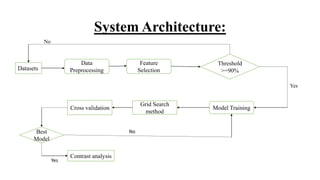
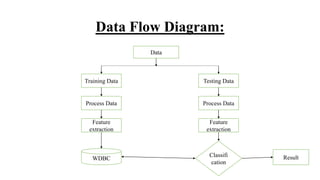
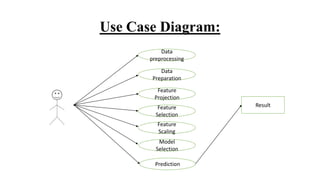
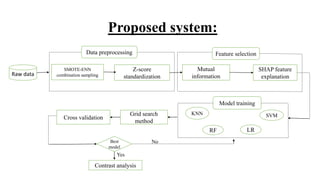
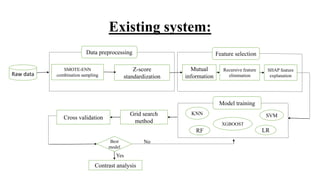
The document outlines a project on predicting breast cancer using various machine learning algorithms, highlighting a systematic approach to address sample imbalance and improve data separability through standardization. It reviews key findings from literature on different algorithms such as SVM, logistic regression, and random forests, and proposes a system that combines data preprocessing with techniques like feature selection and model training for enhanced prediction accuracy. The project aims to optimize model performance while addressing challenges such as generalizability and handling of medical jargon.
![Prediction for Breast cancer using various
Machine Learning Algorithms
Project Batch Details:
Batch Information:
LUCKY SHETTY [1KN20CS015] PROJECT GUIDE :
NAVEENA C K [1KN20CS026] Prof. Kusum Rajput Dept. of CSE
VISHNU BABU B [1KN20CS050]](https://image.slidesharecdn.com/finalprojectppt-240508162749-8211ce83/85/Prediction-for-breast-cancer-using-various-machine-learning-algorithms-1-320.jpg)
![Prediction for Breast cancer using various
Machine Learning Algorithms
Project Batch Details:
Batch Information:
LUCKY SHETTY [1KN20CS015] PROJECT GUIDE :
NAVEENA C K [1KN20CS026] Prof. Kusum Rajput Dept. of CSE
VISHNU BABU B [1KN20CS050]](https://image.slidesharecdn.com/finalprojectppt-240508162749-8211ce83/75/Prediction-for-breast-cancer-using-various-machine-learning-algorithms-1-2048.jpg)