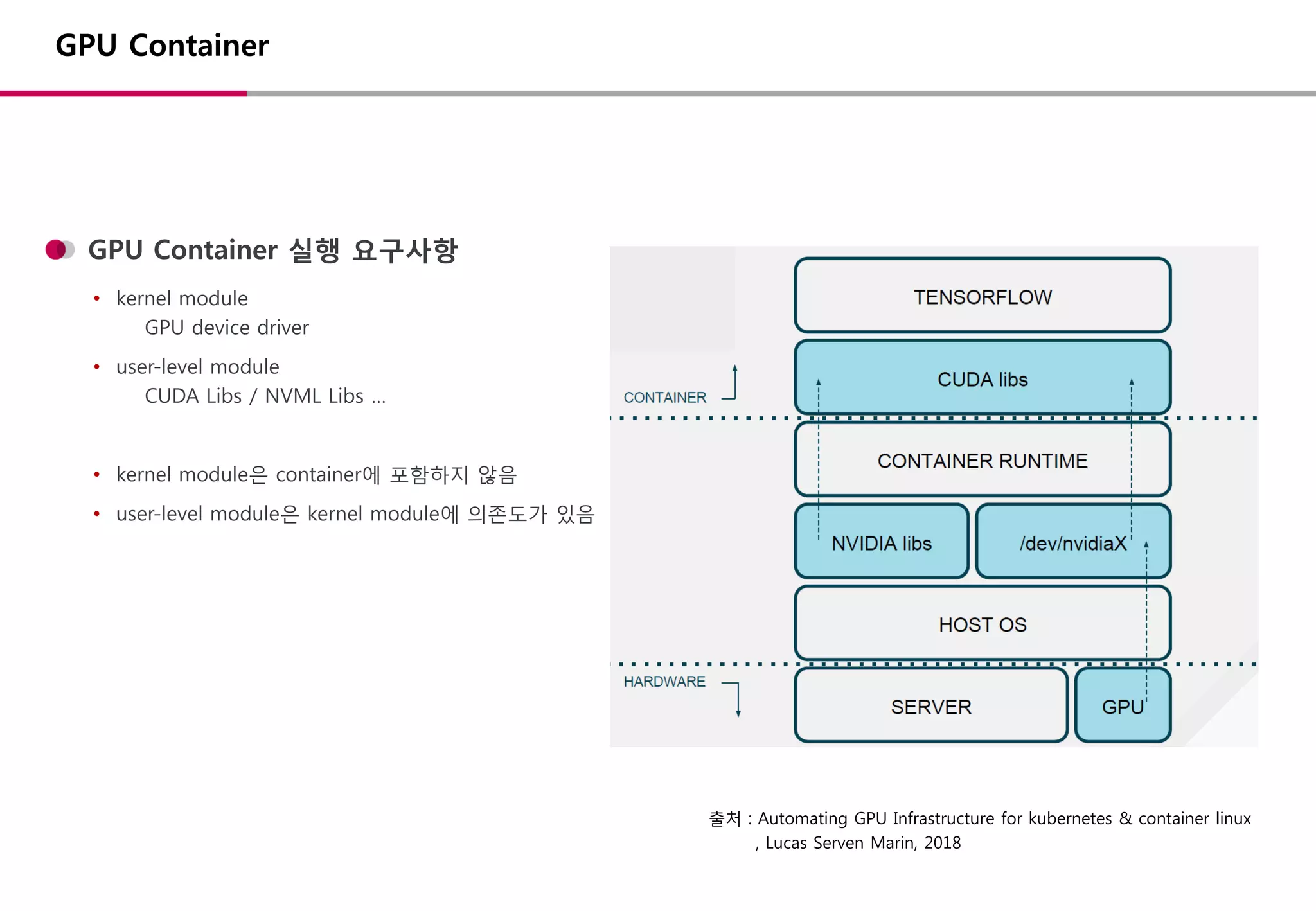
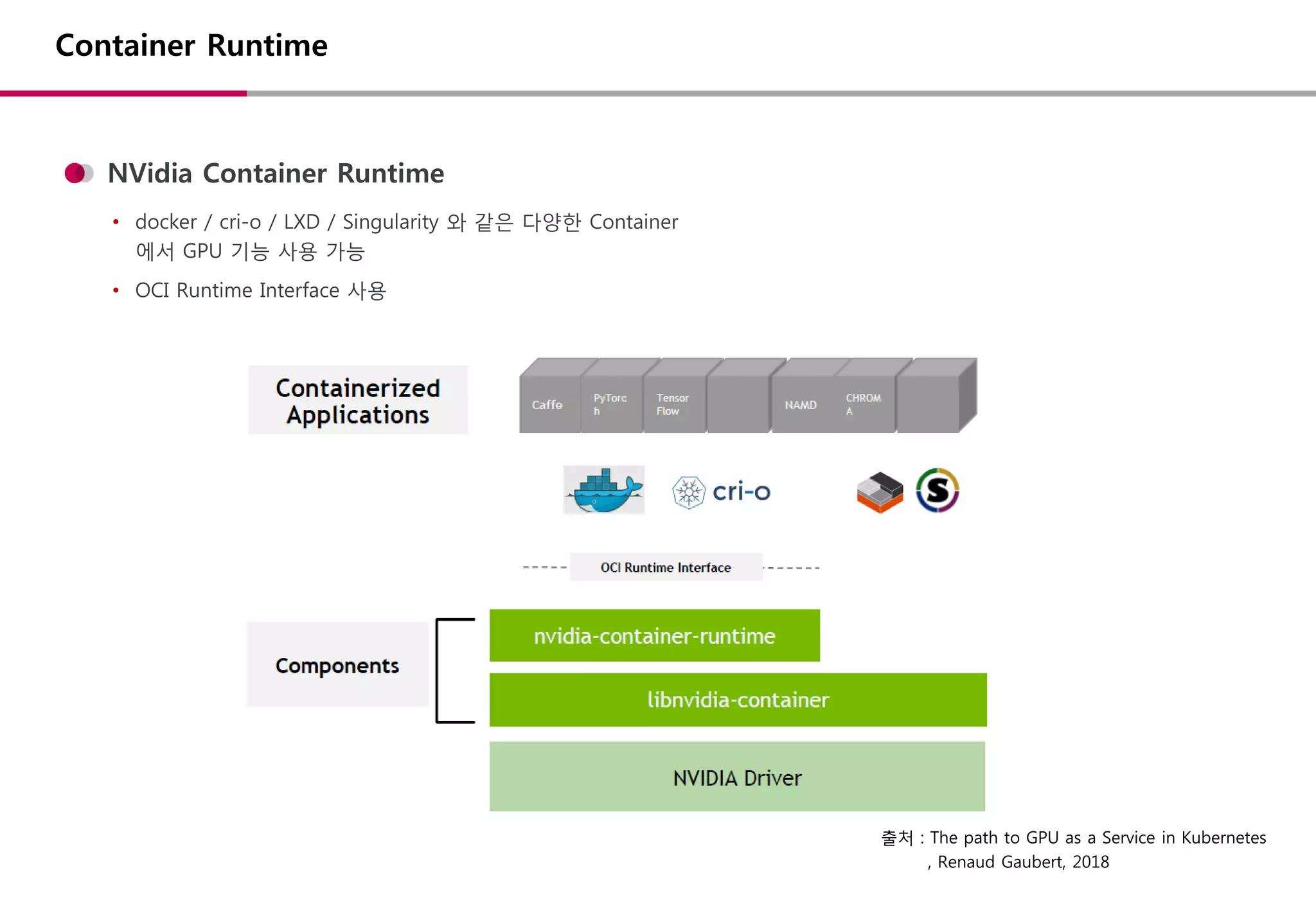
NVidia Container Runtime
•docker / cri-o / LXD / Singularity 와 같은 다양한 Container
에서 GPU 기능 사용 가능
• OCI Runtime Interface 사용
Container Runtime
출처 : The path to GPU as a Service in Kubernetes
, Renaud Gaubert, 2018
11.
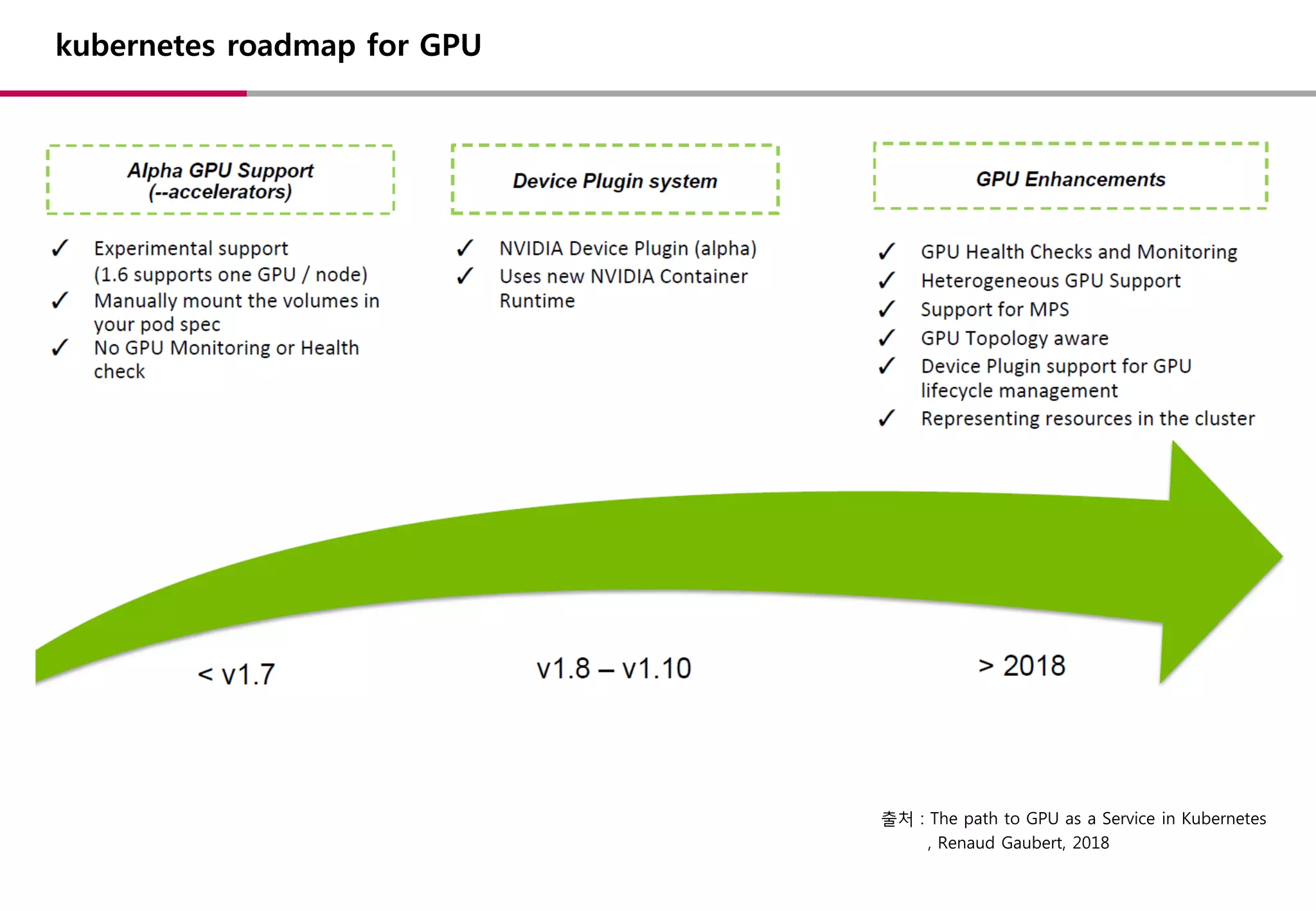
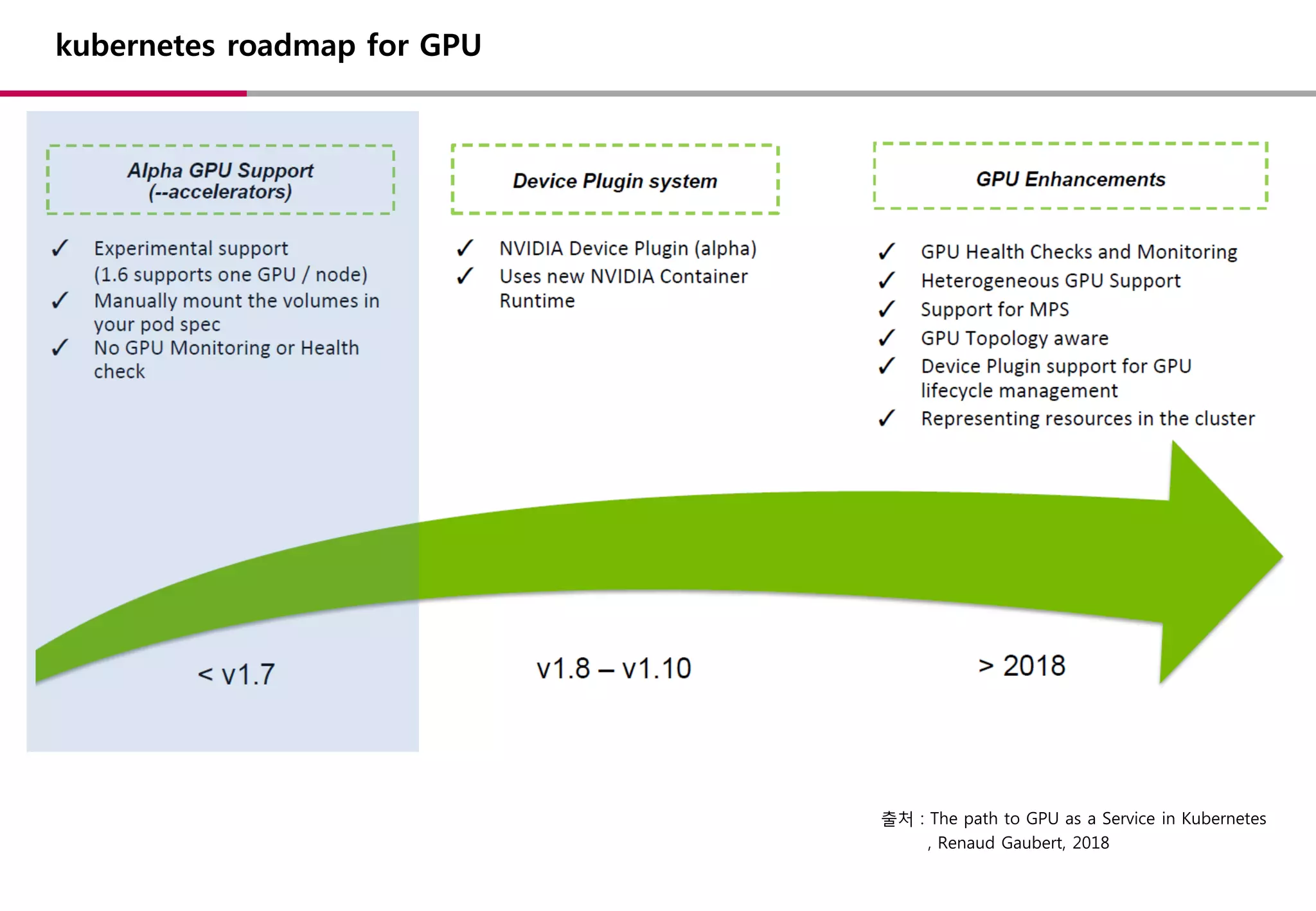
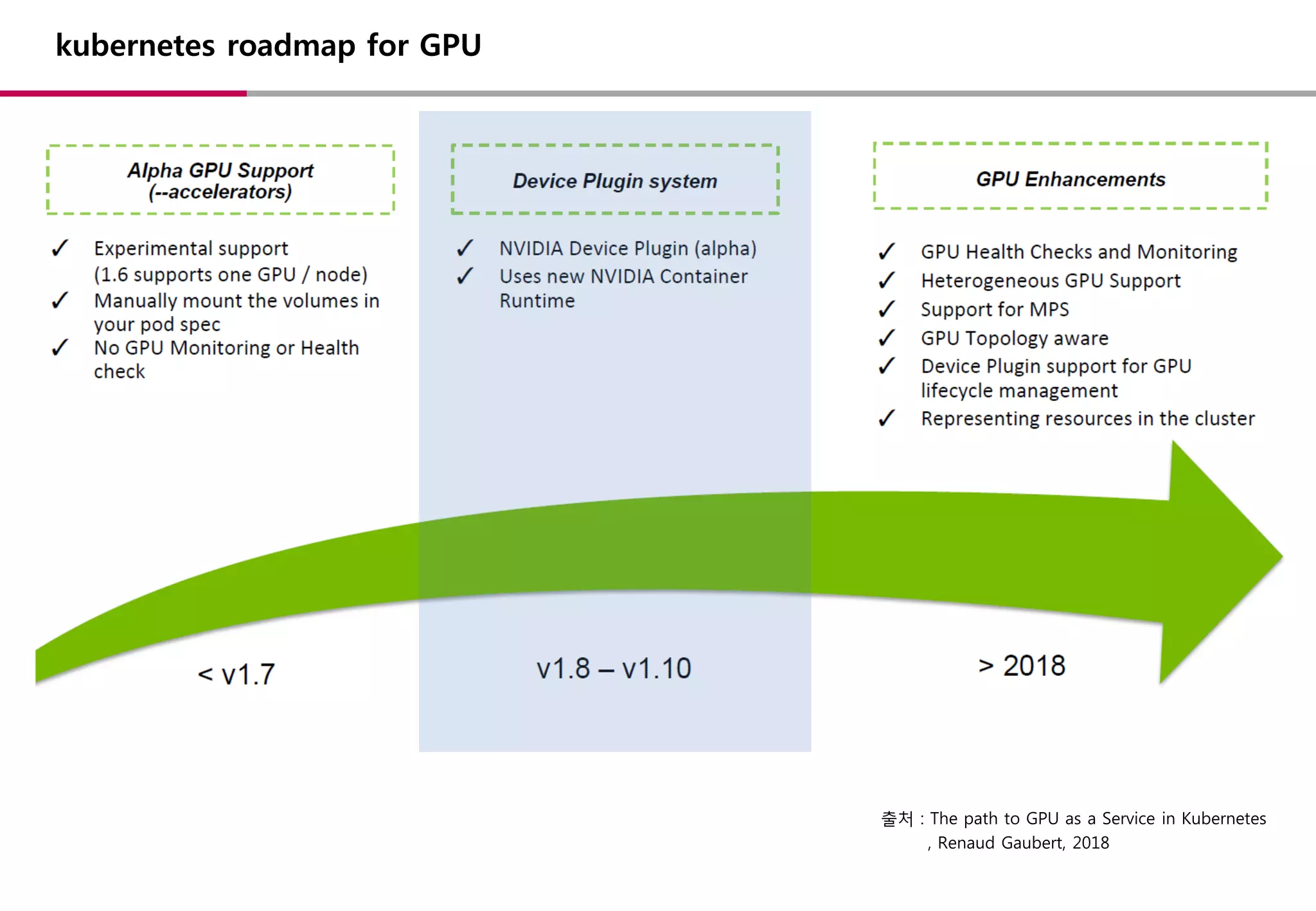
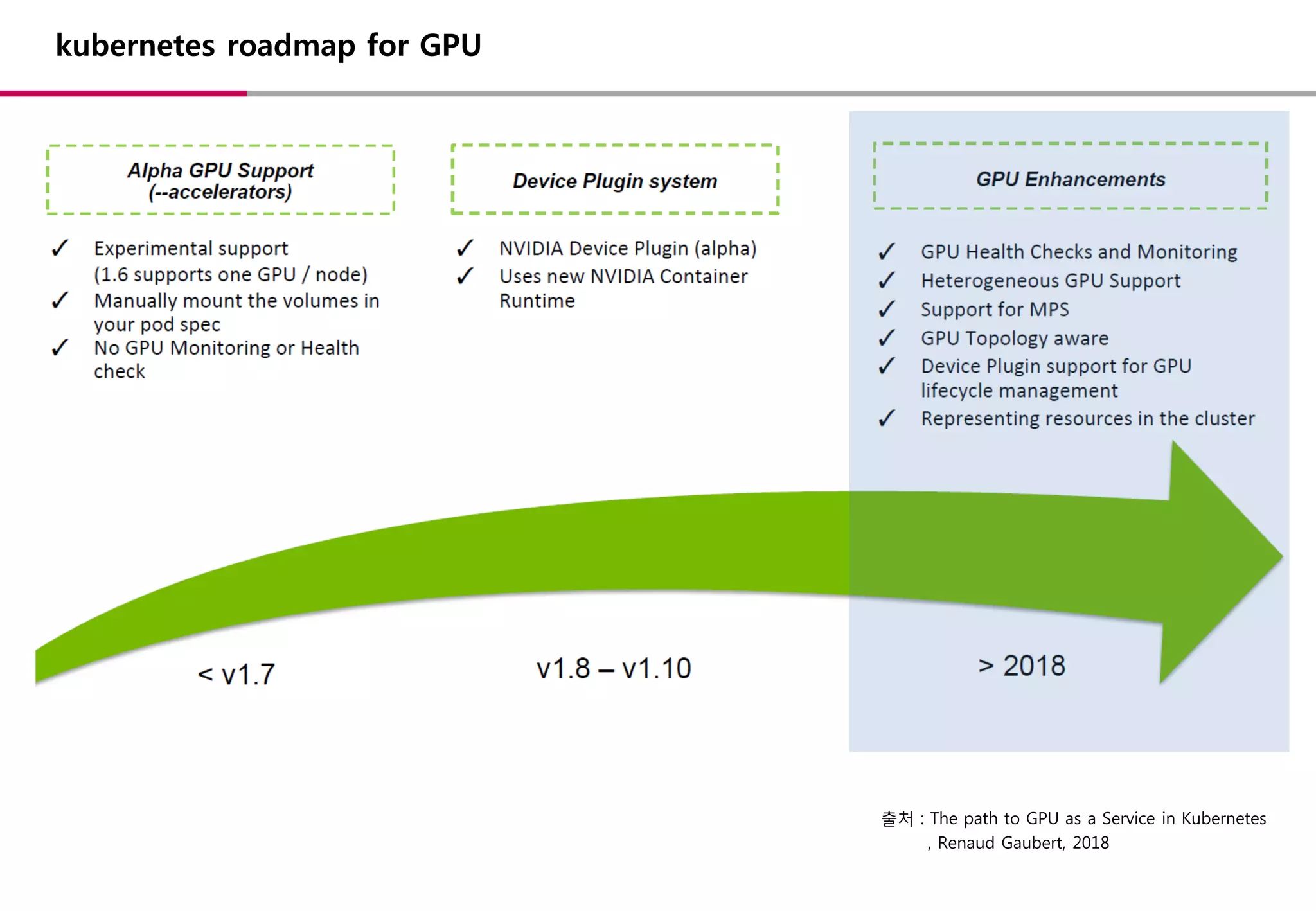
kubernetes roadmap forGPU
출처 : The path to GPU as a Service in Kubernetes
, Renaud Gaubert, 2018
12.
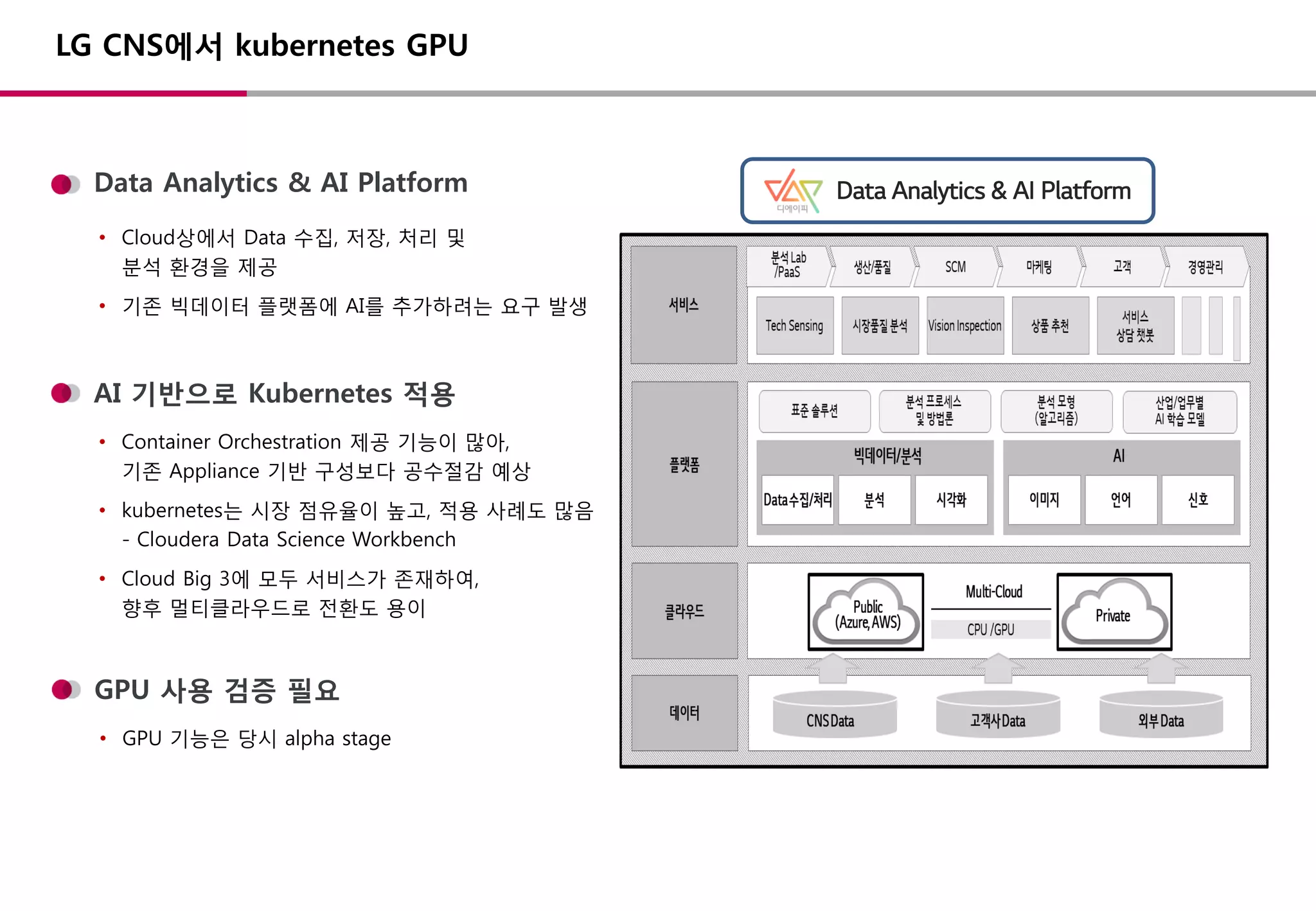
AI 기반으로 Kubernetes적용
Data Analytics & AI Platform
• Container Orchestration 제공 기능이 많아,
기존 Appliance 기반 구성보다 공수절감 예상
• kubernetes는 시장 점유율이 높고, 적용 사례도 많음
- Cloudera Data Science Workbench
• Cloud Big 3에 모두 서비스가 존재하여,
향후 멀티클라우드로 전환도 용이
• Cloud상에서 Data 수집, 저장, 처리 및
분석 환경을 제공
• 기존 빅데이터 플랫폼에 AI를 추가하려는 요구 발생
LG CNS에서 kubernetes GPU
