Downloaded 21 times









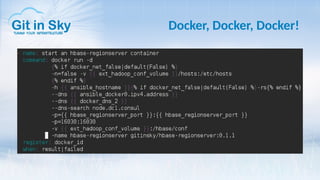

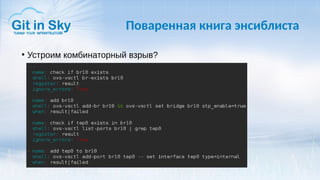
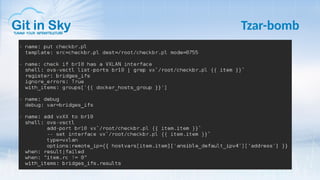

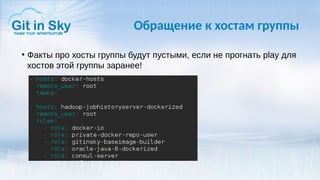



Доклад Александра Чистякова на DevOps Meetup посвящён Ansible и его использованию в работе компании Git in Sky. Он обсуждает простоту Ansible, управление конфигурациями и процессами, а также делится личным опытом и выводами о текущих практиках. Чистяков акцентирует внимание на важности оркестрации и возможном написании собственных модулей в будущем.


































































