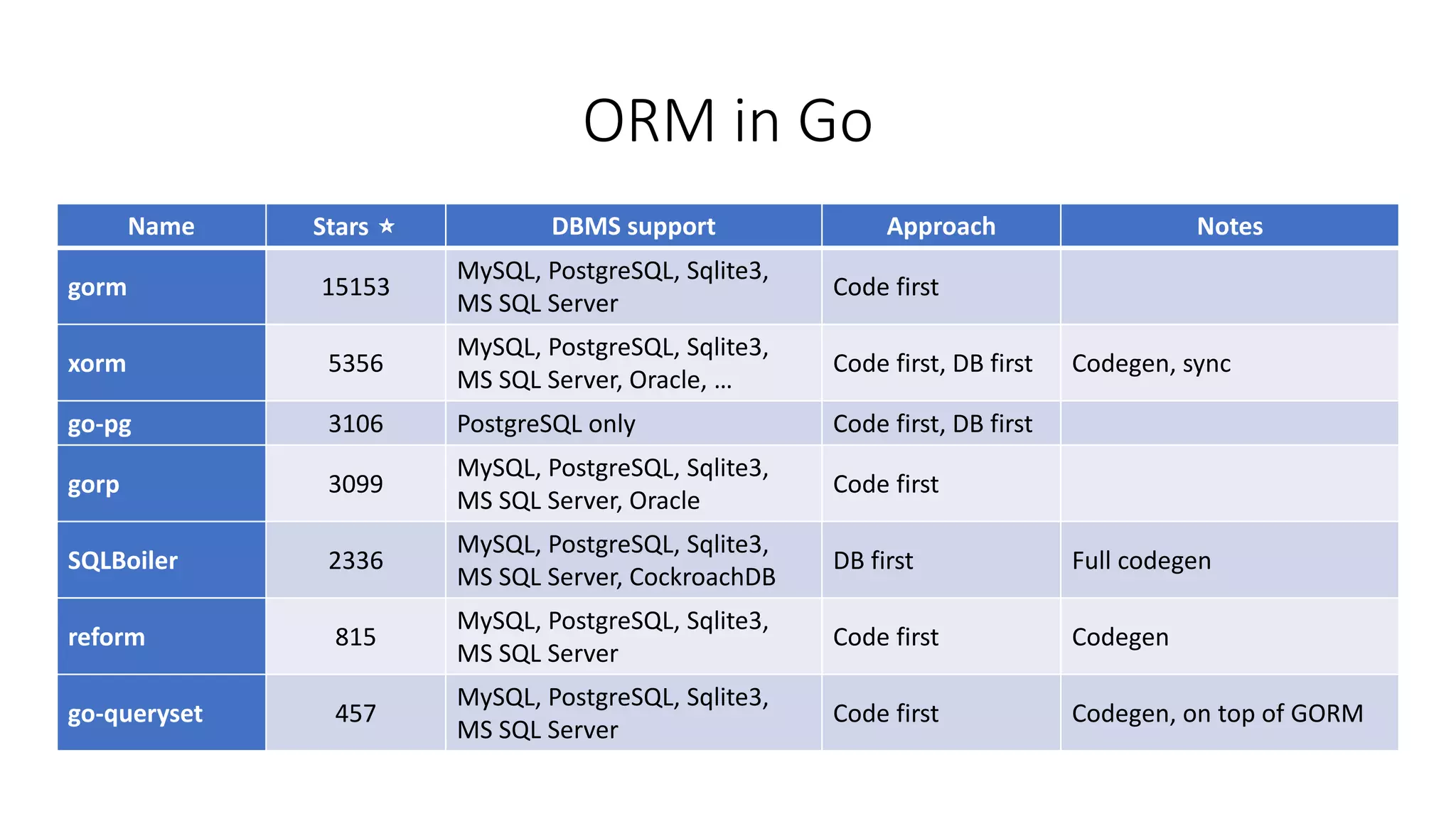
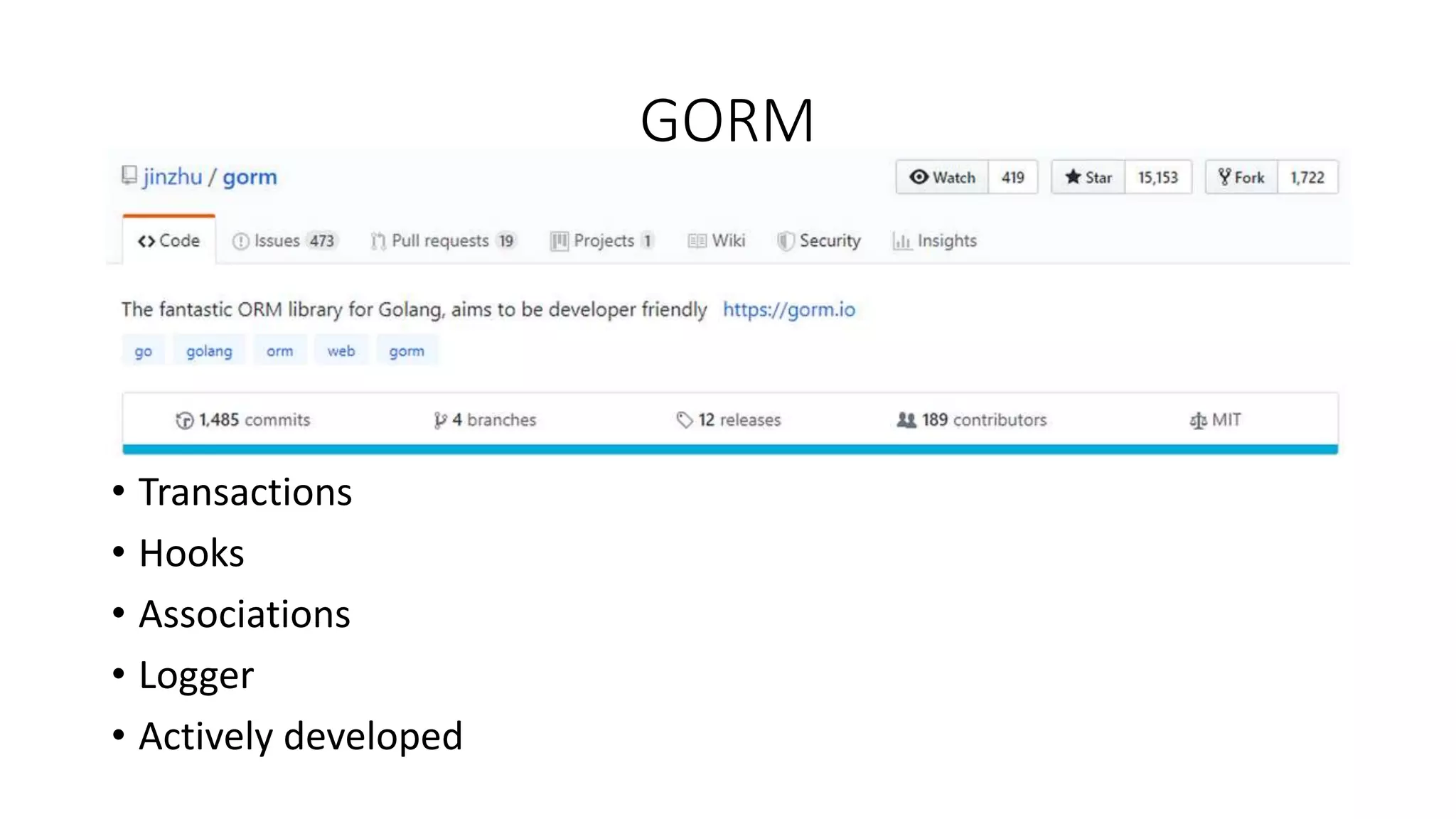
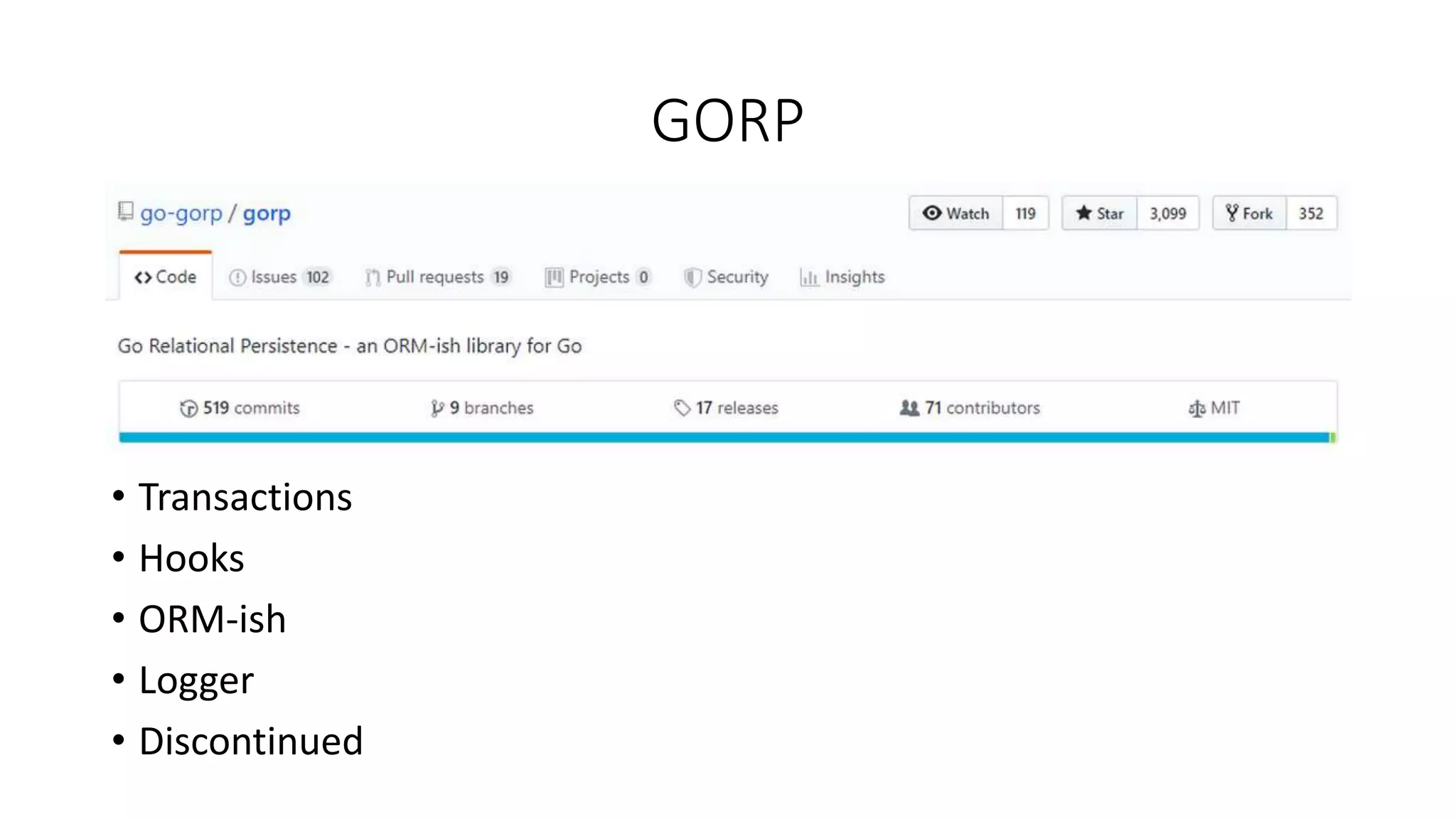
The document discusses Object-Relational Mapping (ORM) frameworks in Go, detailing various approaches such as code-first and database-first methods. It highlights several popular ORM libraries, including GORM and Gorp, and provides tips on effective caching and query explanation functions. Additionally, it outlines the pros and cons of using ORM in Go development.







![Caching in GORM: caching marker
var target []struct {
FileName string `gorm:"column:file_name"`
}
db := c.DB().Table("files").
Where("file_id = ?", fileID).