Data Analytics & AI Platform
GPU 사용 검증 필요
• GPU 기능은 당시 alpha stage
13.
목적
기간
• alpha stage인GPU 기능이 서비스에 문제가 없는지 검증
• NGC를 통해 로컬에서 수행하는 AI어플리케이션과 동일한 수준의 성능을 보장하는지 검증
• 1차 테스트 (3/12~3/30) : 기본 구성 및 기능위주 테스트
• 2차 테스트 (4/16~4/27) : 장비 추가 및 비기능 위주 테스트
kubernetes GPU PoC
테스트 케이스
• 기능 : unit test 케이스 중 GPU관련 필요검증항목 추출 (46/901)
https://github.com/kubernetes/kubernetes/blob/release-1.9/test/test_owners.csv
• 안정성 : GPU 주요 컴포넌트의 장애 테스트
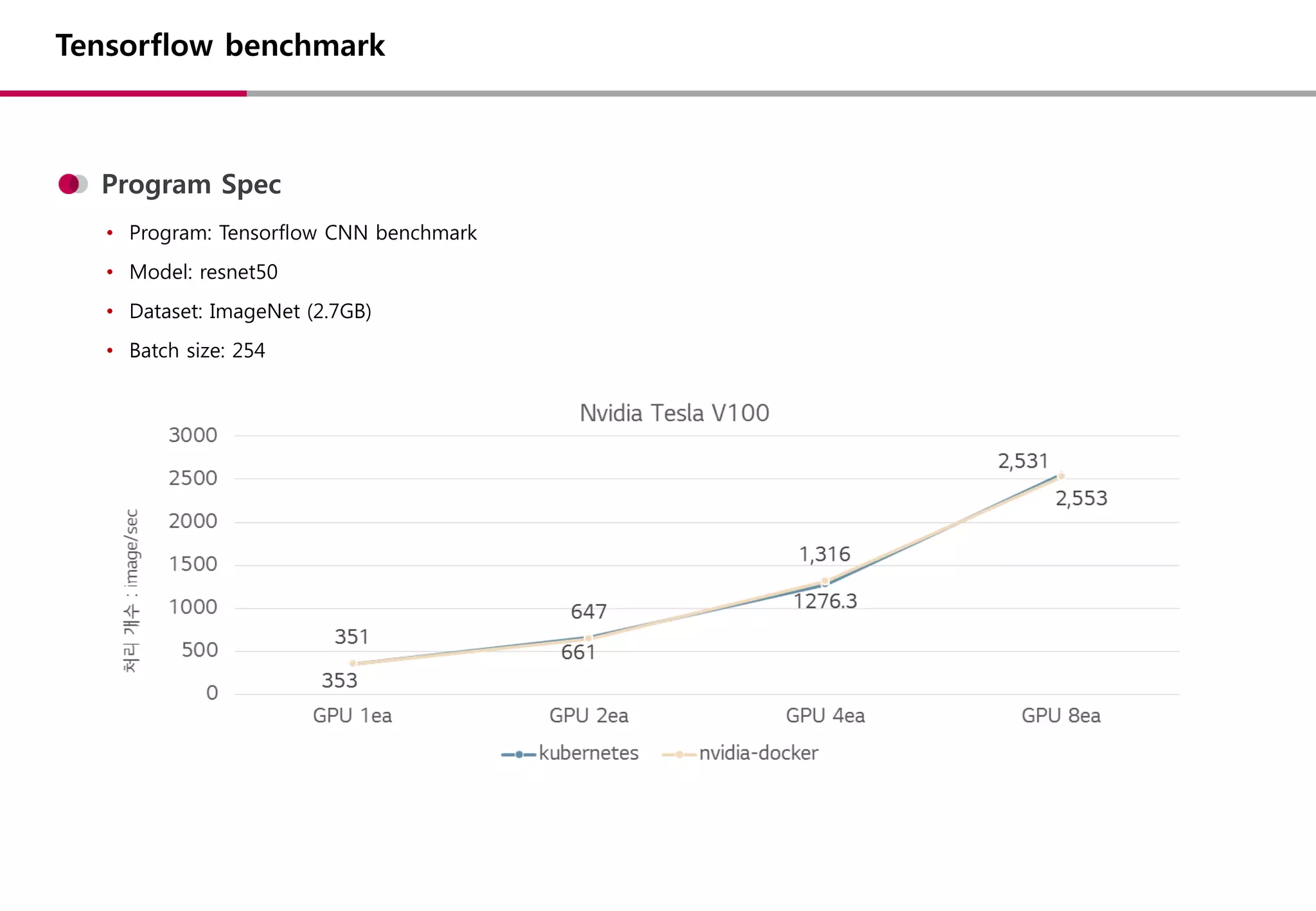
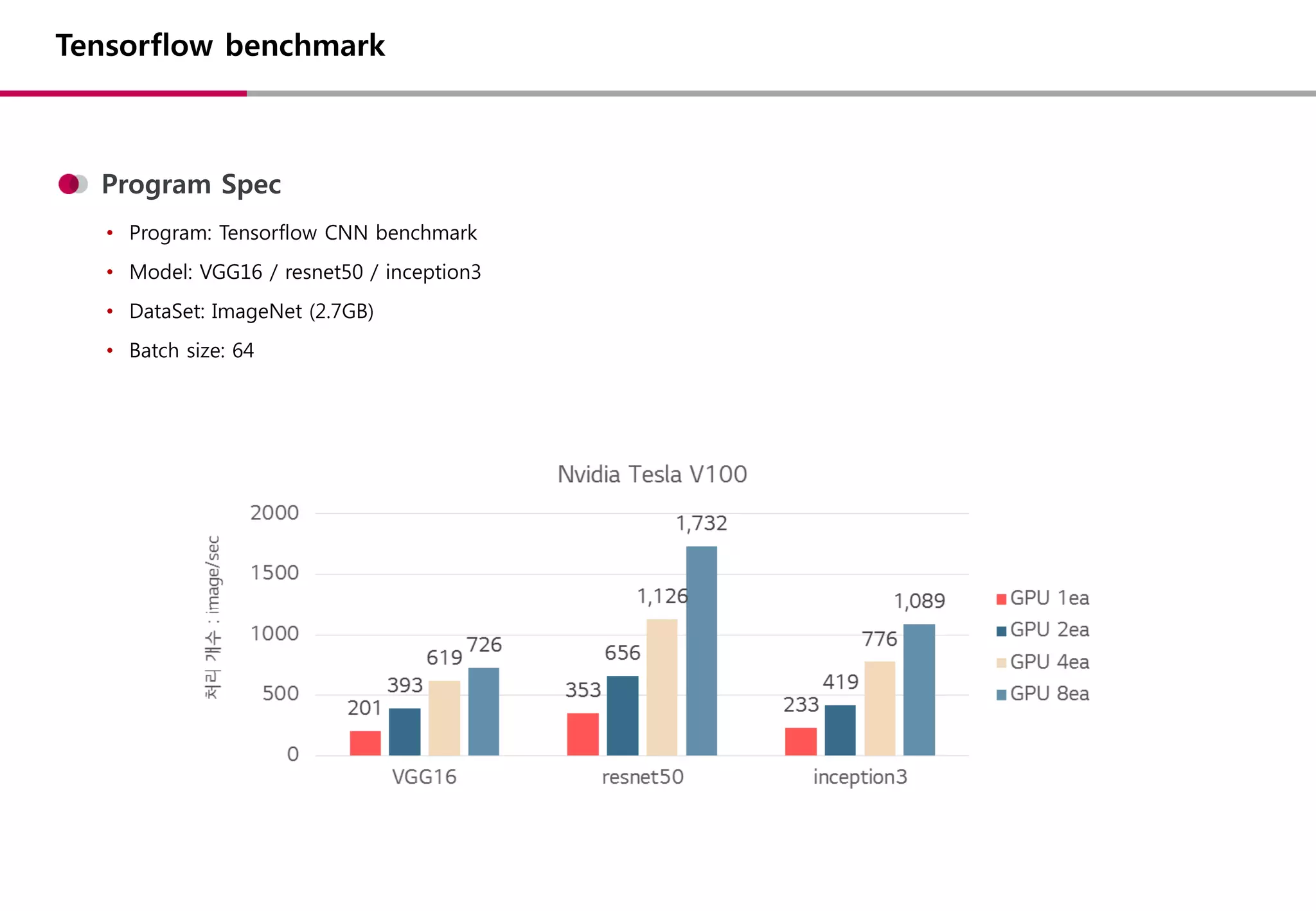
• 어플리케이션 : 공개되어있는 benchmark 프로그램을 이용 (Tensorflow / Caffee…)
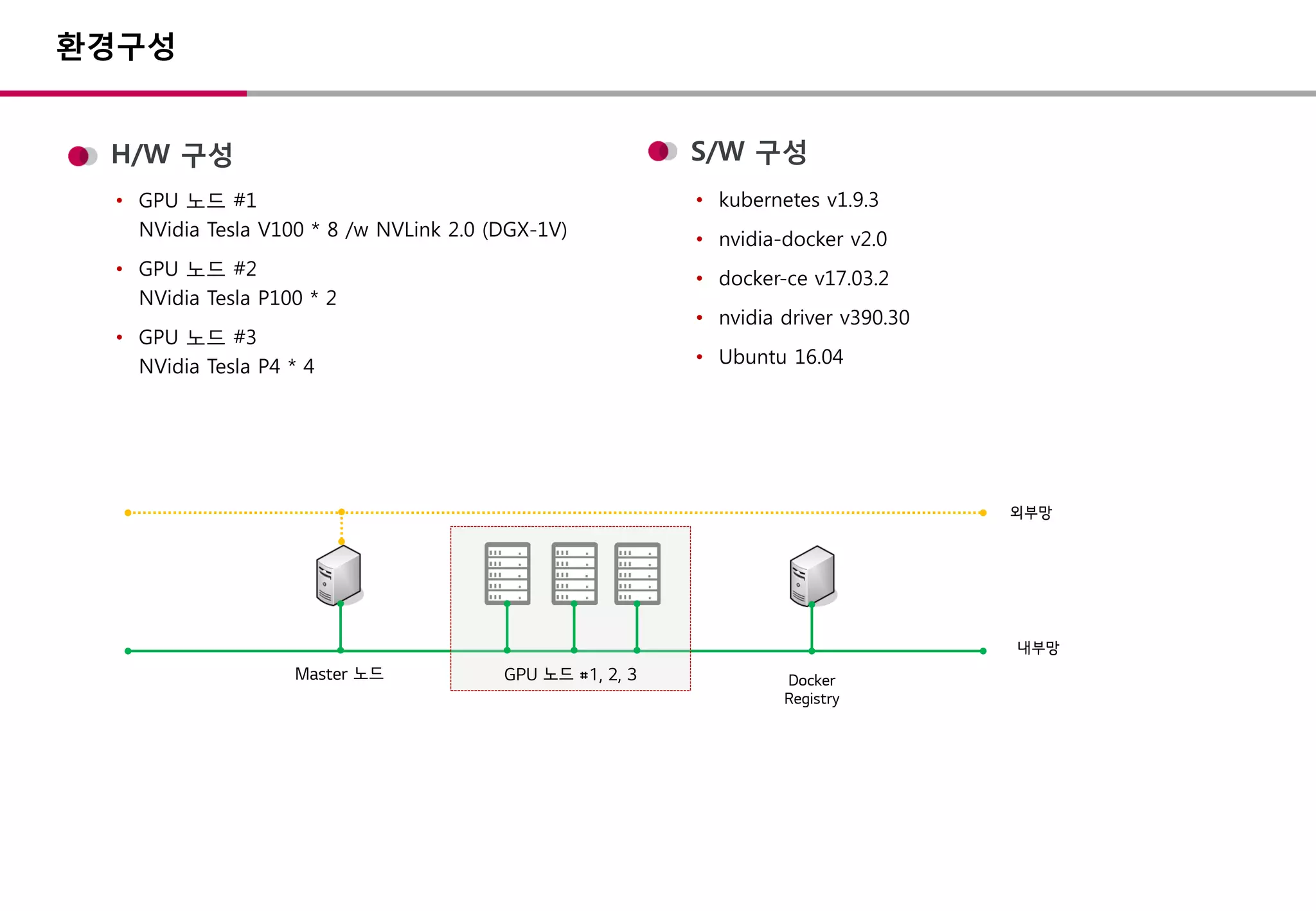
kubernetes GPU 설치– v1.9
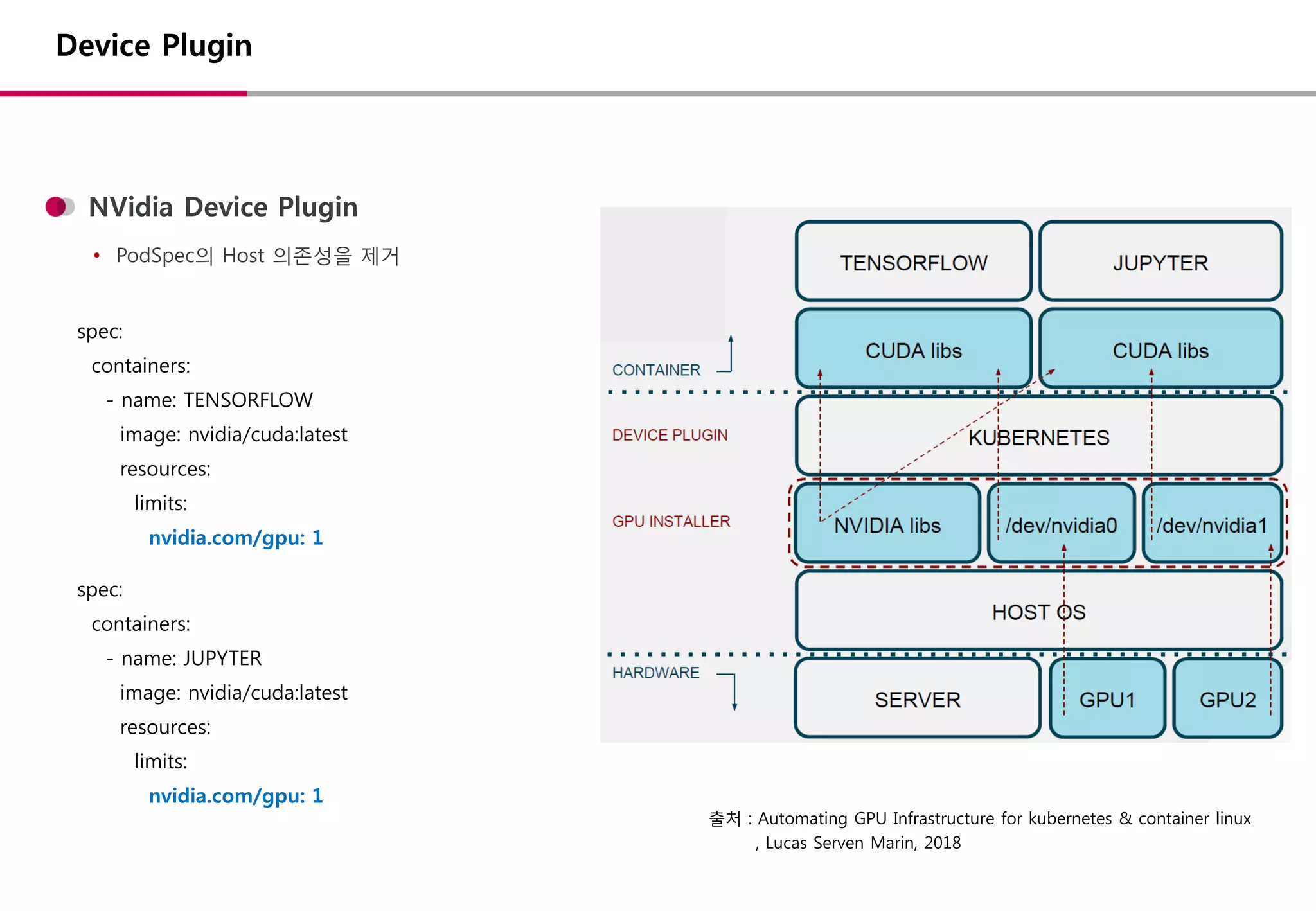
device plugins 설정
• kubelet : --feature-gates="DevicePlugins=true“
container-runtime 설치
• nvidia driver 설치 (>= v.361.93)
• nvidia-docker 2.0 설치 (docker 버전에 맞춤)
• daemon.json : default runtime 변경
device plugin 설치
• device plugin 설치 (DaemonSet)
