Download to read offline






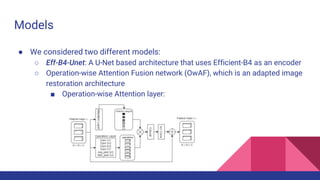

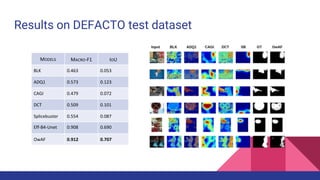






The document discusses the development of an operation-wise attention network for tampering localization, aimed at enhancing content verification on social media and web platforms by addressing disinformation challenges. It presents a fully automatic fusion approach combining various forensic algorithms to improve tampering detection results, making them more interpretable for non-experts. The findings indicate that the proposed method achieves higher accuracy in forgery detection compared to existing methods, while also noting its limitations and potential for future improvements.
















































































