Recommended
PDF
第三回さくさくテキストマイニング勉強会 入門セッション
PDF
CluBERT: A Cluster-Based Approach for Learning Sense Distributions in Multipl...
PPTX
PPTX
Microsoft Cognitive Services NLP APIs
PPTX
これからの Vision & Language ~ Acadexit した4つの理由
PDF
PDF
PDF
PDF
ZeroCap: Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic
PDF
PDF
PDF
PDF
transformer解説~Chat-GPTの源流~
PDF
20190324 第6章 テキストデータのための素性
PPTX
PPTX
Machine Learning Seminar (5)
PPTX
画像キャプションの自動生成(第3回ステアラボ人工知能セミナー)
PDF
PPTX
PPTX
PPTX
PPTX
PPTX
【論文紹介】Distributed Representations of Sentences and Documents
PDF
Facebookの人工知能アルゴリズム「memory networks」について調べてみた
PPTX
Deep neural models of semantic shift
PDF
PDF
PDF
Segmenting Sponteneous Japanese using MDL principle
PDF
【第7章】第3層:風(業務改革)|地方中小企業向け-CX風林火山 実践ガイド-BSC理論×スタートアップサイエンス
PDF
3位_ Micromaterials_愛知学院大学.pdf-----------
More Related Content
PDF
第三回さくさくテキストマイニング勉強会 入門セッション
PDF
CluBERT: A Cluster-Based Approach for Learning Sense Distributions in Multipl...
PPTX
PPTX
Microsoft Cognitive Services NLP APIs
PPTX
これからの Vision & Language ~ Acadexit した4つの理由
PDF
PDF
PDF
Similar to 自然言語処理.pptx
PDF
ZeroCap: Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic
PDF
PDF
PDF
PDF
transformer解説~Chat-GPTの源流~
PDF
20190324 第6章 テキストデータのための素性
PPTX
PPTX
Machine Learning Seminar (5)
PPTX
画像キャプションの自動生成(第3回ステアラボ人工知能セミナー)
PDF
PPTX
PPTX
PPTX
PPTX
PPTX
【論文紹介】Distributed Representations of Sentences and Documents
PDF
Facebookの人工知能アルゴリズム「memory networks」について調べてみた
PPTX
Deep neural models of semantic shift
PDF
PDF
PDF
Segmenting Sponteneous Japanese using MDL principle
Recently uploaded
PDF
【第7章】第3層:風(業務改革)|地方中小企業向け-CX風林火山 実践ガイド-BSC理論×スタートアップサイエンス
PDF
3位_ Micromaterials_愛知学院大学.pdf-----------
PDF
EXPERTGARDEN_経営層の皆さま向け資料.pdfEXPERTGARDEN_経営層の皆さま向け資料.pdf
PDF
1位_自然組.inc_東京理科大学.pdf-------------------
PDF
2位【株式会社ローソン】チームわさび(社会6班)_大和大学 (1).pdf-------------
PDF
3位【株式会社ローソン】三万日坊主_京都芸術大学 (1).pdf--------
PDF
chouhouobuse_202601slide_obusetown_nagano.pdf
PDF
2位_ファイヤーサンダーバード_東京理科大学.pdf--------------
PDF
4位_低燃費ぺあ_東北学院大学.pdf---------------------
PDF
5位_ラテン_成城大学.pdf-------------------------
PDF
4位【株式会社ローソン様_チームA.S_産業能率大学】 (1).pdf-----
PDF
5位【株式会社ローソン】げきアツこ_高崎経済大学 (1).pdf--------
PDF
1位[ローソン]オオクワ型_成城大学----------------------
PDF