• node labeling (accelerator=[value])
출처 : https://kubernetes.io/docs/tasks/manage-gpus/scheduling-gpus/
https://github.com/NVIDIA/k8s-device-plugin
16.
docker image sample
FROMnvcr.io/nvidia/tensorflow:18.02-py3
RUN mkdir -p /data/cifar10_estimator
ADD cifar10_estimator/* /data/cifar10_estimator/
WORKDIR /data/cifar10_estimator/
RUN python generate_cifar10_tfrecords.py --data-dir=${PWD}/cifar-10-data
CMD exec /bin/bash -c "trap : TERM INT; sleep infinity & wait"
Dockerfile NVidia Container Registry
• NVidia에 의해 최적화된 검증된 Deep Learning
Framework 이미지 제공
• NVidia GPU가 적용된 시스템이면 사용 가능
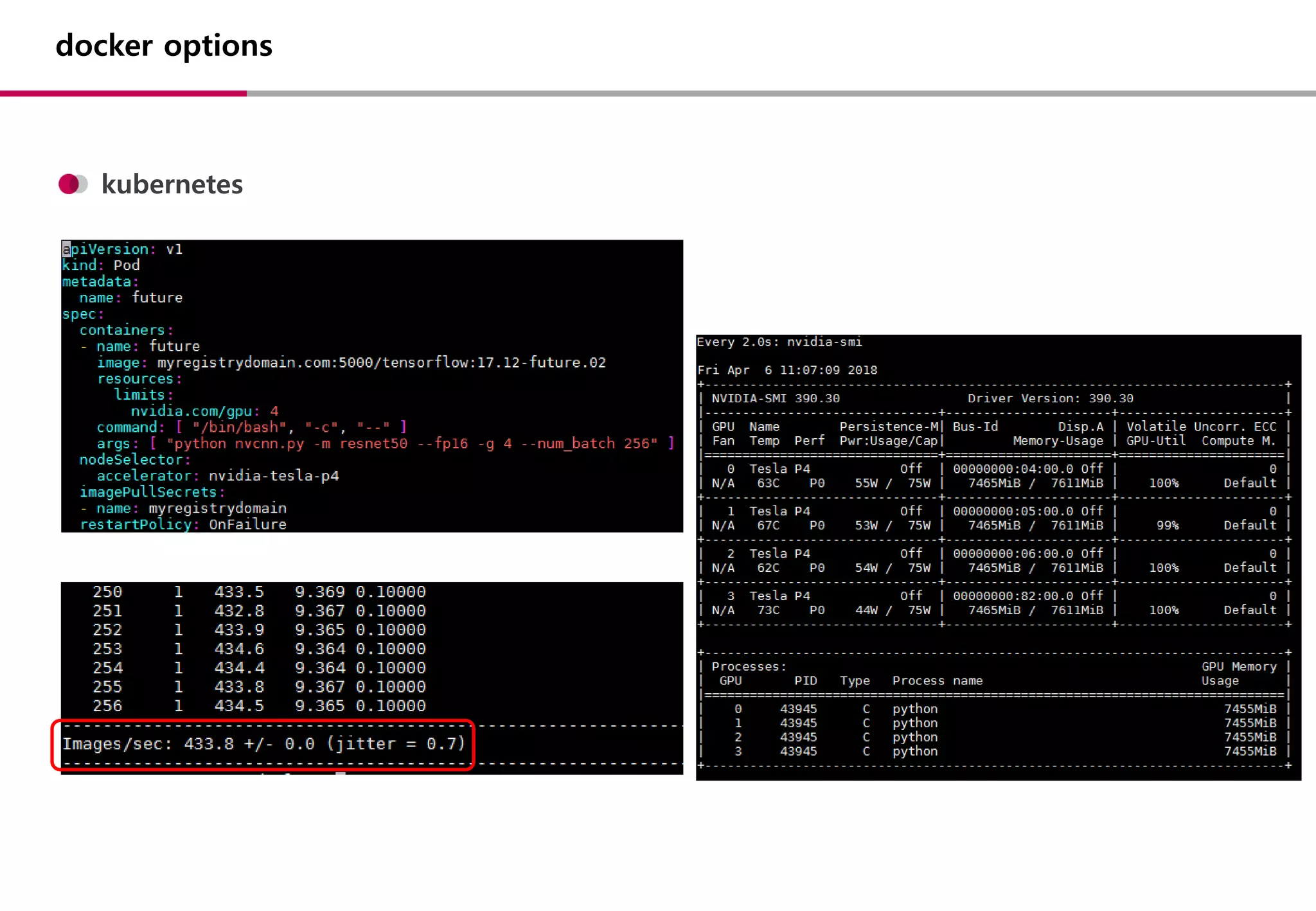
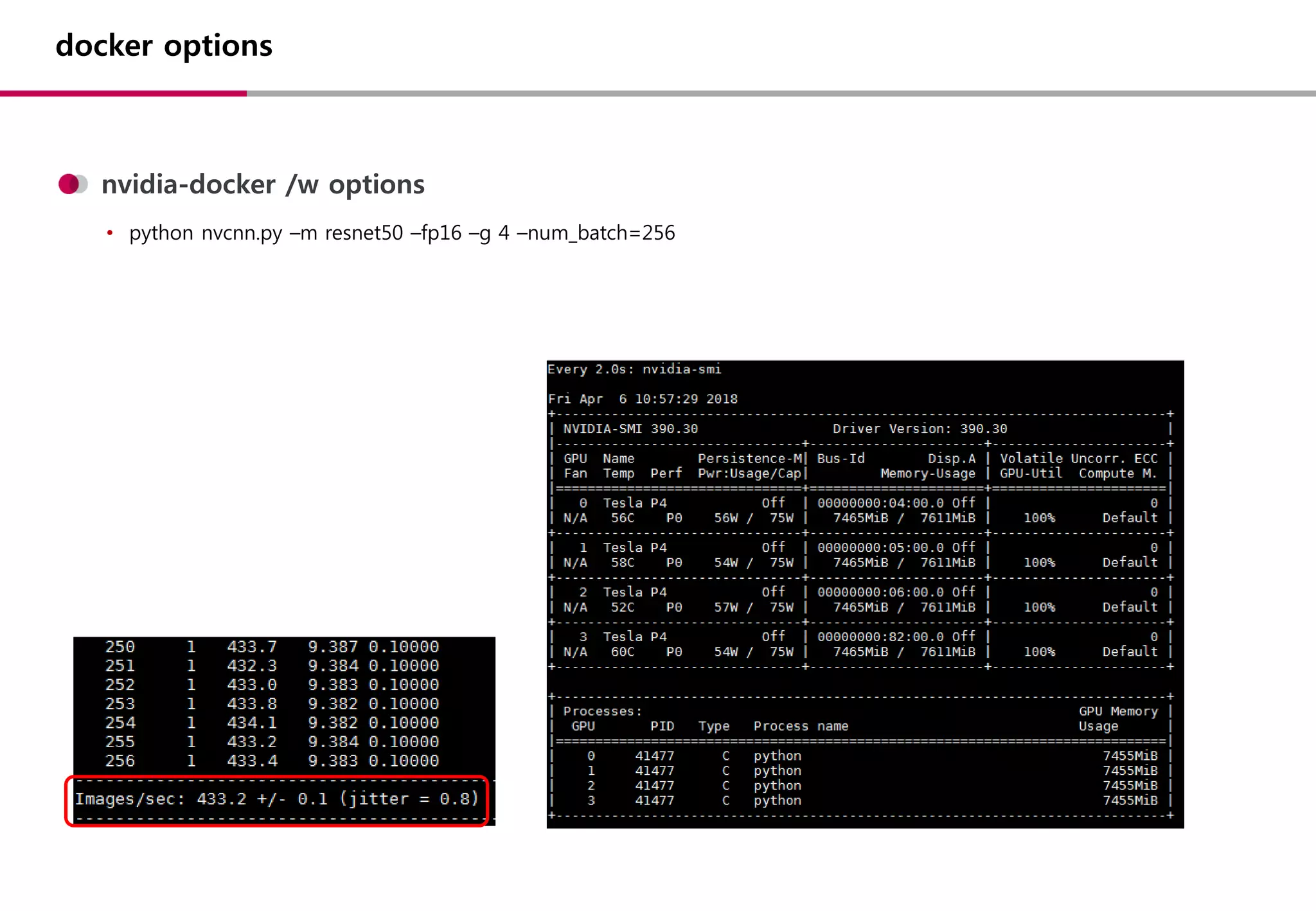
docker options
NOTE: TheSHMEM allocation limit is set to the default of 64MB. This may be
insufficient for TensorFlow. NVIDIA recommends the use of the following flags:
nvidia-docker run --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 ...
--shm-size
