Audit (Denetim)
Şirketler;
• Denetimkapsamına alacakları en önemli ve kritik
gördükleri tablolarını belirlemelidir, bu listeyi zaman zaman
güncellemelidir,
• Veritabanlarında kullanıcı aktivitelerini denetlemeli,
loglarını tutmalıdır, logların günlük, aylık, yıllık periyotlarda
büyüme hızlarını izlemeli ve buna göre gerekli kaynak
(Disk, RAM, vs…) artışına gitmelidir,
• Bu logların backup’larını almalıdır,
• Anlık kritik işlemler hakkında Alert mailler ile haberdar
olmalıdır,
• Tüm bu aktiviteleri raporlayabilmelidir.
3
4.
Veritabanı Güvenliği içinKullanılan Uygulamalar
• Veritabanı Güvenliğini, dış kaynaklı felaketlerden ve kötü
niyetli kullanıcılardan korumak için sağlarız.
• Biz bu sunumda kötü niyetli kullanıcılardan veritabanımızı,
dolayısıyla tablespace, tablo, index, package, procedure,
function, vs… tüm objelerimizi nasıl korumaya alırız,
bunlar üzerinde yapılan aktiviteleri (transaction) nasıl
izleriz, nasıl loglarız ve nasıl raporlarız, bunları
inceleyeceğiz,
• Kötü niyetli kullanıcı neler yapabilir? En önemli tablo ve
veritabanı objelerini silebilir, erişmesi yasak olan
tablolarda işlem yapabilir, başka kullanıcılara gizli yetkiler
verebilir, Audit loglarını silebilir, gizli bilgilere erişebilir…
4
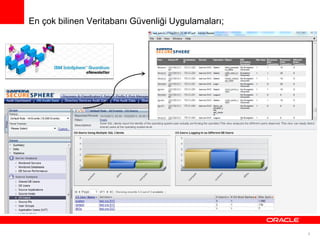
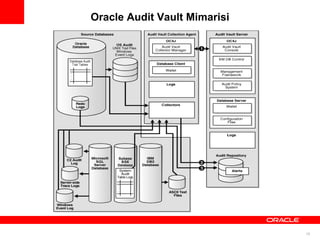
Oracle Audit Vault10.3
Özet olarak açıklamak gerekirse, veritabanı denetim ayarlarını yapabileceğimiz ve
kullanıcıların tüm veritabanı aktivitelerini raporlayabileceğimiz uygulamadır.
6
7.
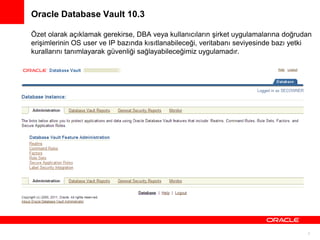
Oracle Database Vault10.3
Özet olarak açıklamak gerekirse, DBA veya kullanıcıların şirket uygulamalarına doğrudan
erişimlerinin OS user ve IP bazında kısıtlanabileceği, veritabanı seviyesinde bazı yetki
kurallarını tanımlayarak güvenliği sağlayabileceğimiz uygulamadır.
7
8.
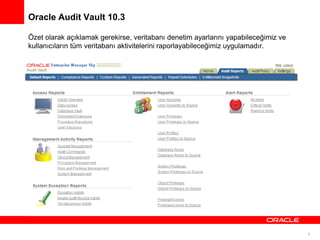
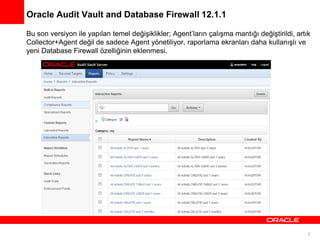
Oracle Audit Vaultand Database Firewall 12.1.1
Bu son versiyon ile yapılan temel değişiklikler; Agent’ların çalışma mantığı değiştirildi, artık
Collector+Agent değil de sadece Agent yönetiliyor, raporlama ekranları daha kullanışlı ve
yeni Database Firewall özelliğinin eklenmesi.
8
9.
Oracle Audit Vault12.1.1 ile beraber gelen Database Firewall uygulaması network
üzerinde yetkisiz SQL trafiğini database’e ulaşmadan önce izler ve bloke eder. fwadmin
(Firewall Admin) en yetkili kullanıcı olarak tüm gerekli sistem ayarlarını yapabilir.
9
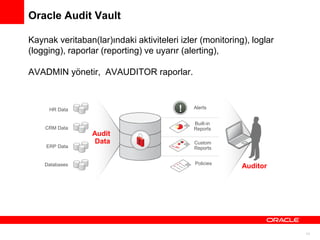
Oracle Audit Vault
Kaynakveritaban(lar)ındaki aktiviteleri izler (monitoring), loglar
(logging), raporlar (reporting) ve uyarır (alerting),
AVADMIN yönetir, AVAUDITOR raporlar.
!
HR Data
CRM Data
ERP Data
Databases
Audit
Data
Alerts
Built-in
Reports
Custom
Reports
Policies
Auditor
11
12.
AUDIT_TRAIL (Denetim İzi):
None:Denetime Kapalı
DB: Kayıtlar SYS.AUD$ tablosunda tutulur
DB, EXTENDED: Kayıtlar SYS.AUD$ tablosunda SQL bind ve SQL text kolon bilgileri ile
birlikte tutulur
OS: *.aud uzantılı audit dosyaları Operating sistemde audit_file_dest dizininde tutulur
XML: Kayıtlar Operating sistemde XML formatında tutulur
XML, EXTENDED: Kayıtlar Operating sistemde XML formatında SQL bind ve SQL text
kolon bilgileri ile birlikte tutulur
show parameter audit;
veya
SQL> select name, value from v$parameter where lower(name) like 'audit%';
audit_file_dest
string
/oracle/db/admin/<instance_name>/adump
audit_syslog_level
string
audit_sys_operations
boolean TRUE
audit_trail
string
OS
ALTER SYSTEM SET AUDIT_TRAIL=OS SCOPE=SPFILE;
12
13.
