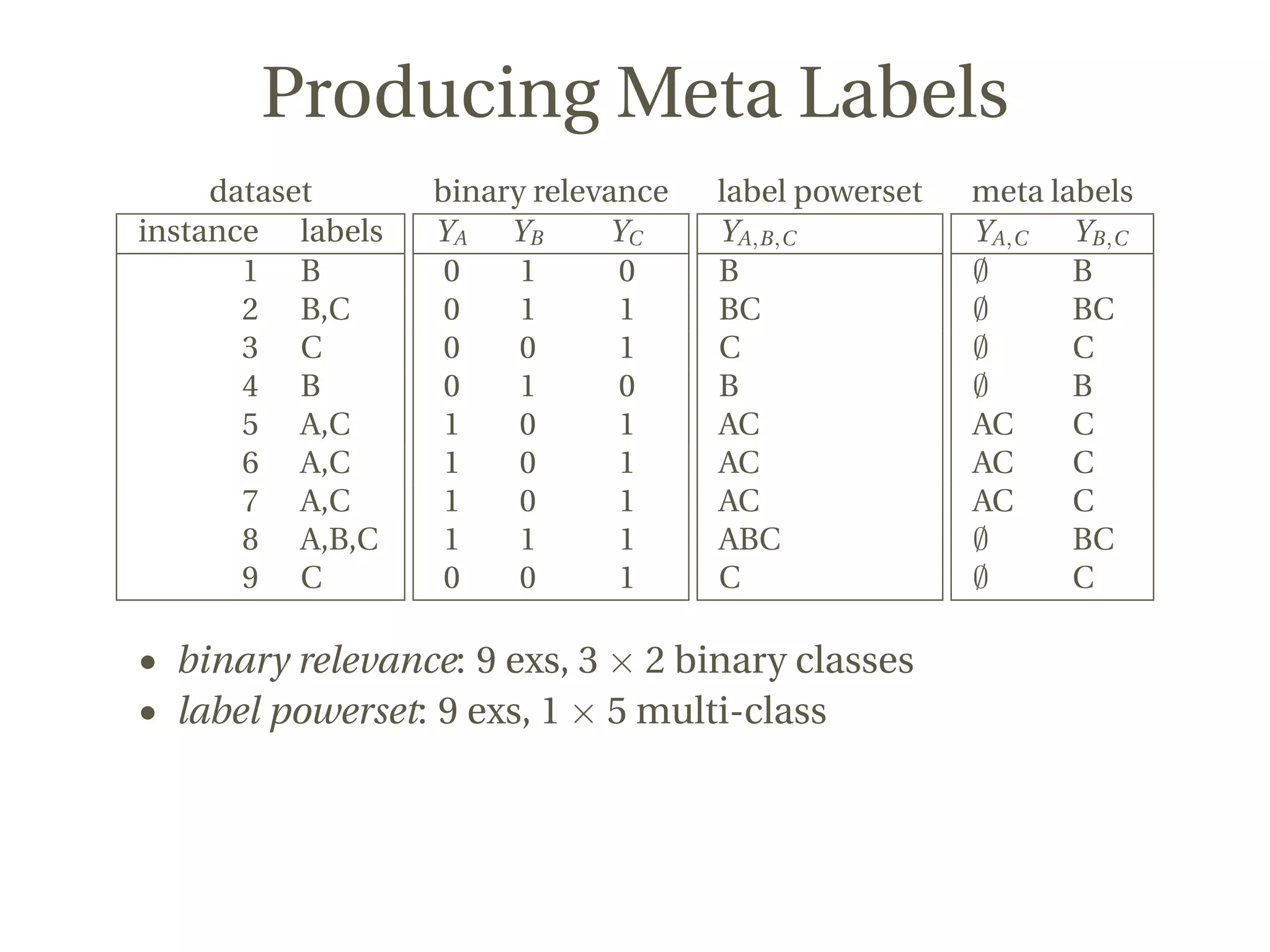

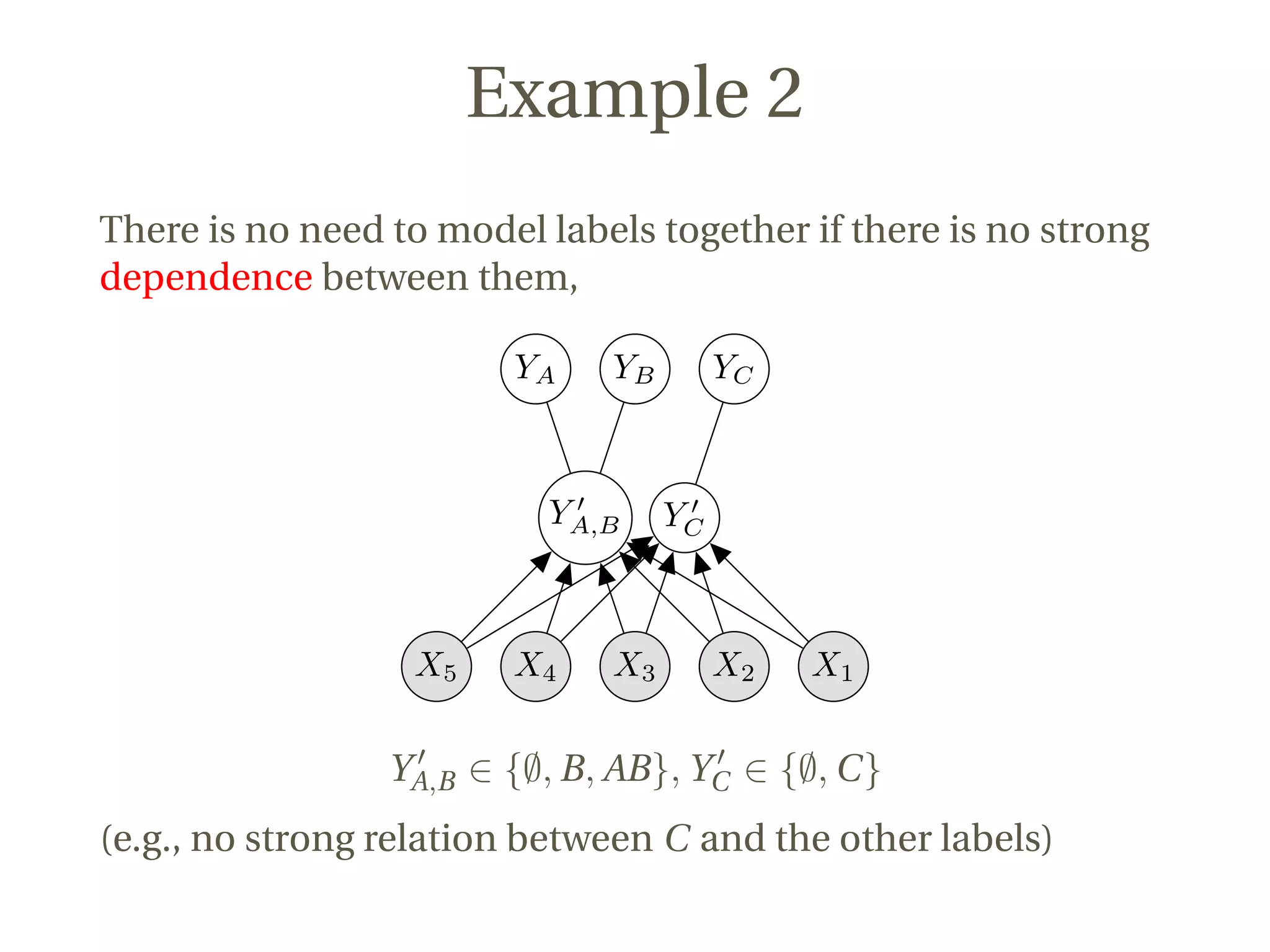

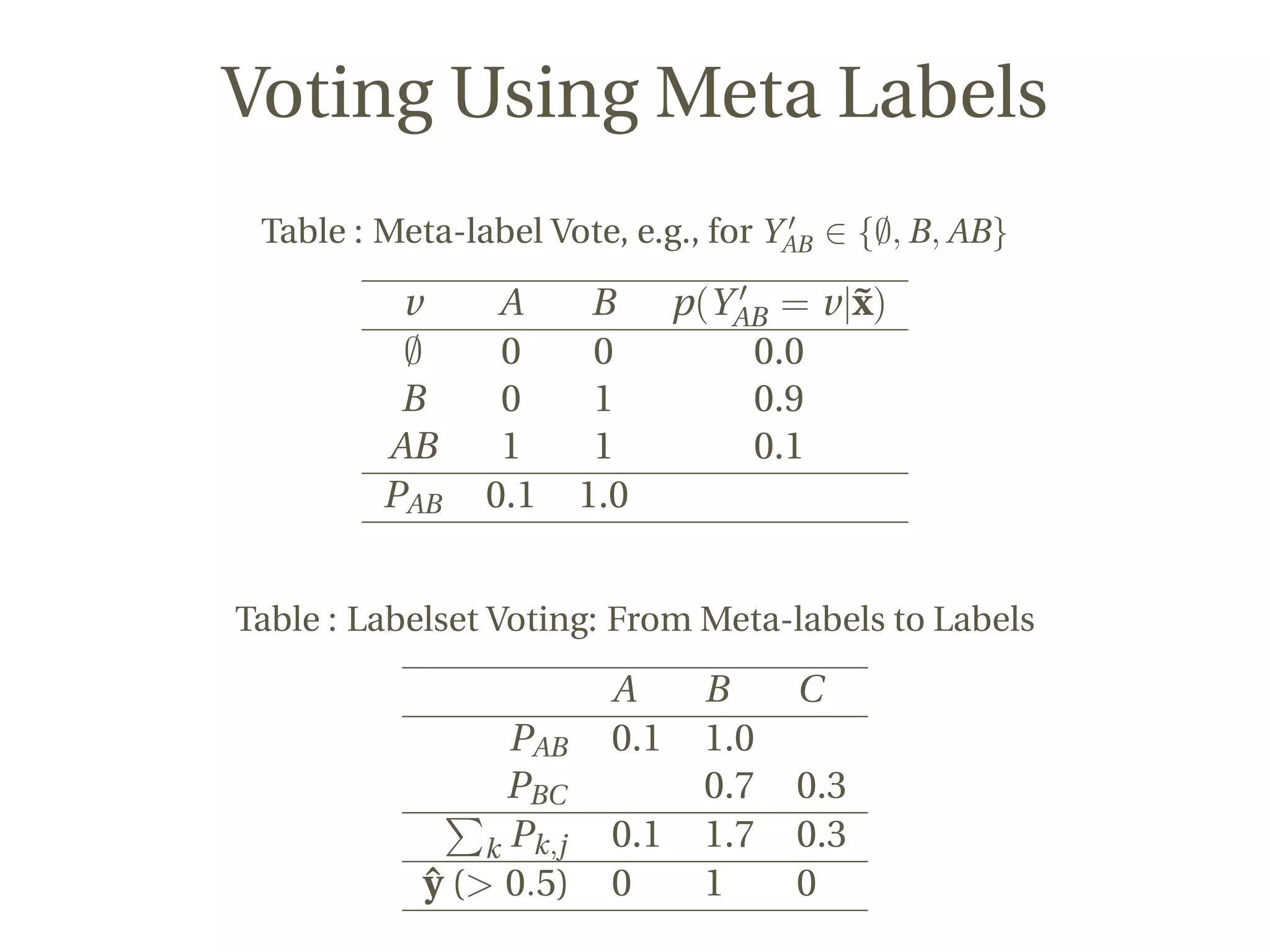
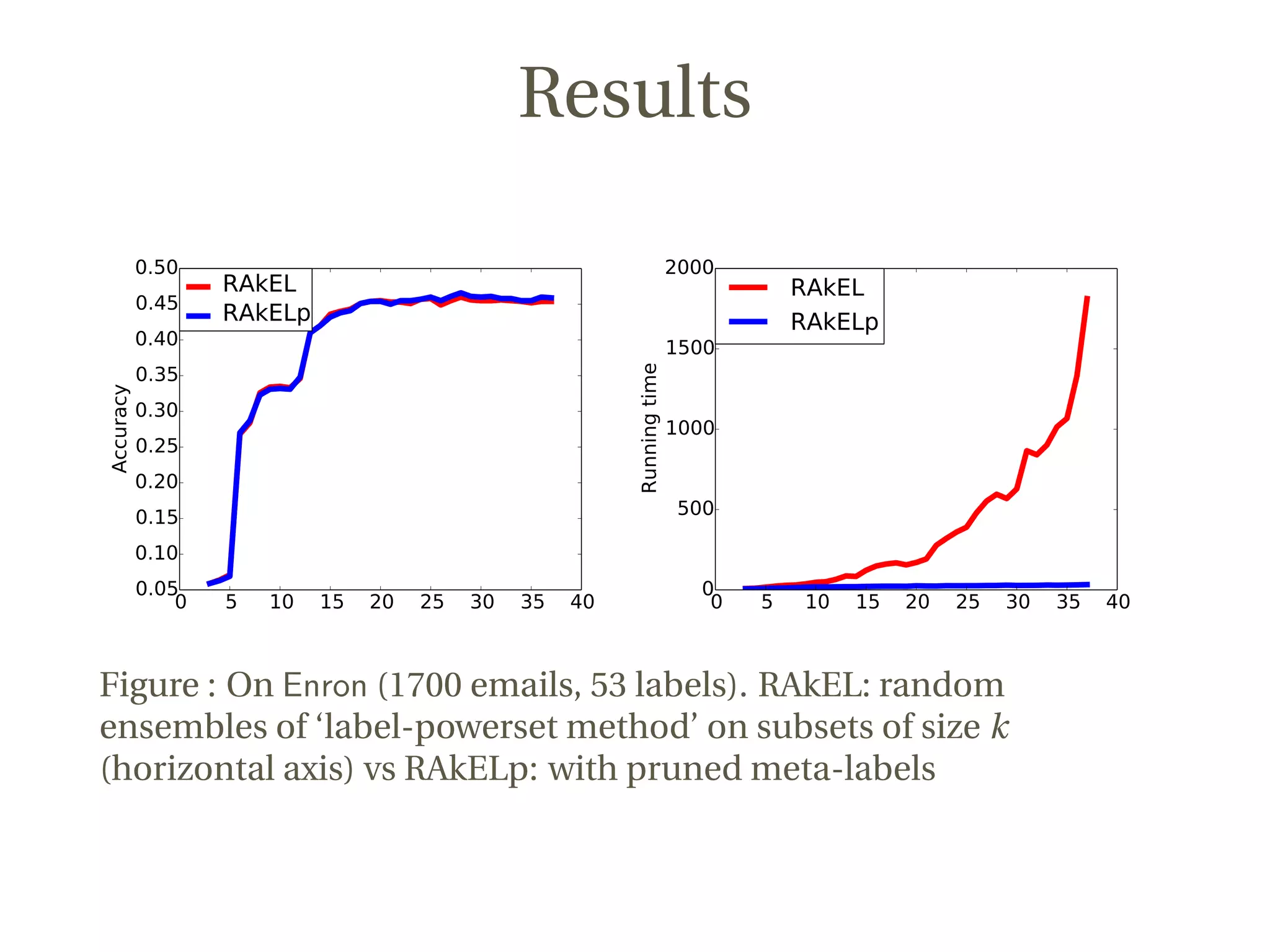



This document discusses a novel approach to multi-label classification using meta-labels to improve efficiency and effectiveness in capturing label dependencies. It presents a general framework that integrates various methods, introducing new models like rakelp and eprd, which significantly enhance running time. The work has achieved notable success in Kaggle competitions and provides accessible code for further experimentation.


















































































