
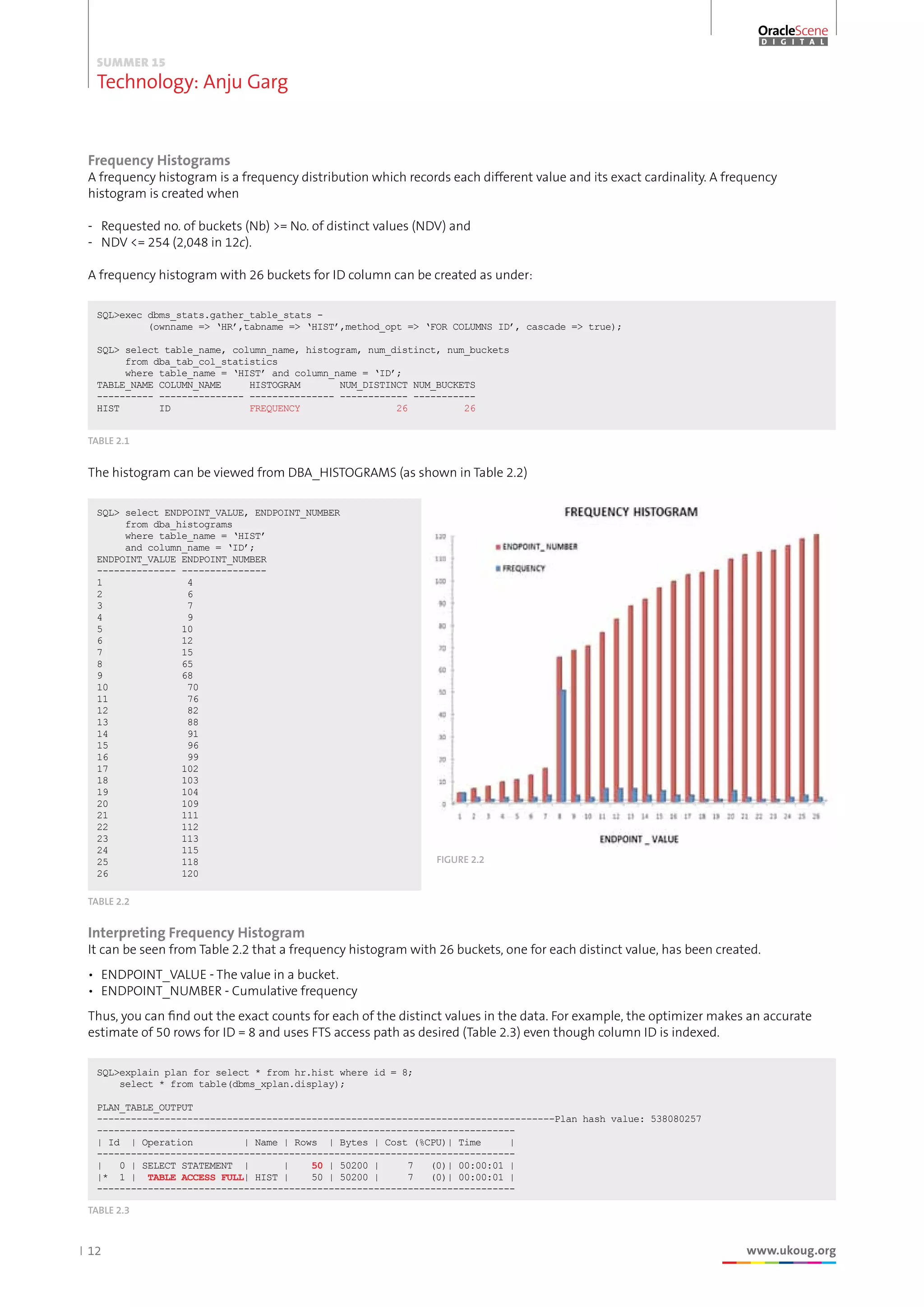



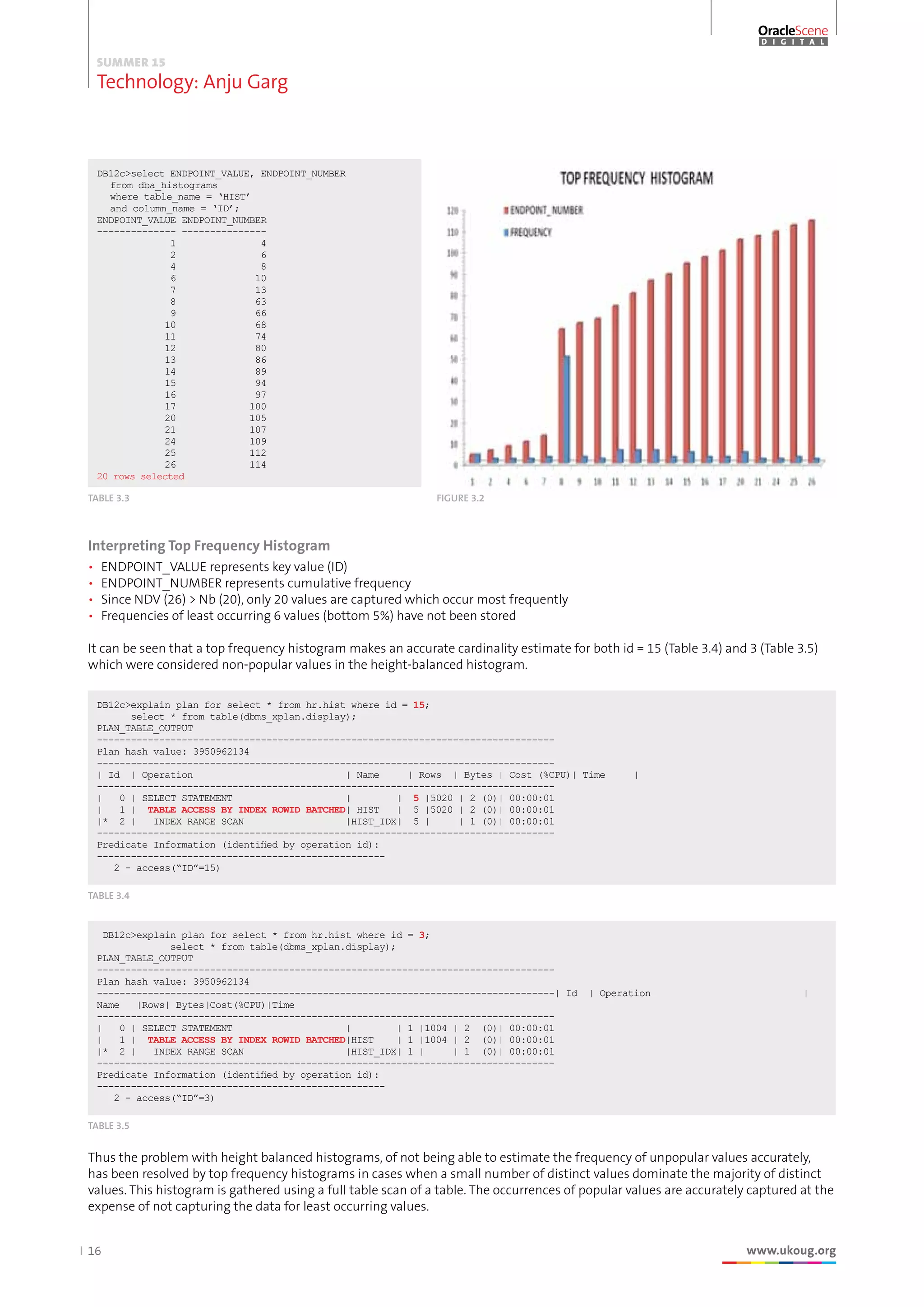



The document discusses the use and evolution of histograms in Oracle databases for optimizing SQL execution plans, particularly in light of skewed data distributions. It outlines the types of histograms available before and after Oracle 12c, including frequency, height-balanced, top-frequency, and hybrid histograms, emphasizing their respective advantages and limitations. The introduction of new histogram types in 12c aims to enhance accuracy in cardinality estimation to improve query performance.













































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)




