Download to read offline







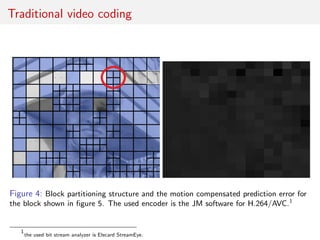







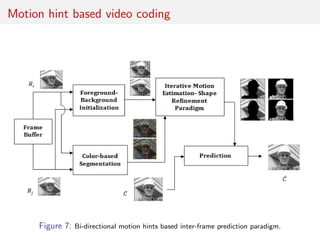





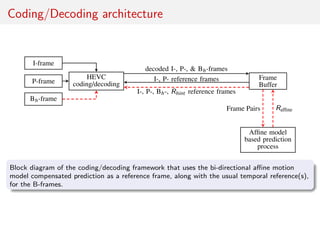









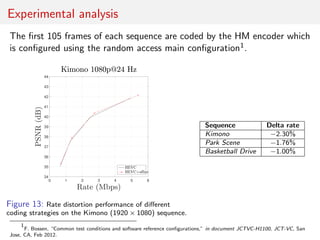


The document discusses advancements in video coding, primarily focusing on a method called bi-directional affine motion model compensated prediction, which improves the efficiency of motion estimation in video compression. It highlights limitations of traditional block-based motion models and introduces motion hints that leverage historical motion information for better predictions. The proposed approach aims to simplify prediction processes without requiring extensive segmentation, showing potential for improved performance in high-resolution video sequences.


































