ISACA CISM and CISA Study memo - Japanese version in 2026
PDF
1位_自然組.inc_東京理科大学.pdf-------------------
PDF
【採用ピッチ資料】ランド・ジャパンの未来の仲間たちへ_2026年改訂版資料.pdf
PDF
令和8年度(2026年)令和8年度税制改正大綱速報ポイント解説 要点をまとめて 税理士法人ゆびすい
PDF
【会社紹介資料】株式会社カンゲンエージェント [ 2026/01 公開 ].pdf
自然言語処理.pptx 1. 2. 3. 4. 5. MeCab
注意点:専門用語の辞書登録
* * * * * * * * * * * * *
政治家 1292 1292 10名詞 固有名詞 一般 * * * せいじか セイジカ セイジカ
自民政権 1292 1292 10名詞 固有名詞 一般 * * * じみんせいけん ジミンセイケン ジミンセイケン
安倍晋三 1291 1291 1名詞 固有名詞 人名 名 * * あべしんぞう アベシンゾウ アベシンゾウ
民主主義 1292 1292 10名詞 固有名詞 一般 * * * みんしゅしゅぎ ミンシュシュギ ミンシュシュギ
誹謗中傷 1292 1292 10名詞 固有名詞 一般 * * * ひぼうちゅうしょう ヒボウチュウショウ ヒボウチュウショウ
有効性 1292 1292 10名詞 固有名詞 一般 * * * ゆうこうせい ユウコウセイ ユウコウセイ
緊縮財政 1292 1292 10名詞 固有名詞 一般 * * * きんしゅくざいせい キンシュクザイセイ キンシュクザイセイ
財務次官 1292 1292 10名詞 固有名詞 一般 * * * ざいむじかん ザイムジカン ザイムジカン
新型コロナ 1292 1292 10名詞 固有名詞 一般 * * * しんがたころなういるす シンガタコロナウイルス シンガタコロナウイルス
新型コロナウイルス 1292 1292 10名詞 固有名詞 一般 * * * しんがたころなういるす シンガタコロナウイルス シンガタコロナウイルス
コロナ 1292 1292 10名詞 固有名詞 一般 * * * しんがたころなういるす シンガタコロナウイルス シンガタコロナウイルス
大喝采 1292 1292 10名詞 固有名詞 一般 * * * だいかっさい ダイカッサイ ダイカッサイ
橋下 1292 1292 10名詞 固有名詞 一般 * * * はしもと ハシモト ハシモト
環境大臣 1292 1292 10名詞 固有名詞 一般 * * * かんきょうだいじん カンキョウダイジン カンキョウダイジン
高市早苗 1280 1280 0名詞 固有名詞 人名 名 * * たかいちさなえ タカイチサナエ タカイチサナエ
さん 1280 1280 0名詞 固有名詞 一般 * * * さん サン サン
防衛費 1292 1292 10名詞 固有名詞 一般 * * * ぼうえいひ ボウエイヒ ボウエイヒ
河野太郎 1292 1292 10名詞 固有名詞 人名 名 * * こうのたろう コウノタロウ コウノタロウ
政務会長 1292 1292 10名詞 固有名詞 一般 * * * せいむかいちょう セイムカイチョウ セイムカイチョウ
財務事務次官 1292 1292 10名詞 固有名詞 一般 * * * ざいむじむじかん ザイムジムジカン ザイムジムジカン
氏 1292 1292 10名詞 固有名詞 一般 * * * し シ シ
消費税 1292 1292 10名詞 固有名詞 一般 * * * しょうひぜい ショウジゼイ ショウヒゼイ
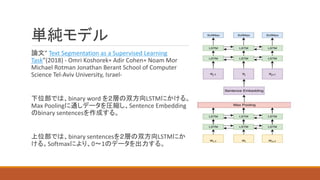
6. 7. 8. 単純モデル
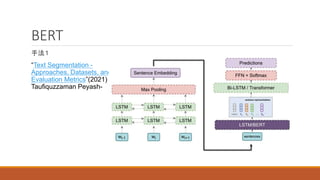
論文” Text Segmentation as a Supervised Learning
Task”(2018) - Omri Koshorek∗ Adir Cohen∗ Noam Mor
Michael Rotman Jonathan Berant School of Computer
Science Tel-Aviv University, Israel-
下位部では、binary word を2層の双方向LSTMにかける。
Max Poolingに通しデータを圧縮し、Sentence Embedding
のbinary sentencesを作成する。
上位部では、binary sentencesを2層の双方向LSTMにか
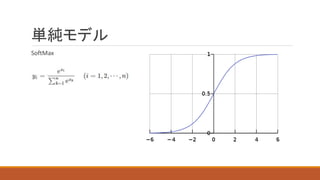
ける。Softmaxにより、0~1のデータを出力する。
9. 10. 11. 13. 単純モデル
・LSTMとは
Long Short Term Memory
・RNN(その前に)
𝑖𝑛𝑝𝑢𝑡 ∶ 𝑥0
, 𝑥1
, … , 𝑥𝑇
, ℎ−1
𝑐𝑒𝑙𝑙 ∶ 𝑦𝑡, ℎ𝑡 = 𝑓(𝑥𝑡, 𝑦𝑡−1, ℎ𝑡−1)
𝑜𝑢𝑡𝑝𝑢𝑡 ∶ 𝑦0, 𝑦1, … , 𝑦𝑇, ℎ𝑇
hは、以前までの情報と捉えて良い。
・RNNの欠点
記憶力が悪い!
