第10回PostgreSQL アンカンファレンス 「PostgreSQLのイケてるテク7選」
Timestamp の範囲 1/3
キャンペーン情報をDBで管理
2月1日~2月28日までのキャンペーンなどがよくある
単純な実装例
有効なキャンペーンを取り出す SQL
ちょっと読みにくい
3
id : キャンペーンの ID
start_at : timestamp 型
end_at : timestamp 型
SELECT * FROM campaigns
WHERE (start_at IS NULL OR start_at < now() ) AND
(end_at IS NULL OR now() < end_at);
5.
第10回PostgreSQL アンカンファレンス 「PostgreSQLのイケてるテク7選」
Timestamp の範囲 2/3
OR と AND の組合せは、脳への負担が重い
AND だけだと理解しやすい
coalesce : 第1引数が null のとき、第2引数の値を返す
デフォルト値を設定できる関数と思うと理解しやすい
自動的に型変換される。 '-infinity'::timestamptz と同じ
'-infinity' は無限の過去。 'infinity' は無限の未来
4
SELECT * FROM campaigns
WHERE (start_at IS NULL OR start_at < now() ) AND
(end_at IS NULL OR now() < end_at);
SELECT * FROM campaigns
WHERE coalesce(start_at, '-infinity') < now() AND
now() < coalesce(end_at, 'infinity')
6.
第10回PostgreSQL アンカンファレンス 「PostgreSQLのイケてるテク7選」
Timestamp の範囲 3/3
tstzrange で日時の範囲型を1つの列で表現できる
[, ] で閉区間(境界を含む)、 (, ) で開区間(境界を含まない)
@> で、簡潔に contains の判定が可能
gist の index 設定も可能で SQL も高速化可能
5
SELECT * FROM campaigns
WHERE duration @> now();
id : キャンペーンの ID
duration : tstzrange 型
INSERT INTO campaigns ( id, duration )
VALUES (1, '[-infinity, infinity]'), (2, '[-infinity, 2019-02-01)');
7.
第10回PostgreSQL アンカンファレンス 「PostgreSQLのイケてるテク7選」
共通テーブル式(Common Table Expressions) 6
WITH
provider_order_count AS (
SELECT
provider_id,
count(1) AS count
FROM
orders
GROUP BY provider_id
HAVING count(1) > 1000
)
SELECT
b.key, count
FROM
provider_order_count AS a,
providers AS b
WHERE
a.provider_id = b.id
ここに参加してる人は
全員熟知してる?
私は最初かなり感動しました。
上から下に処理順に書ける、
読める。
これまで、FROM のところに
書いていたのと比べ
格段に維持運用しやすい
8.
第10回PostgreSQL アンカンファレンス 「PostgreSQLのイケてるテク7選」
LATERAL ジョイン、json_array_elements、
WITH ORDILALITY
LATERAL
SQL 界の forループ
左側の各行に対して
右側のサブクエリを
実行し、ジョインする
この場合、LATERAL は
省略可
(後続が関数だから)
json_array_elements
JSON の配列を
行として展開できる
WITH ORDINALITY
順位を一緒に返す
->>
JSON オブジェクトの
値を取り出す
7
WITH
recent_histories AS (
SELECT * FROM
try_histories
ORDER BY id DESC
),
chosen_plans_json AS (
SELECT
id, t.chosen_plan, t.idx
FROM
recent_histories AS rh,
LATERAL
json_array_elements(rh.chosen_plans)
WITH ORDINALITY AS t(chosen_plan, idx)
),
SELECT
id, idx,
chosen_plan->>'provider_key' AS provider_key,
chosen_plan->>'plan_key' AS plan_key,
chosen_plan->>'area_key' AS area_key
FROM
chosen_plans_json;
9.
