This document summarizes experiments on bilingual semantic text similarity using various word and sentence embedding approaches. It fine-tunes the COMET machine translation evaluation model on 100,000 parallel English-Hindi sentences and compares the results to other sentence encoders like LaBSE, LASER and SBERT using Pearson correlation. LaBSE and SBERT are found to give the best results. Future work could include fine-tuning models on larger data to potentially achieve better performance.


![1. Introduction
• Bilingual Semantic Text similarity [1]
• Measures the equivalence of meanings between two languages.
• With the bilingual distributed representation of words we try to capture semantic meaning.
• It can be divided into three phases, Preprocessing, Similarity Measure, and Score estimation
• It can be used in various NLP applications like Question-Answer, Machine Translation, and Information Extraction.
• Word level embedding and Sentence level embedding
• Word Level Embedding: Word2Vec, Glove, Fasttext, Elmo, BERT [2-8]
• Sentence Level Embedding: SBERT, LaBSE, LASER [9-11]
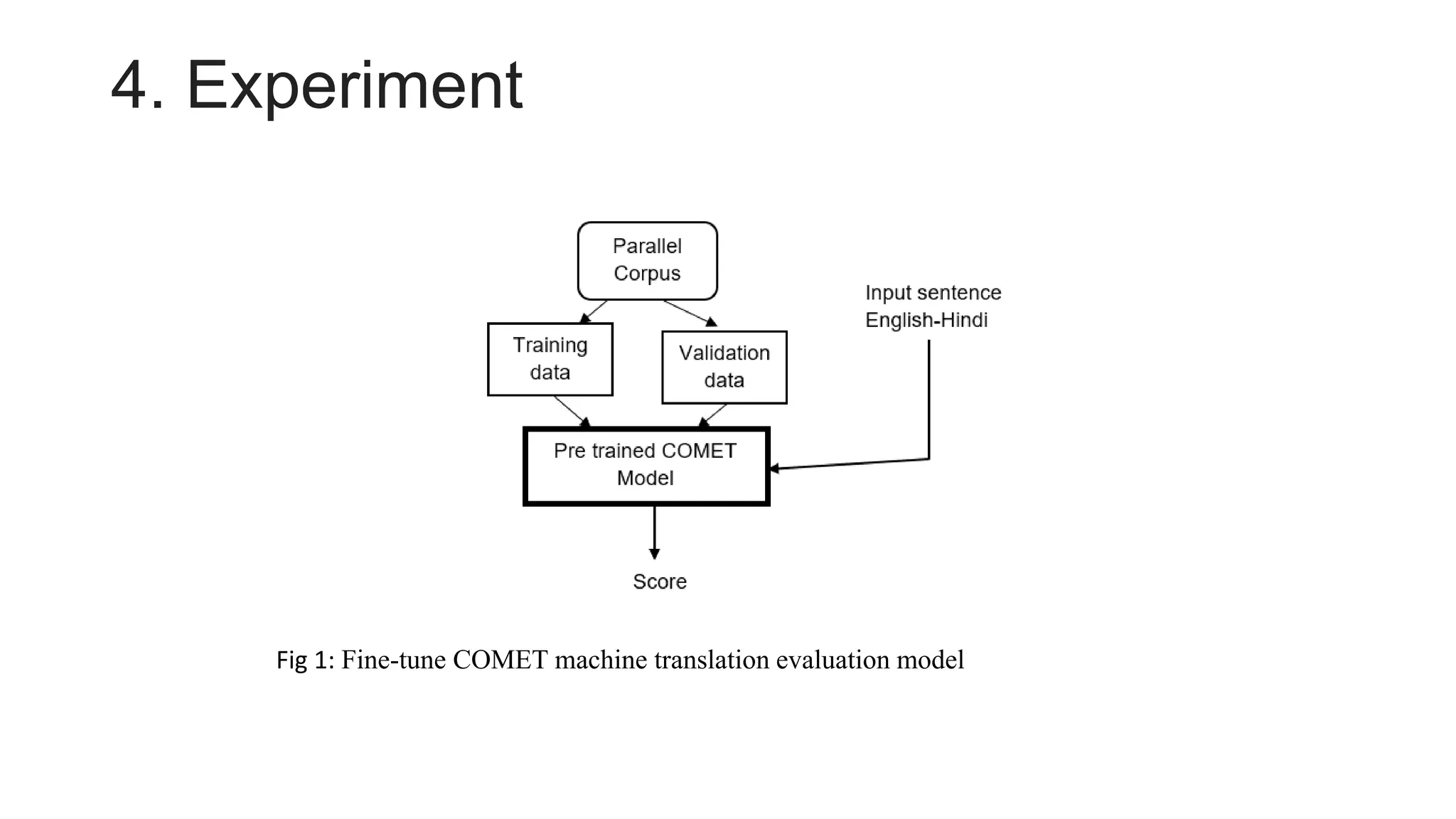
