Download as PDF, PPTX


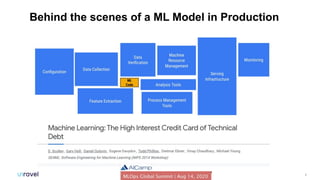
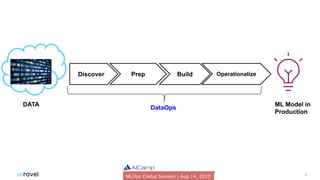




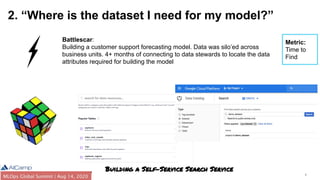









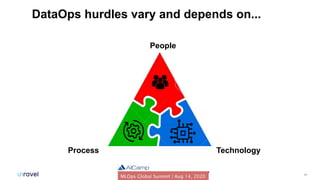


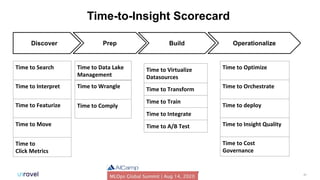

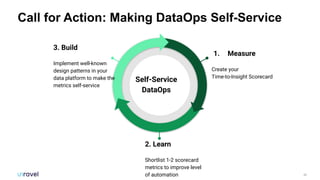



The document outlines common DataOps challenges encountered when deploying machine learning models in production, including issues with data accessibility, completeness, and compliance. It emphasizes the importance of creating self-service solutions to address these challenges, such as metadata catalogs and orchestration services, in order to improve time-to-insight and governance. The document concludes with a call to action for organizations to assess and enhance their DataOps processes through self-service metrics and design patterns.





































![[DSC Europe 22] The Making of a Data Organization - Denys Holovatyi](https://cdn.slidesharecdn.com/ss_thumbnails/holovatyi-themakingofadataorganization-221130084917-bd5db899-thumbnail.jpg?width=640&height=640&fit=bounds)





























