Download to read offline







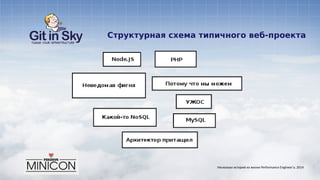































Александр Чистяков, главный инженер компании Git in Sky, делится несколькими историями из своей практики в сфере производительности веб-проектов и обсуждает случаи оптимизации и решения проблем. Он объясняет, кто такие performance engineers и делится методами борьбы с различными проблемами, такими как медленная работа и влияние ботов на производительность сайта. Чистяков подчеркивает важность измерений, планирования и устранения технического долга в веб-разработке.























































