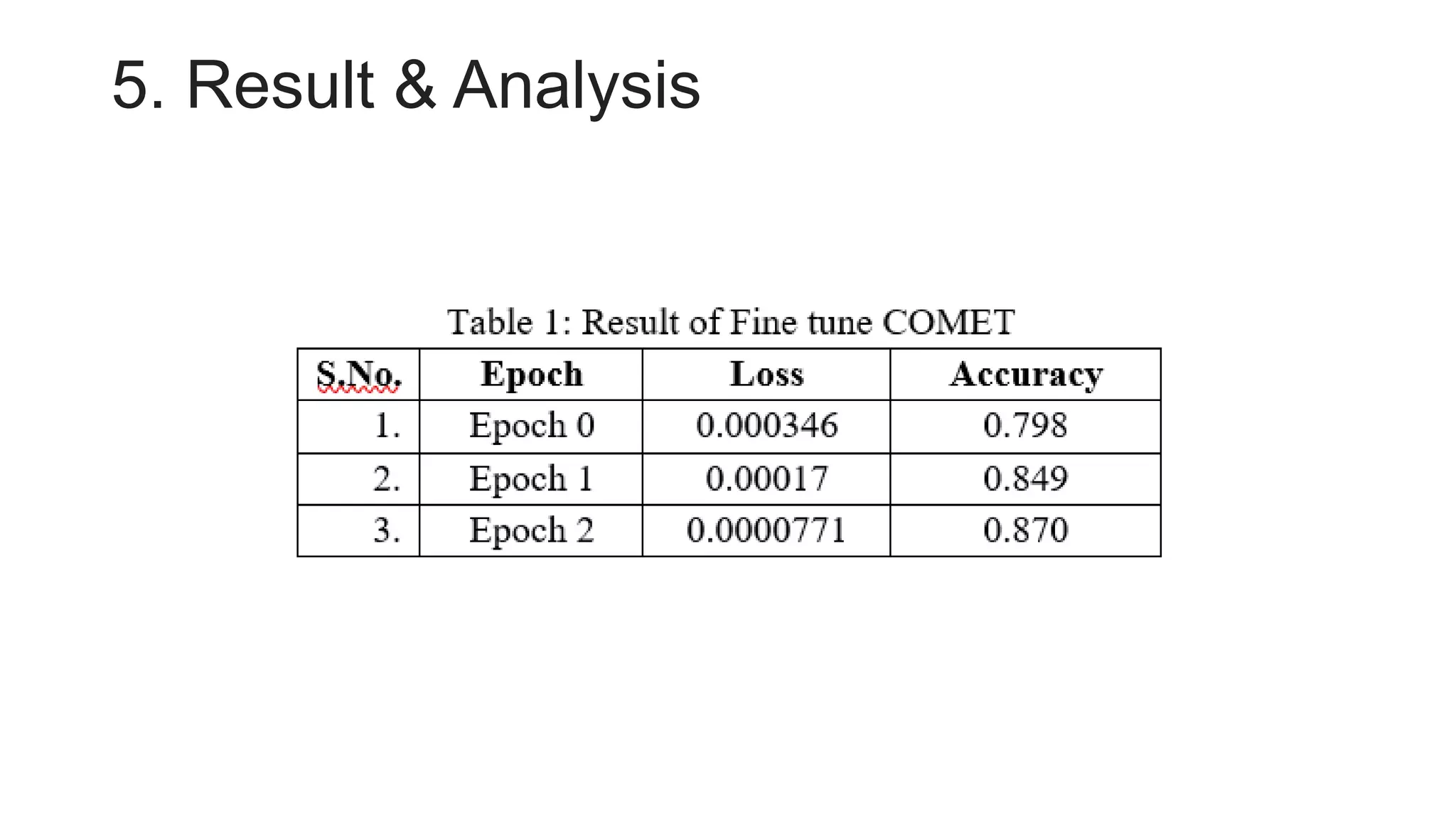
• Fine Tune COMET machine translation evaluation model[12-13]
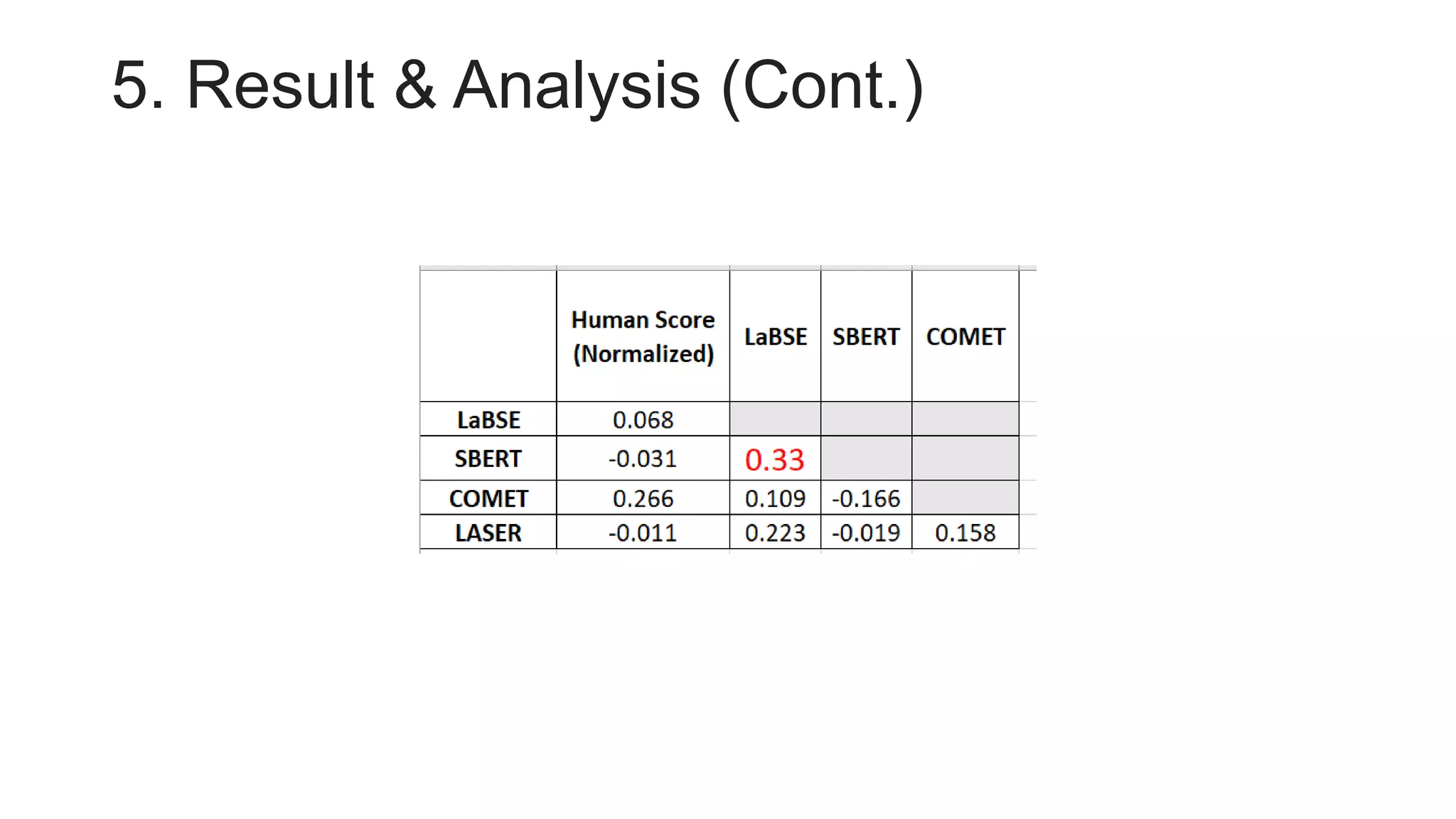
• Pearson correlation using Normalized score and other sentence embedding approaches](https://image.slidesharecdn.com/pptforiasnlp-230822041631-a67b791f/75/ppt-for-IASNLP-pptx-3-2048.jpg)

![3. Data
• We have collected dataset from [14] containing 1,00,000 parallel English and translated Hindi sentences to
fine-tune COMET machine translation model .](https://image.slidesharecdn.com/pptforiasnlp-230822041631-a67b791f/75/ppt-for-IASNLP-pptx-5-2048.jpg)