• container 내부 IPC 통신시 사용할 Share Memory 크기
• 기본값 : 64mb
--ulimit memlock
• 메모리 주소공간 최대크기
• 기본값 : 64kb
• -1이면 swap을 사용하지 않음
--ulimit stack
• 스택 크기
• 기본값 : 8192kb
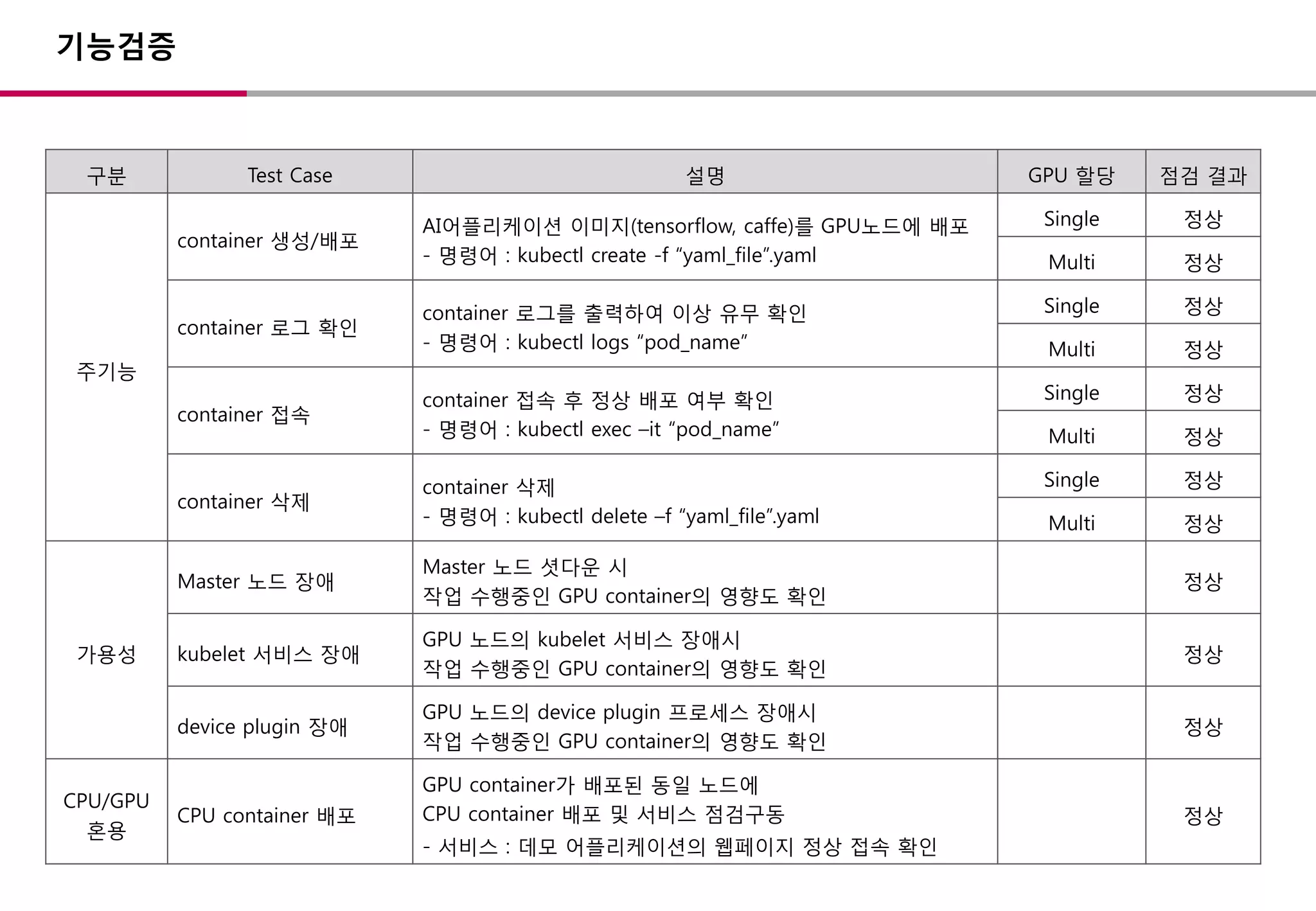
기능검증
구분 Test Case설명 GPU 할당 점검 결과
주기능
container 생성/배포
AI어플리케이션 이미지(tensorflow, caffe)를 GPU노드에 배포
- 명령어 : kubectl create -f “yaml_file”.yaml
Single 정상
Multi 정상
container 로그 확인
container 로그를 출력하여 이상 유무 확인
- 명령어 : kubectl logs “pod_name”
Single 정상
Multi 정상
container 접속
container 접속 후 정상 배포 여부 확인
- 명령어 : kubectl exec –it “pod_name”
Single 정상
Multi 정상
container 삭제
container 삭제
- 명령어 : kubectl delete –f “yaml_file”.yaml
Single 정상
Multi 정상
가용성
Master 노드 장애
Master 노드 셧다운 시
작업 수행중인 GPU container의 영향도 확인
정상
kubelet 서비스 장애
GPU 노드의 kubelet 서비스 장애시
작업 수행중인 GPU container의 영향도 확인
정상
device plugin 장애
GPU 노드의 device plugin 프로세스 장애시
작업 수행중인 GPU container의 영향도 확인
정상
CPU/GPU
혼용
CPU container 배포
GPU container가 배포된 동일 노드에
