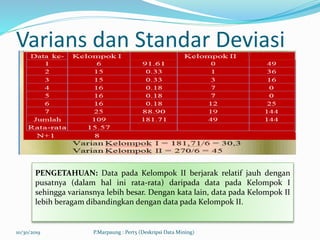
Dokumen ini membahas tentang deskripsi data mining, termasuk cara mendeskripsikan data tinggi badan siswa dengan metode grafis dan lokasi untuk memperoleh informasi yang lebih praktis. Terdapat penjelasan tentang median, modus, kuartil, dan ukuran keberagaman seperti varians dan standar deviasi untuk menggambarkan data secara lebih lengkap. Dengan pendekatan ini, peneliti dapat memberikan analisis yang lebih akurat terkait data yang ada.












![2.2 MEDIAN
Secara matematis, apabila terdapat n buah data, maka
mediannya telatak pada data ke-[(n+1)/2] apabila n
adalah bilangan ganjil. Sebaliknya apabila n adalah
bilangan genap, maka mediannya dihitung dengan cara
menjumlahkan data ke-[n/2] dengan data ke-[(n+1)/2],
kemudian membagi hasil jumlah tersebut dengan
angka 2.
Median = [(data ke-5+data ke-6)/2]=[(166+167)/2]=166.5
10/30/2019 P.Marpaung : Pert5 (Deskripsi Data Mining)](https://image.slidesharecdn.com/pert5deskripsi-191116055212/85/Pert5-deskripsi-13-320.jpg)



![2.4 KUARTIL
kuartil, data dibagi menjadi empat bagian dan nilai dicari di
tiap seperempat bagian (kuartil) tersebut.
Data terurut: 164, 164, 166, 166, 166, 167, 168, 169, 171, 172.
Kuartil pertama = 166
Kuartil kedua = [(166+167)/2] = 166.5 (sama dengan median)
Kuartil ketiga = 169
10/30/2019 P.Marpaung : Pert5 (Deskripsi Data Mining)](https://image.slidesharecdn.com/pert5deskripsi-191116055212/85/Pert5-deskripsi-17-320.jpg)































![4._central_tendensi_nerisa [Autosaved].ppt](https://cdn.slidesharecdn.com/ss_thumbnails/4-240604025336-10eb36eb-thumbnail.jpg?width=640&height=640&fit=bounds)





















