Download to read offline


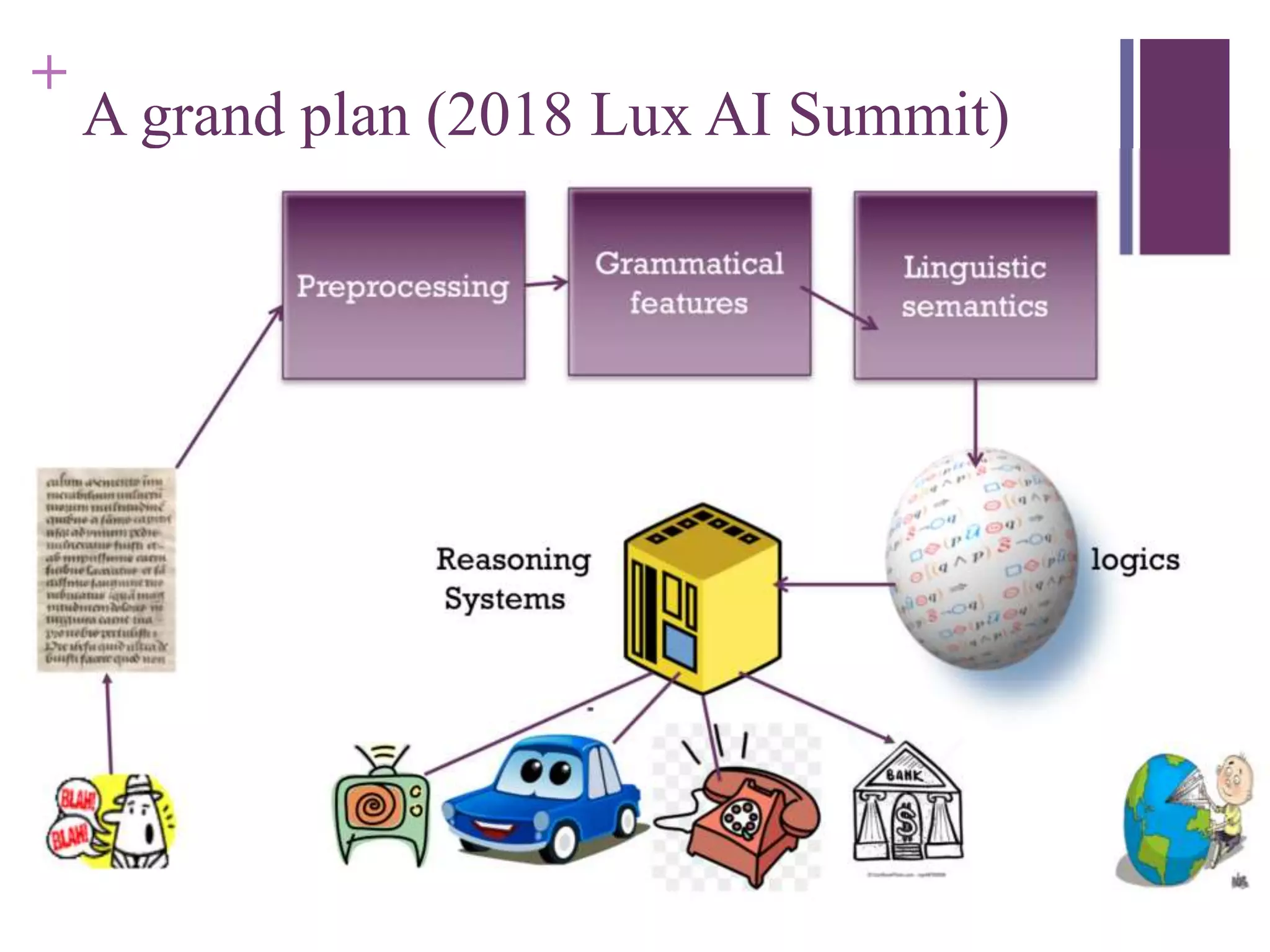






Valeria de Paiva discusses the need for knowledge resources like ontologies for the Portuguese language. While Portuguese is the 6th most spoken language, existing lexical and semantic resources are insufficient for natural language understanding in Portuguese. The OpenWordnet-PT project has created a Portuguese wordnet that is used in applications like Google Translate but requires further improvement. Other relevant resources for Portuguese include the UD corpus and SICK-BR corpus. Machine learning presents both opportunities if knowledge can be incorporated explainably, as well as challenges if it is seen as a "black box" solution.














































