CPU container 배포 및 서비스 점검구동
- 서비스 : 데모 어플리케이션의 웹페이지 정상 접속 확인
정상
DeepBench
• Deep Learning운영하는데 어떤 하드웨어가 좋은 성능을 제공하는지 답변을 위해 작성
• Tensorflow와 같은 top level 프레임워크가 아닌 low level library를 이용하여 검증
• Baidu Research에서 자체 수행한 결과 데이터를 공유
Baidu DeepBench
출처 : https://github.com/baidu-research/DeepBench
25.
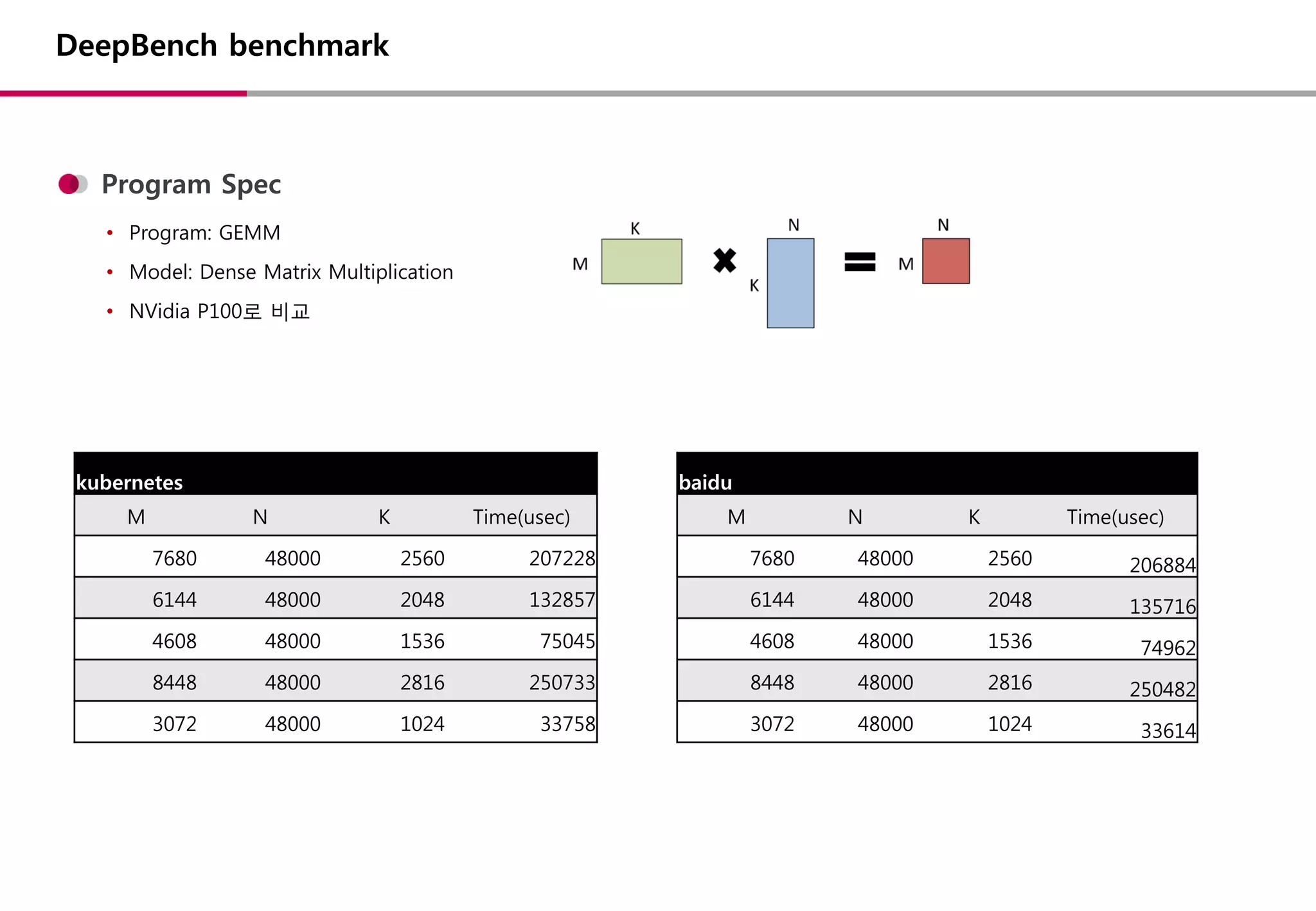
DeepBench benchmark
Program Spec
•Program: GEMM
• Model: Dense Matrix Multiplication
• NVidia P100로 비교
baidu
M N K Time(usec)
7680 48000 2560 206884
6144 48000 2048 135716
4608 48000 1536 74962
8448 48000 2816 250482
3072 48000 1024 33614
kubernetes
M N K Time(usec)
7680 48000 2560 207228
6144 48000 2048 132857
4608 48000 1536 75045
8448 48000 2816 250733
3072 48000 1024 33758
26.
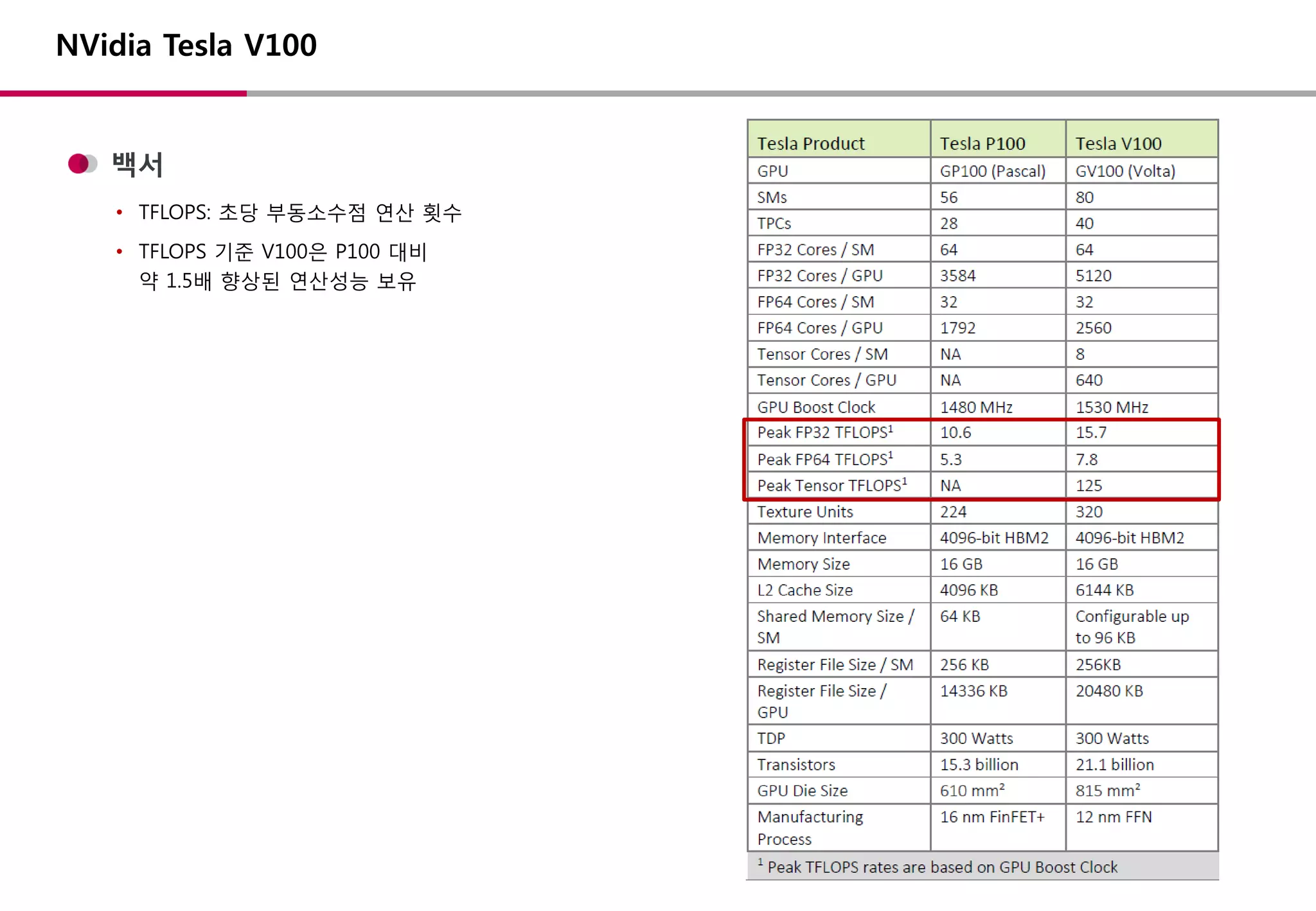
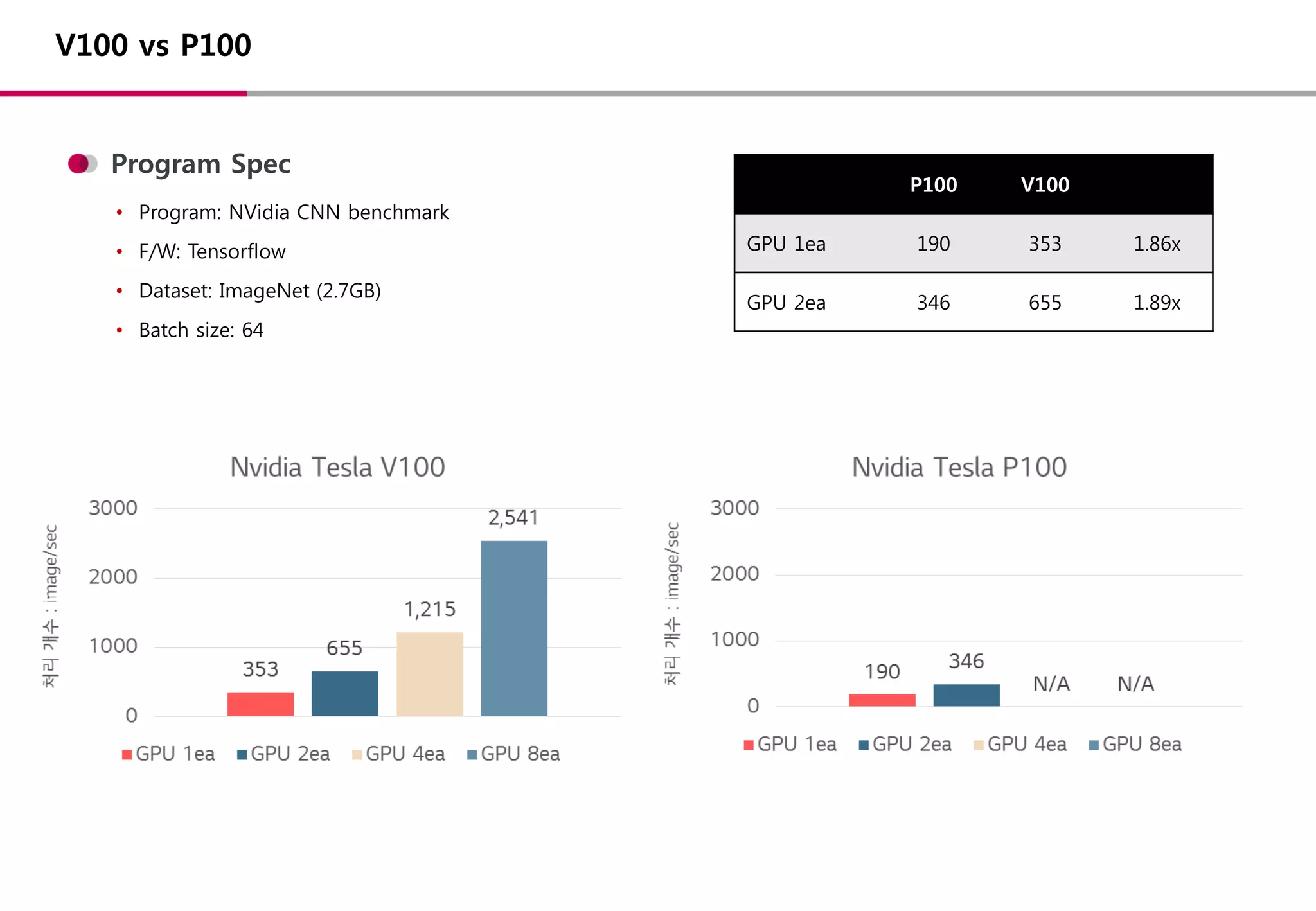
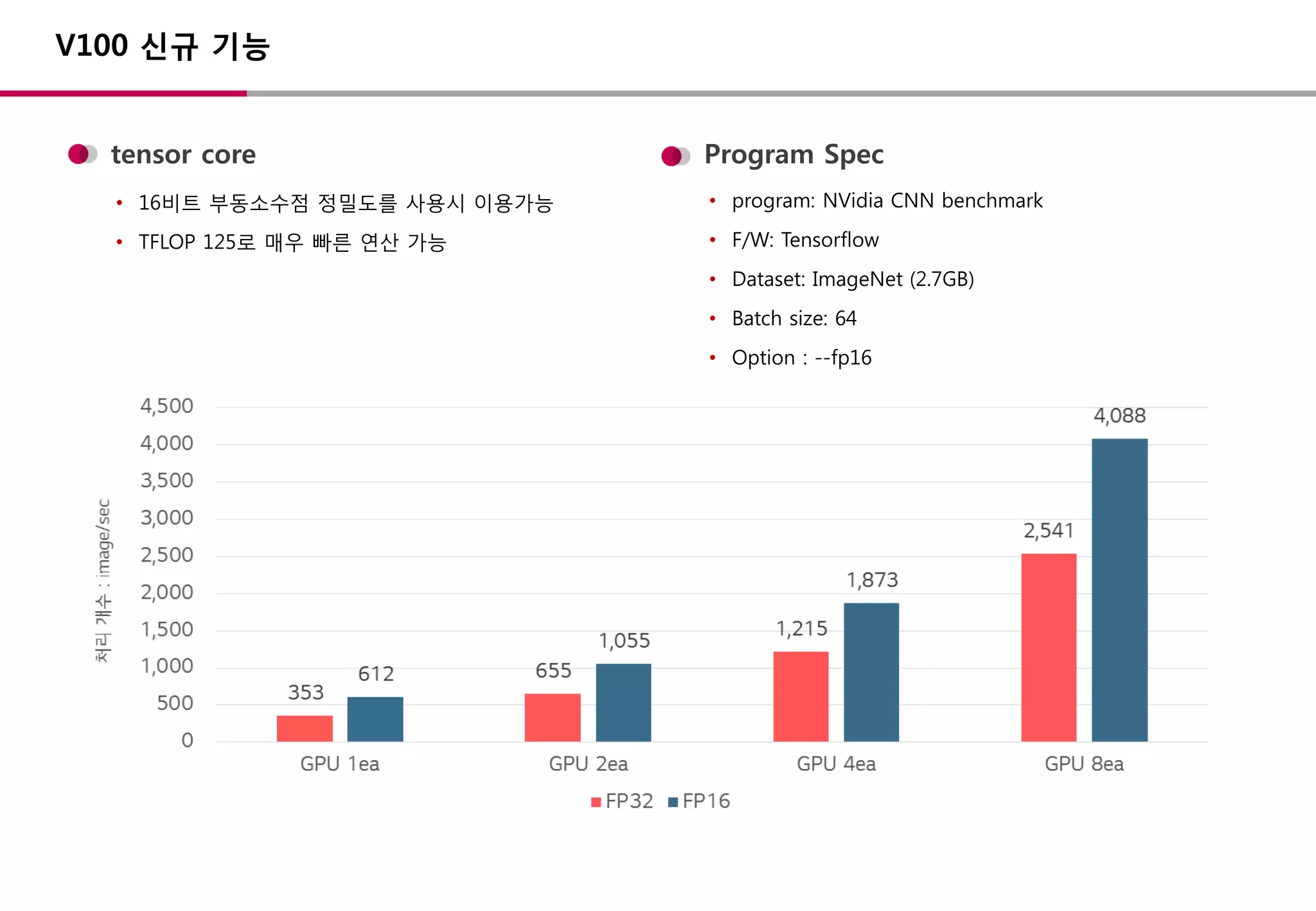
백서
• TFLOPS: 초당부동소수점 연산 횟수
• TFLOPS 기준 V100은 P100 대비
약 1.5배 향상된 연산성능 보유
NVidia Tesla V100