𝑦 𝑡 = ℎ 𝑡 = 𝑓𝑡𝑎𝑛ℎ
𝑥𝑡
, ℎ𝑡−1
= tanh 𝑥𝑡𝑊𝑥ℎ + ℎ𝑡−1𝑊ℎℎ + 𝑏
※上の数式はsimple RNNである。
RNNだと数式が複雑になるので。
xがhの情報を消してしまう。
つまり、5~6個前の情報を覚えていない。
14. 単純モデル
・LSTM
𝑓𝑡
= 𝑓𝑓
𝜎
(𝑥𝑡
, ℎ𝑡−1
)
𝑖𝑡 = 𝑓𝑖
𝜎
(𝑥𝑡, ℎ𝑡−1)
𝑜𝑡
= 𝑓𝑜
𝜎
(𝑥𝑡
, ℎ𝑡−1
)
𝑐𝑡
= 𝑓𝑐
𝑡𝑎𝑛ℎ
(𝑥𝑡
, ℎ𝑡−1
)
𝑐𝑡
= 𝑓𝑡
°𝑐𝑡−1
+ 𝑖𝑡
°𝑐𝑡
𝑦𝑡
= ℎ𝑡
= 𝑜𝑡
°𝑐𝑡
1
2
° 3
4
= 1∗3
2∗4
= 3
8
゜はアダマール積
c:長期記憶 h:短期記憶
𝑐𝑡
= 𝑓𝑡
°𝑐𝑡−1
+ 𝑖𝑡
°𝑐𝑡
𝑐𝑡−1
は1つ前の長期記憶
𝑓𝑡はforget gate vector。 𝑓𝑡は、0~1 を取るsigmoid関数なので、0に近いときは記憶を喪
失させ、1に近いときは記憶を引き継ぐ。
𝑖𝑡
°𝑐𝑡
は、xとhを読んで次に追加する新たな記憶のこと。xは今回の記憶。hは短期記憶。
𝑐𝑡
が追加させるべき情報を持つ。 𝑖𝑡
は、0~1を取るので、文脈を加味して、その情報を追
加させるべきかを判断する。
ℎ𝑡 = 𝑜𝑡°𝑐𝑡
これは、長期記憶の中から短期記憶に必要なものを選んでいる。
ちなみに、全てベクトルで出てくるので、それぞれの単語で記憶している。
今回では、 𝑐
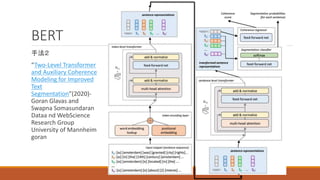
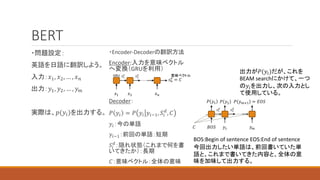
15. 16. 17. 18. 19. 20. 21. 22. 23. 24. BERT
・問題設定:
英語を日語に翻訳しよう。
入力:𝑥1, 𝑥2, … , 𝑥𝑛
出力:𝑦1, 𝑦2, … , 𝑦𝑚
実際は、𝑝(𝑦𝑖)を出力する。
・Encoder-Decoderの翻訳方法
Encoder:入力を意味ベクトル
へ変換(GRUを利用)