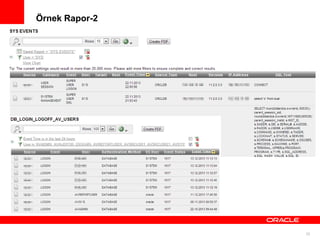
Alert Mekanizması
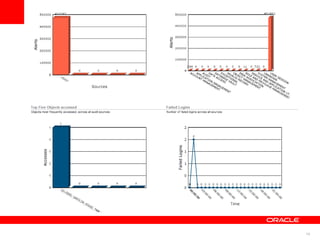
İstenmeyen durumlarınbildirimlerini almak için Alert mekanizması oluşturabiliriz.
Belli periyotlarda grafiksel olarak Alert’lerin istatistiğini görebiliriz.
13
Mail’imize raporun linkigönderildiği gibi raporun kendisi de attach edilmiş olarak pdf
formatında gönderilebilmektedir, mail hesabımızın kotasının raporlardan dolayı
büyümemesi için raporun linkinin gönderilmesi de tercih edilebilir.
16
17.
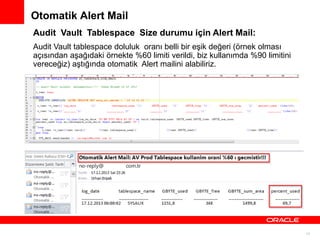
Otomatik Alert Mail
AuditVault Tablespace Size durumu için Alert Mail:
Audit Vault tablespace doluluk oranı belli bir eşik değeri (örnek olması
açısından aşağıdaki örnekte %60 limiti verildi, biz kullanımda %90 limitini
vereceğiz) aştığında otomatik Alert mailini alabiliriz.
17
18.
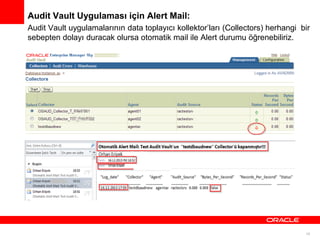
Audit Vault Uygulamasıiçin Alert Mail:
Audit Vault uygulamalarının data toplayıcı kollektor’ları (Collectors) herhangi bir
sebepten dolayı duracak olursa otomatik mail ile Alert durumu öğrenebiliriz.
18
19.
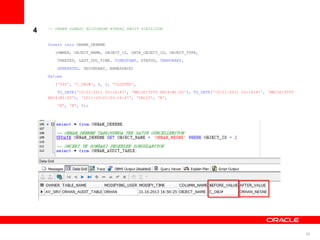
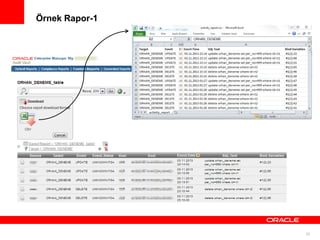
Triger ile Denetleme
Çokönemli gördüğümüz 2-3 tablo için trigger yapısıyla ‘old value’ , ‘new value’
değerlerini loglayabiliriz, ‘ORHAN_TRIGGER_DENEME’ isminde oluşturduğum triger’ın
demosunu inceleyelim;
1
-- ÖRNEK TABLO YARATILIYOR
CREATE TABLE ORHAN_DENEME
2
(
-- AUDIT KAYITLARINI TUTACAK BIR TABLO OLUSTURULUR
CREATE TABLE ORHAN_AUDIT_TABLE (
OWNER VARCHAR2(30),
OWNER
OBJECT_NAME
VARCHAR2(128 BYTE),
SUBOBJECT_NAME
VARCHAR2(30 BYTE),
OBJECT_ID
NUMBER,
DATA_OBJECT_ID
NUMBER,
OBJECT_TYPE
VARCHAR2(19 BYTE),
CREATED
DATE,
LAST_DDL_TIME
DATE,
TIMESTAMP
VARCHAR2(19 BYTE),
STATUS
VARCHAR2(7 BYTE),
TEMPORARY
VARCHAR2(1 BYTE),
FOR EACH ROW
GENERATED
VARCHAR2(1 BYTE),
DECLARE
SECONDARY
VARCHAR2(1 BYTE),
NAMESPACE
NUMBER,
EDITION_NAME
)
VARCHAR2(30 BYTE),
VARCHAR2(30 BYTE)
TABLE_NAME VARCHAR2(30),
MODIFYING_USER VARCHAR2(30),
MODIFY_TIME DATE DEFAULT SYSDATE,
COLUMN_NAME varchar2(30),
BEFORE_VALUE varchar2(30),
AFTER_VALUE varchar2(30));
3
CREATE OR REPLACE TRIGGER ORHAN_TRIGGER_DENEME
AFTER UPDATE ON ORHAN_DENEME
v_username varchar2(10);
BEGIN
SELECT user INTO v_username FROM dual;
INSERT INTO ORHAN_AUDIT_TABLE ( OWNER, TABLE_NAME,
MODIFYING_USER, MODIFY_TIME, COLUMN_NAME, BEFORE_VALUE, AFTER_VALUE )
VALUES ( 'AV_SRV', 'ORHAN_AUDIT_TABLE', v_username, SYSDATE,
'OBJECT_NAME', :OLD.OBJECT_NAME, :NEW.OBJECT_NAME );
END;
19