第10回PostgreSQL アンカンファレンス 「PostgreSQLのイケてるテク7選」
CTE のサブクエリとして VALUES を書く
CTE のサブクエリ
として VALUES も
書ける
定数を SQL 内で
書ける
処理を AP サーバから
DB サーバに移せる
8
WITH
order_type_count AS (
SELECT
type_id,
count(1) AS count
FROM
orders
GROUP BY type_id
),
contract_types(type_id, name) AS (
VALUES (1, 'electric_gas'),
(2, 'gas'), (3, 'electric')
)
SELECT
b.name, a.count
FROM
order_type_count AS a,
contract_types AS b
WHERE
a.type_id =
b.type_id
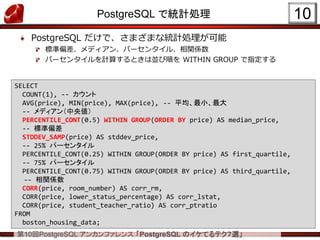
第10回PostgreSQL アンカンファレンス 「PostgreSQLのイケてるテク7選」
PostgreSQL で統計処理 10
SELECT
COUNT(1), -- カウント
AVG(price), MIN(price), MAX(price), -- 平均、最小、最大
-- メディアン(中央値)
PERCENTILE_CONT(0.5) WITHIN GROUP(ORDER BY price) AS median_price,
-- 標準偏差
STDDEV_SAMP(price) AS stddev_price,
-- 25% パーセンタイル
PERCENTILE_CONT(0.25) WITHIN GROUP(ORDER BY price) AS first_quartile,
-- 75% パーセンタイル
PERCENTILE_CONT(0.75) WITHIN GROUP(ORDER BY price) AS third_quartile,
-- 相関係数
CORR(price, room_number) AS corr_rm,
CORR(price, lower_status_percentage) AS corr_lstat,
CORR(price, student_teacher_ratio) AS corr_ptratio
FROM
boston_housing_data;
PostgreSQL だけで、さまざまな統計処理が可能
標準偏差、メディアン、パーセンタイル、相関係数
パーセンタイルを計算するときは並び順を WITHIN GROUP で指定する
12.
第10回PostgreSQL アンカンファレンス 「PostgreSQLのイケてるテク7選」
ltree 型
PostgreSQL 標準拡張にある型の1つ
階層的なラベルデータを表現可能
@>、<@
包含関係
~
経由する場合
gist の index
の作成もできる
11
CREATE EXTENSION ltree;
Top
Top.Science
Top.Science.Astronomy
Top.Science.Astronomy.Astrophysics
Top.Science.Astronomy.Cosmology
Top.Hobbies
Top.Hobbies.Amateurs_Astronomy
Top.Collections
Top.Collections.Pictures
Top.Collections.Pictures.Astronomy
Top.Collections.Pictures.Astronomy.Stars
Top.Collections.Pictures.Astronomy.Galaxies
Top.Collections.Pictures.Astronomy.Astronauts
-- Top.Science の子孫のみを抽出する SQL
SELECT * FROM "ltree_tests" WHERE (path <@ 'Top.Science')
-- Astronomy を経由する場合を抽出する SQL
SELECT * FROM "ltree_tests" WHERE (path ~ '*.Astronomy.*')







![第10回PostgreSQL アンカンファレンス 「PostgreSQL のイケてるテク7選」
Timestamp の範囲 3/3
tstzrange で日時の範囲型を1つの列で表現できる
[, ] で閉区間(境界を含む)、 (, ) で開区間(境界を含まない)
@> で、簡潔に contains の判定が可能
gist の index 設定も可能で SQL も高速化可能
5
SELECT * FROM campaigns
WHERE duration @> now();
id : キャンペーンの ID
duration : tstzrange 型
INSERT INTO campaigns ( id, duration )
VALUES (1, '[-infinity, infinity]'), (2, '[-infinity, 2019-02-01)');](https://image.slidesharecdn.com/postgresql-techniques-190204004514/85/PostgreSQL-7-6-320.jpg)



























![[社内勉強会]ELBとALBと数万スパイク負荷テスト](https://cdn.slidesharecdn.com/ss_thumbnails/elbalb-160822022623-thumbnail.jpg?width=640&height=640&fit=bounds)














































