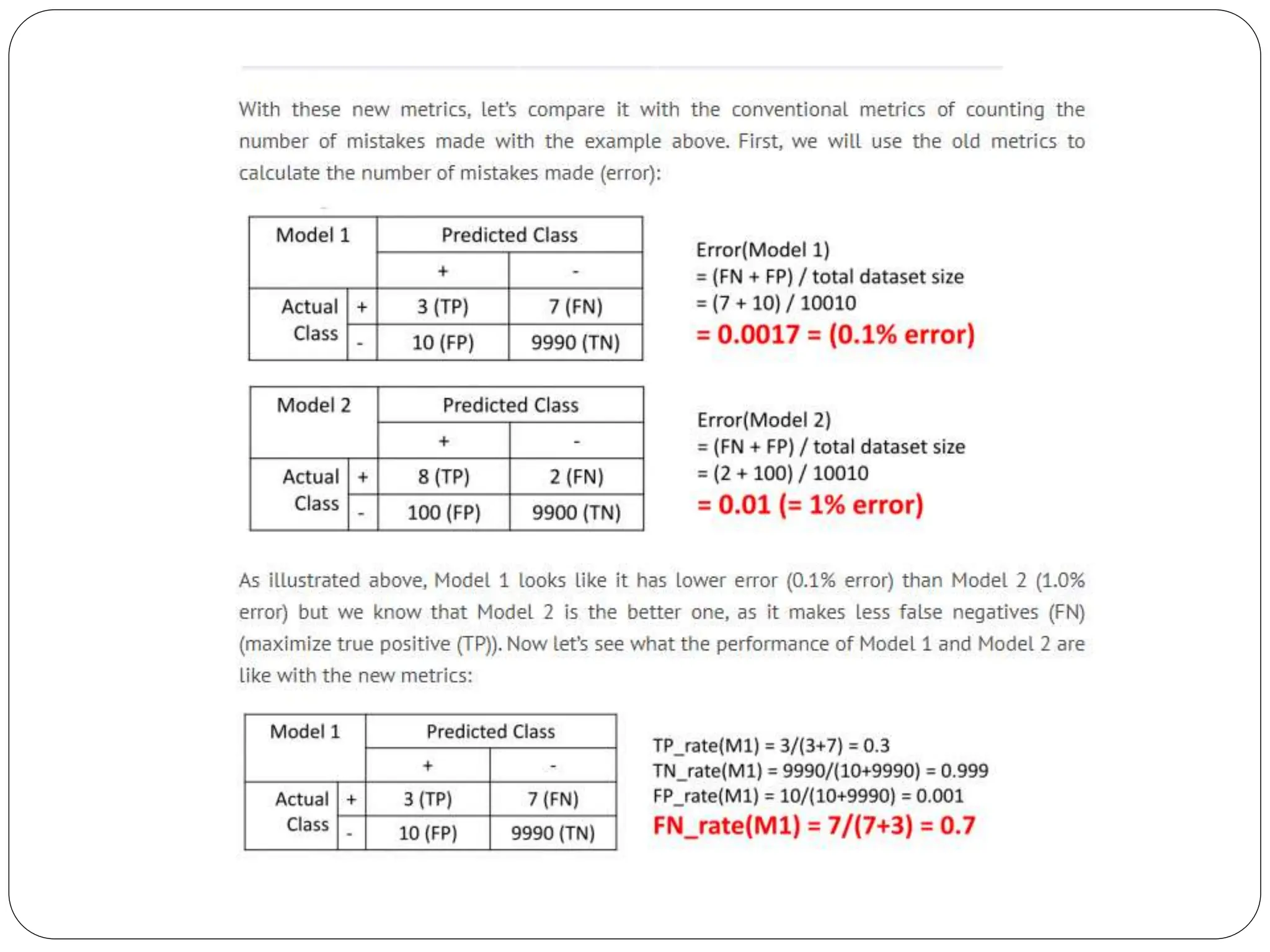
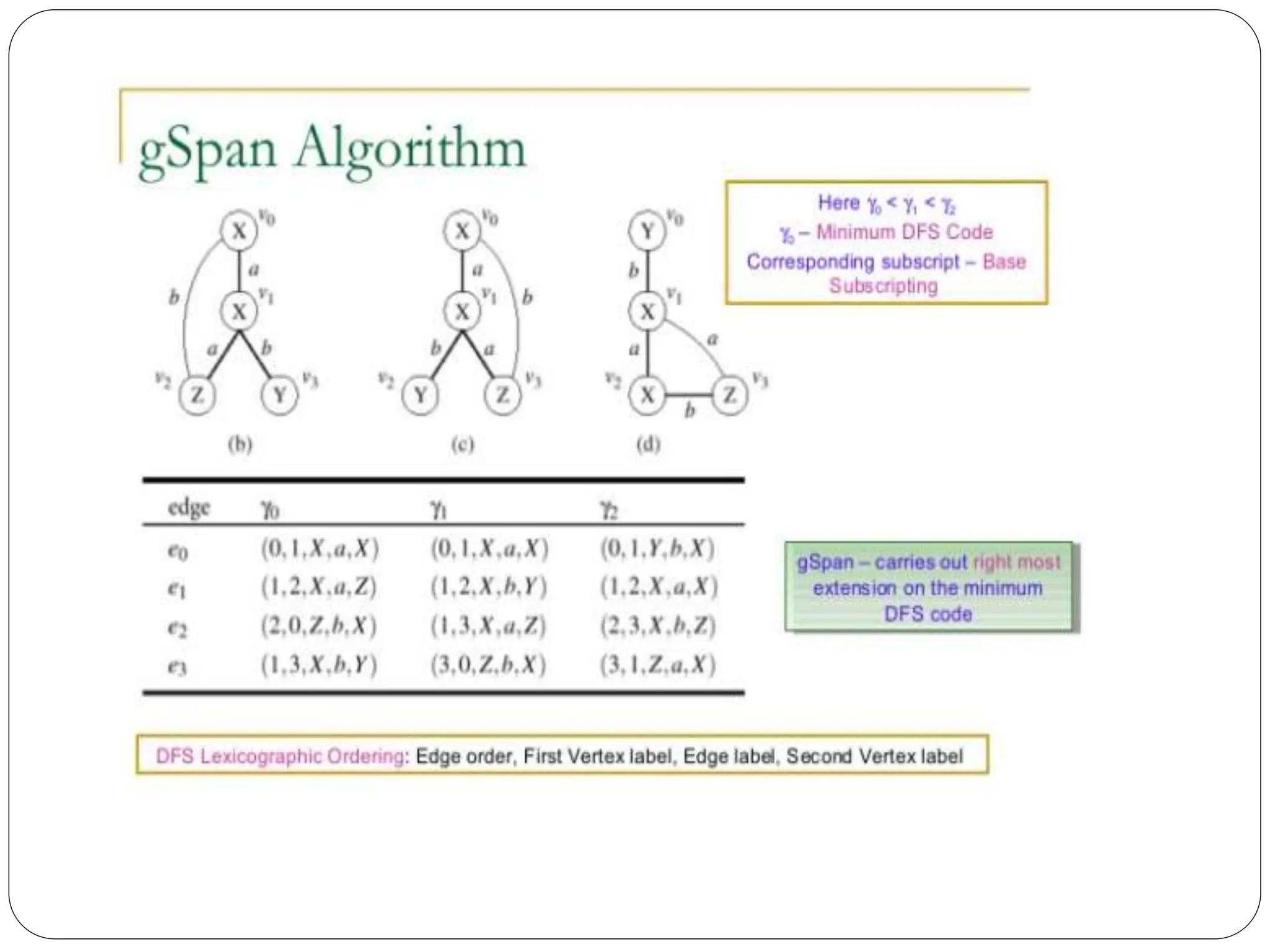
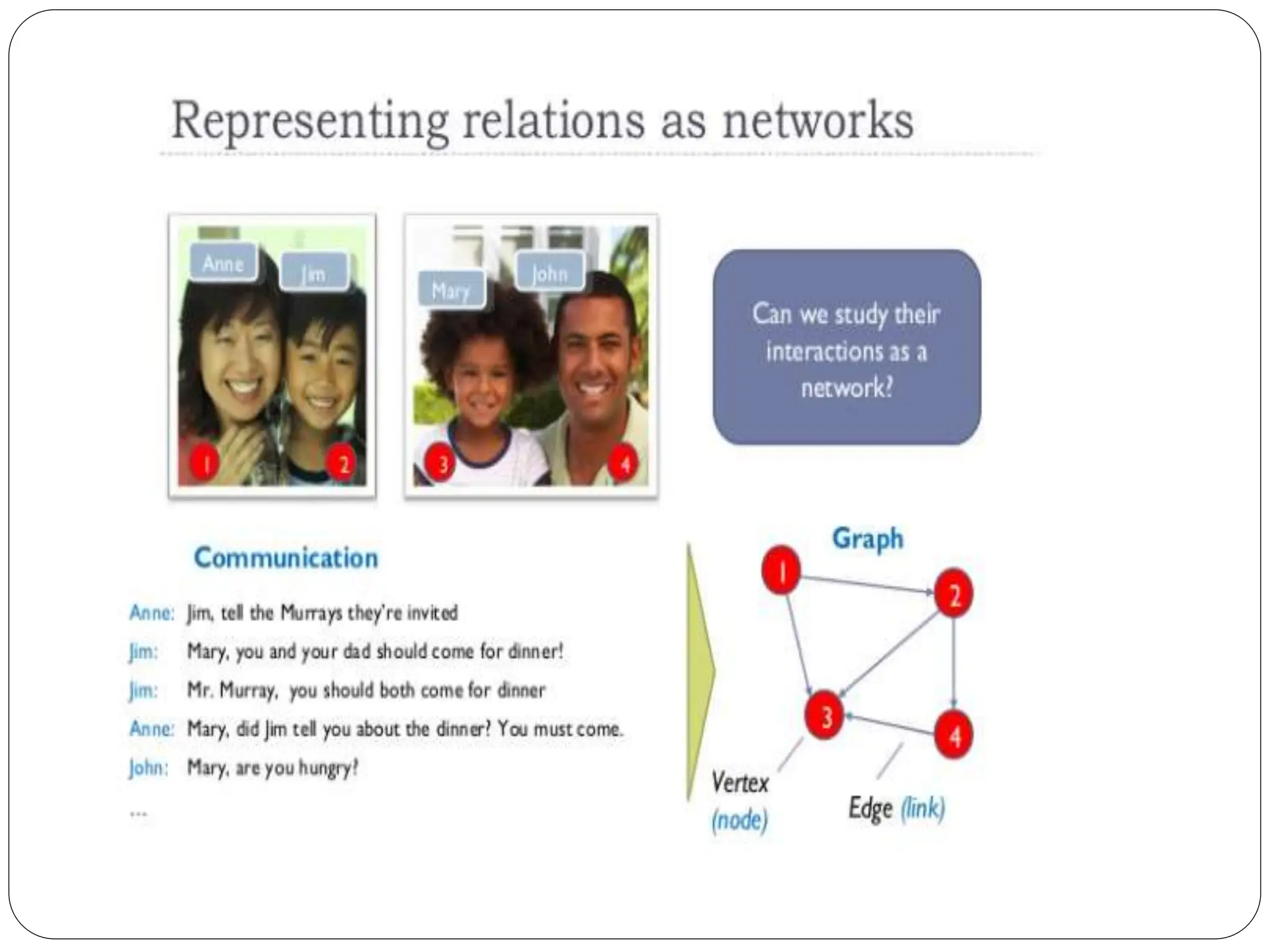
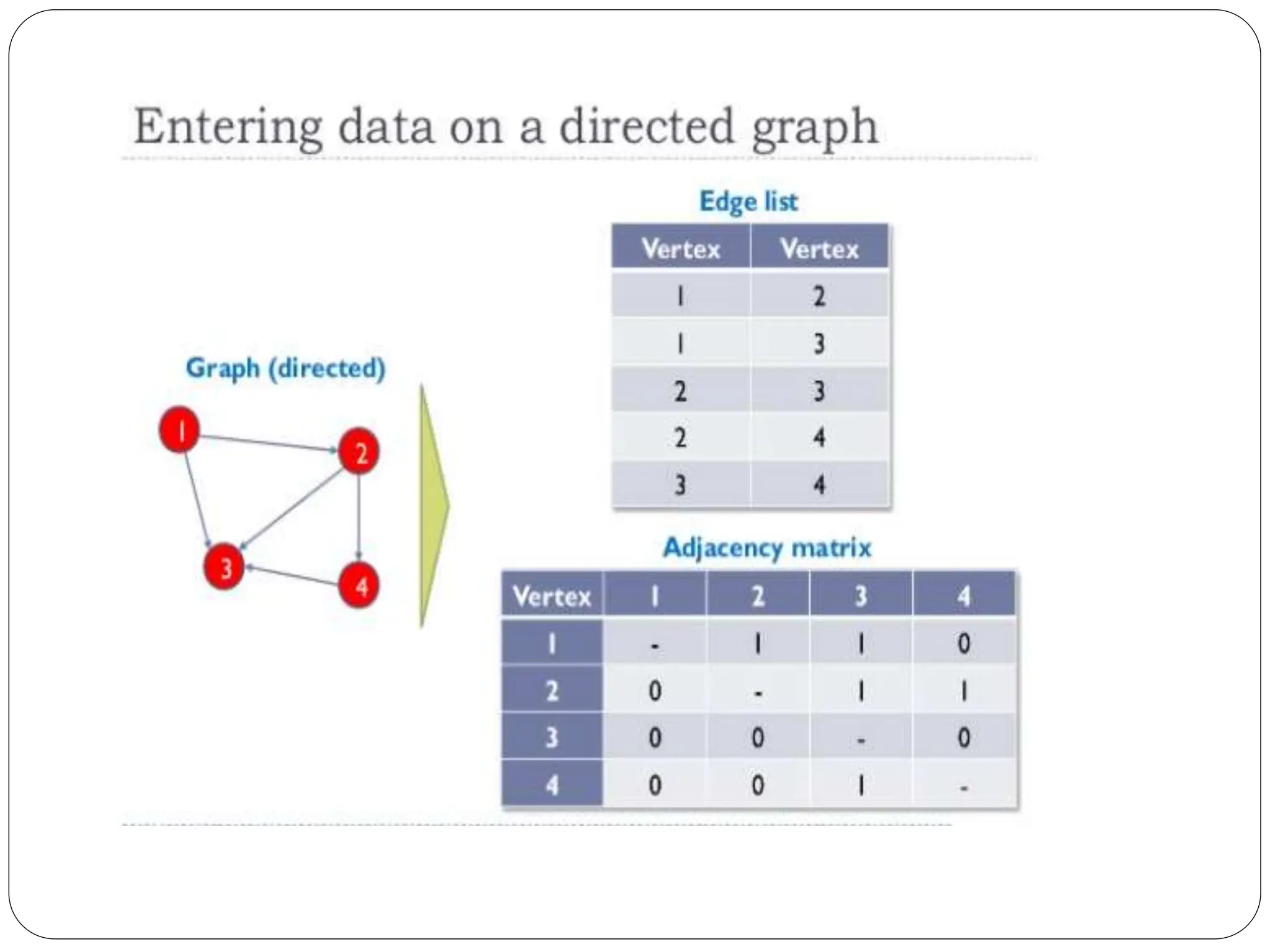
The class imbalance problem in machine learning occurs when one class of data significantly outnumbers another, affecting model accuracy, particularly in tasks like fraud detection. To resolve this, metrics such as true positive and true negative rates need to be utilized for better evaluation of classifiers. Additionally, graph mining plays a crucial role in analyzing complex structures across various applications, including social networks, which represent the relationships and connections between individuals.