![kubernetes GPU 설치 – v1.9
device plugins 설정
• kubelet : --feature-gates="DevicePlugins=true“
container-runtime 설치
• nvidia driver 설치 (>= v.361.93)
• nvidia-docker 2.0 설치 (docker 버전에 맞춤)
• daemon.json : default runtime 변경
device plugin 설치
• device plugin 설치 (DaemonSet)
• node labeling (accelerator=[value])
출처 : https://kubernetes.io/docs/tasks/manage-gpus/scheduling-gpus/
https://github.com/NVIDIA/k8s-device-plugin](https://image.slidesharecdn.com/e51610gpuonkubernetesv1-180704062436/75/OpenInfra-Days-Korea-2018-Day-2-E5-GPU-on-Kubernetes-15-2048.jpg)

![pod sample
apiVersion: v1
kind: Pod
metadata:
name: cifar10-test
spec:
containers:
- name: cifar10-test
image: myregistrydomain.com:5000/cifar10-test
resources:
limits:
nvidia.com/gpu: 2
command: ["/bin/bash"]
args: ["-c","python cifar10_main.py --data-dir=${PWD}/cifar-10-data --job-dir=/tmp/cifar10 --num-gpus=2
--train-steps=100000"]
nodeSelector:
accelerator: nvidia-tesla-p4
imagePullSecrets:
- name: myregistrydomain
restartPolicy: OnFailure
cifar10-test.yaml](https://image.slidesharecdn.com/e51610gpuonkubernetesv1-180704062436/75/OpenInfra-Days-Korea-2018-Day-2-E5-GPU-on-Kubernetes-17-2048.jpg)