Decoder:
𝑃 𝑦𝑖 = 𝑃 𝑦𝑖 𝑦𝑖−1, 𝑆𝑖
𝑑
, 𝐶
𝑦𝑖:今の単語
𝑦𝑖−1:前回の単語:短期
𝑆𝑖
𝑑
:隠れ状態(これまで何を書
いてきたか):長期
𝐶:意味ベクトル:全体の意味
𝑠1
𝑒
𝑠2
𝑒
𝑠𝑛
𝑒
= 𝐶
𝑥1 𝑥2 𝑥𝑛
GRU 意味ベクトル
𝑠1
𝑑
𝑠2
𝑑
𝐵𝑂𝑆 𝑦1 𝑦𝑚
𝑃 𝑦1 𝑃 𝑦2 𝑃 𝑦𝑚+1 = 𝐸𝑂𝑆
BOS:Begin of sentence EOS:End of sentence
今回出力したい単語は、前回書いていた単
語と、これまで書いてきた内容と、全体の意
味を加味して出力する。
𝐶
出力が𝑃(𝑦𝑖)だが、これを
BEAM searchにかけて、一つ
の𝑦𝑖を出力し、次の入力とし
て使用している。
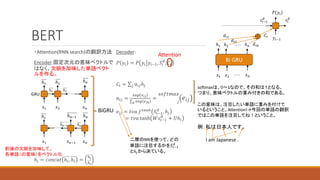
25. BERT
・Attention(RNN search)の翻訳方法
Encoder:固定次元の意味ベクトルで
はなく、文脈を加味した単語ベクト
ルを作る。
ℎ𝑖 = 𝑐𝑜𝑛𝑐𝑎𝑡 ℎ𝑖, ℎ𝑖 =
ℎ𝑖
ℎ𝑖
ℎ1 ℎ2
𝑥2 𝑥𝑛
ℎ1 ℎ2
ℎ𝑛
𝑥1
ℎ𝑛−1
ℎ1
ℎ𝑛−1 ℎ𝑛
𝑥𝑛−1 𝑥𝑛
𝑥1
ℎ𝑛
BiGRU
GRU
前後の文脈を加味して、
各単語(の意味)をベクトル化
Decoder:
𝑃 𝑦𝑖 = 𝑃 𝑦𝑖 𝑦𝑖−1, 𝑆𝑖
𝑑
, 𝐶𝑖
𝐶𝑖 = 𝑗 α𝑖𝑗ℎ𝑗
α𝑖𝑗 =
exp 𝑒𝑖𝑗
𝑘 exp 𝑒𝑖𝑘
=
𝑗
𝑠𝑜𝑓𝑡𝑚𝑎𝑥
𝑒𝑖𝑗
𝑒𝑖𝑗 = 𝑡𝑣𝑎 𝑓𝑡𝑎𝑛ℎ
𝑆𝑖−1
𝑑
, ℎ𝑗
= 𝑡𝑣𝑎 tanh 𝑊𝑠𝑖−1
𝑑
+ 𝑈ℎ𝑖
Attention
softmaxは、0~1なので、その和は1となる。
つまり、意味ベクトルの重み付きの和である。
この意味は、注目したい単語に重みを付けて
いるということ。Attention!→今回の単語の翻訳
ではこの単語を注目してね!ということ。
例:私は日本人です。
I am Japanese .