Select("file_name").
Set(“cachemarker”, &target).
Scan(&target)](https://image.slidesharecdn.com/orm-190930102728/75/ORM-in-Go-Internals-tips-tricks-11-2048.jpg)
![GORM: Explain query
func explainAnalyzeCallback(scope *gorm.Scope) {
vars := strings.TrimPrefix(fmt.Sprintf("%#v", scope.SQLVars), "[]interface {}")
result := []string{fmt.Sprintf("nn%s %sn", scope.SQL, vars)}
query := fmt.Sprintf("EXPLAIN (ANALYZE, COSTS, VERBOSE, BUFFERS) %s", scope.SQL)
rows, err := scope.SQLDB().Query(query, scope.SQLVars...)
if err != nil {…}
defer func() { _ = rows.Close() }()
… // concatenate result
scope.Log(strings.Join(result, "n"))
}](https://image.slidesharecdn.com/orm-190930102728/75/ORM-in-Go-Internals-tips-tricks-12-2048.jpg)
![GORP: Explain query
func (m GorpExplainLogger) Printf(format string, v ...interface{}) {
query := strings.TrimLeftFunc(v[1].(string), unicode.IsSpace)
ok, values := parseArgs(v[2].(string))
if !ok {...}
var result []string
if _, err := m.executor.Select(&result, "EXPLAIN (ANALYZE, COSTS, VERBOSE, BUFFERS) ”
+ query, values...); err != nil {…}
for _, s := range result {
m.logger.Printf("%s", s)
}
}](https://image.slidesharecdn.com/orm-190930102728/75/ORM-in-Go-Internals-tips-tricks-13-2048.jpg)





























