![[OpenInfra Days Korea 2018] (Track 1) Kubernetes 환경에서의 Volume 배포와 데이터 관리의 유연성...](https://cdn.slidesharecdn.com/ss_thumbnails/11netapp-180628162322-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenInfra Days Korea 2018] K8s workshop: with containers & K8s on OpenStack ...](https://cdn.slidesharecdn.com/ss_thumbnails/oidk2018-day2-k8s-180701165541-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenInfra Days Korea 2018] (Track 3) Software Defined Infrastructure 전략 및 사례](https://cdn.slidesharecdn.com/ss_thumbnails/31suse8-180628163035-thumbnail.jpg?width=640&height=640&fit=bounds)

![[OpenInfra Days Korea 2018] (Track 1) From OpenStack to cloud native](https://cdn.slidesharecdn.com/ss_thumbnails/162018openstacktocloudnative-180704054221-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Open-infradays 2019 Korea] jabayo on Kubeflow](https://cdn.slidesharecdn.com/ss_thumbnails/openinfradaysjabayoonkubeflowopen-190719080642-thumbnail.jpg?width=640&height=640&fit=bounds)




![[OpenInfra Days Korea 2018] (Track 4) Provisioning Dedicated Game Server on K...](https://cdn.slidesharecdn.com/ss_thumbnails/43dgs06270307-180628163517-thumbnail.jpg?width=640&height=640&fit=bounds)