二層のNNを使って、どの
単語に注目するかを𝑆𝑖−1
𝑑
とℎ𝑗から決ている。
Bi GRU
𝑥2 𝑥𝑛
𝑥1
ℎ1 ℎ2 ℎ𝑛
𝑦𝑖−1
𝑠𝑖−1
𝑑
𝑃 𝑦𝑖
𝑠𝑖
𝑑
𝐶𝑖
𝑑𝑖1
𝑑𝑖2
𝑑𝑖𝑛
26. 27. 28. 29. tf-idf(検索アルゴリズム)
# of t ind = 単語tの登場回数
#d = 文章dの単語数
#D = 全体の文章数
#{d <- D|t <- d} = 単語tを含む文章数
𝑡𝑓 𝑡, 𝑑 =
# 𝑜𝑓 𝑡 𝑖𝑛𝑑
#𝑑
𝑖𝑑𝑓 𝑡 = log
#𝐷
#{𝑑←𝐷|𝑡←𝑑}
𝑡𝑓 − 𝑖𝑑𝑓 𝑡, 𝑑 = 𝑡𝑓 𝑡, 𝑑 ∗ 𝑖𝑑𝑓(𝑡)
30. 31. tf-idf(検索アルゴリズム)
・𝑖𝑑𝑓 𝑡 = log
#𝐷
#{𝑑←𝐷|𝑡←𝑑}
まず、
#{𝑑←𝐷|𝑡←𝑑}
#𝐷
とは、単語tを含む文章の割当を示す。つまり、レア度のこと。
#{𝑑←𝐷|𝑡←𝑑}
#𝐷
= 𝑝(𝑡)と置くと、
#𝐷
#{𝑑←𝐷|𝑡←𝑑}
=
1
𝑝 𝑡
となる。
つまり、idf(t)は、レア度が高いと数値が大きくなる。
logは、確率を情報量として扱うことができる。
32. 33. 34. BM25(検索アルゴリズム)
𝑠𝑐𝑜𝑟𝑒 𝑞, 𝑑 = 𝑖 𝑖𝑑𝑓(𝑞𝑖) ∗
𝑘1+1 𝑓 𝑞𝑖,𝑑
𝑓 𝑞𝑖,𝑑 +𝑘1 1−𝑏+𝑏∗
#𝑑
𝑎𝑣𝑔𝑑𝑙
𝑘1, 𝑏 ∶ 制御パラメータ 𝑘1 = 1.2, 𝑏 = 0.75 が一般的
#𝑑: 文章dの単語数
avgdl: (文章中に出現する)単語数の平均 average of document length
𝑓 𝑞𝑖, 𝑑 : 文章dの中の単語𝑞𝑖の量
35. 36. BM25(検索アルゴリズム)
𝜑 =
𝑘1+1 𝑓
𝑓+𝑘1
𝑓 = 1とすると、𝜑 = 1となる。つまり、1回出現ならレア度は1となる。
𝑓 = 2とすると、𝜑 = 2 −
2
2+𝑘1
。レア度は2より少し小さい。
fが増えても青天井にはしない。
𝑘1 + 1
𝜑
𝑓
1
1
𝜑 =
𝑘1 + 1 𝑓
𝑓 + 𝑘1
つまり、たくさんの単語が登
場すると、ポイントも大きい
が。ただ、K_1 + 1までである。
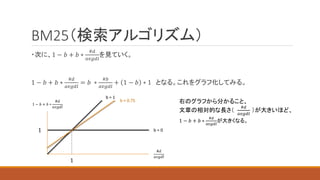
37. BM25(検索アルゴリズム)
・次に、1 − 𝑏 + 𝑏 ∗
#𝑑
𝑎𝑣𝑔𝑑𝑙
を見ていく。
1 − 𝑏 + 𝑏 ∗
#𝑑
𝑎𝑣𝑔𝑑𝑙
= 𝑏 ∗
#𝑏
𝑎𝑣𝑔𝑑𝑙
+ 1 − 𝑏 ∗ 1 となる。これをグラフ化してみる。
1
1 − 𝑏 + 𝑏 ∗
#𝑑
𝑎𝑣𝑔𝑑𝑙
#𝑑
𝑎𝑣𝑔𝑑𝑙
b = 0
1
b = 1
b = 0.75 右のグラフから分かること、
文章の相対的な長さ(
#𝑑
𝑎𝑣𝑔𝑑𝑙
)が大きいほど、
1 − 𝑏 + 𝑏 ∗
#𝑑
𝑎𝑣𝑔𝑑𝑙
が大きくなる。
38. 39. 40.







































































![1位[ローソン]オオクワ型_成城大学----------------------](https://cdn.slidesharecdn.com/ss_thumbnails/1-260120025741-59d1b2e9-thumbnail.jpg?width=640&height=640&fit=bounds)




![【会社紹介資料】株式会社カンゲンエージェント [ 2026/01 公開 ].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/202501ver-260122081900-e7a475ff-thumbnail.jpg?width=640&height=640&fit=bounds)