![[오픈소스컨설팅] ARM & OpenStack Community](https://cdn.slidesharecdn.com/ss_thumbnails/opensourceconsultingarmopenstackcommunity-210503071541-thumbnail.jpg?width=640&height=640&fit=bounds)




![[OpenInfra Days Korea 2018] (Track 1) TACO (SKT All Container OpenStack): Clo...](https://cdn.slidesharecdn.com/ss_thumbnails/15skttac-180704053421-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenInfra Days Korea 2018] Day 2 - E6 - 마이크로서비스를 위한 Istio & Kubernetes [다운로드...](https://cdn.slidesharecdn.com/ss_thumbnails/e61700microserviceswithistioandkubernetesfinal-180704062831-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenInfra Days Korea 2018] (Track 4) - FreeIPA와 함께 SSO 구성](https://cdn.slidesharecdn.com/ss_thumbnails/45feeipasso-180704060033-thumbnail.jpg?width=640&height=640&fit=bounds)


![[OpenInfra Days Korea 2018] (삼성전자) Evolution to Cloud Native](https://cdn.slidesharecdn.com/ss_thumbnails/1130evolutiontocloudnative2-180704060551-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenInfra Days Korea 2018] K8s workshop: Kubernetes for Beginner](https://cdn.slidesharecdn.com/ss_thumbnails/kubernetesforbegginer20180628v1-180702075619-thumbnail.jpg?width=640&height=640&fit=bounds)


![[OpenInfra Days Korea 2018] (Track 1) IaaS에서 PaaS로의 고도화 여정](https://cdn.slidesharecdn.com/ss_thumbnails/12fromiaastopaas-180628162504-thumbnail.jpg?width=640&height=640&fit=bounds)


![[225]yarn 기반의 deep learning application cluster 구축 김제민](https://cdn.slidesharecdn.com/ss_thumbnails/225yarndeeplearningapplicationcluster-161025031031-thumbnail.jpg?width=640&height=640&fit=bounds)
![[The Future of IT] 3. AI 시대의 인프라_오픈소스를 활용한 인프라 구축 및 GPU as a Service 구현사례_김호진 상무](https://cdn.slidesharecdn.com/ss_thumbnails/thefutureofit3-250220022449-a54710f8-thumbnail.jpg?width=640&height=640&fit=bounds)

![[IBM 김상훈] AI 최적화 플랫폼 IBM AC922 소개와 활용 사례](https://cdn.slidesharecdn.com/ss_thumbnails/1-181029060038-thumbnail.jpg?width=640&height=640&fit=bounds)



![[AWS Innovate 온라인 컨퍼런스] 수백만 사용자 대상 기계 학습 서비스를 위한 확장 비법 - 윤석찬, AWS 테크 에반젤리스트](https://cdn.slidesharecdn.com/ss_thumbnails/awsinnovateonlineconferenceaimltrack1session1channyyun-200319071657-thumbnail.jpg?width=640&height=640&fit=bounds)





![[2017 AWS Startup Day] 스타트업이 인공지능을 만날 때 : 딥러닝 활용사례와 아키텍쳐](https://cdn.slidesharecdn.com/ss_thumbnails/20171102awsstartupday2017-with-171102040932-thumbnail.jpg?width=640&height=640&fit=bounds)




![[OpenInfra Days Korea 2018] Day 2 - E6 - OpenInfra monitoring with Prometheus](https://cdn.slidesharecdn.com/ss_thumbnails/e61520monitoringopeninfrawithprometheusv1-180704062709-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenInfra Days Korea 2018] (Track 3) - CephFS with OpenStack Manila based on...](https://cdn.slidesharecdn.com/ss_thumbnails/36openinfra-2018-naver-cephfs-180704055415-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenInfra Days Korea 2018] Day 2 - E4 - 딥다이브: immutable Kubernetes architecture](https://cdn.slidesharecdn.com/ss_thumbnails/e41530linuxkit-k8s-180704110158-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenInfra Days Korea 2018] Day 1 - T4-7: "Ceph 스토리지, PaaS로 서비스 운영하기"](https://cdn.slidesharecdn.com/ss_thumbnails/47openinfradaykorea2018hyun-ha-180705032301-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenInfra Days Korea 2018] (Track 4) - Grafana를 이용한 OpenStack 클라우드 성능 모니터링](https://cdn.slidesharecdn.com/ss_thumbnails/42openinfraday201820180626grafana-180704055533-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018.10.19] 김용기 부장 - IAC on OpenStack (feat. ansible)](https://cdn.slidesharecdn.com/ss_thumbnails/iaconopenstackansible-20181019-ykim-181022130142-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenInfra Days Korea 2018] Day 2 - E5: Mesos to Kubernetes, Cloud Native 서비스...](https://cdn.slidesharecdn.com/ss_thumbnails/e60930openinfraday2018dennis-180705030830-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenInfra Days Korea 2018] Day 2 - CEPH 운영자를 위한 Object Storage Performance T...](https://cdn.slidesharecdn.com/ss_thumbnails/openinfradayobjectstorageperformancefinal2-180704062033-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenInfra Days Korea 2018] (Track 3) - OpenStack Automation with Ansible](https://cdn.slidesharecdn.com/ss_thumbnails/35redhatopenstackautomationwithansible-180704055300-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenInfra Days Korea 2018] Day 2 - E6: "SONA: ONOS SDN Controller 기반 OpenSta...](https://cdn.slidesharecdn.com/ss_thumbnails/e61610sonaonossdncontroller-180705044922-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenInfra Days Korea 2018] Day 2 - E3-2: "핸즈온 워크샵: Kubespray, Helm, Armada를 ...](https://cdn.slidesharecdn.com/ss_thumbnails/e31530kubesprayhelmarmada-180705044520-thumbnail.jpg?width=640&height=640&fit=bounds)

![[OpenInfra Days Korea 2018] Day 2 - E1: 딥다이브 - OpenStack 생존기](https://cdn.slidesharecdn.com/ss_thumbnails/e11300openinfradaysizingv1-180705030216-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenInfra Days Korea 2018] (Track 4) - 오픈스택기반 NFV 관리 및 HA (high Availability...](https://cdn.slidesharecdn.com/ss_thumbnails/46openstack-based-nfv-mgmt-and-ha-180704060219-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenInfra Days Korea 2018] Day 2 - E5-1: "Invited Talk: Kubicorn - Building ...](https://cdn.slidesharecdn.com/ss_thumbnails/e60955buildingsimplekubernetes-180705043459-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenInfra Days Korea 2018] Day 2 - E4 - 핸즈온 워크샵: 서버리스가 컨테이너를 만났을 때](https://cdn.slidesharecdn.com/ss_thumbnails/e41300when-180704061740-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenInfra Days Korea 2018] (Track 3) - SDN/NFV enabled Openstack Platform : ...](https://cdn.slidesharecdn.com/ss_thumbnails/34attoresearchsdnnfvenabledopenstackplatformatomstack2018-180704055110-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018.10.19] Andrew Kong - Tunnel without tunnel (Seminar at OpenStack Korea ...](https://cdn.slidesharecdn.com/ss_thumbnails/tunnelwithouttunnel-181022130534-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenInfra Days Korea 2018] (NetApp) Open Source with NetApp - 전국섭 상무](https://cdn.slidesharecdn.com/ss_thumbnails/1100180628openinfradaynetappkeynotesfinal-180704060407-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenInfra Days Korea 2018] (Track 4) - Backend.AI: 오픈소스 머신러닝 인프라 프레임워크](https://cdn.slidesharecdn.com/ss_thumbnails/4420180628backend-180704055900-thumbnail.jpg?width=640&height=640&fit=bounds)