Download to read offline








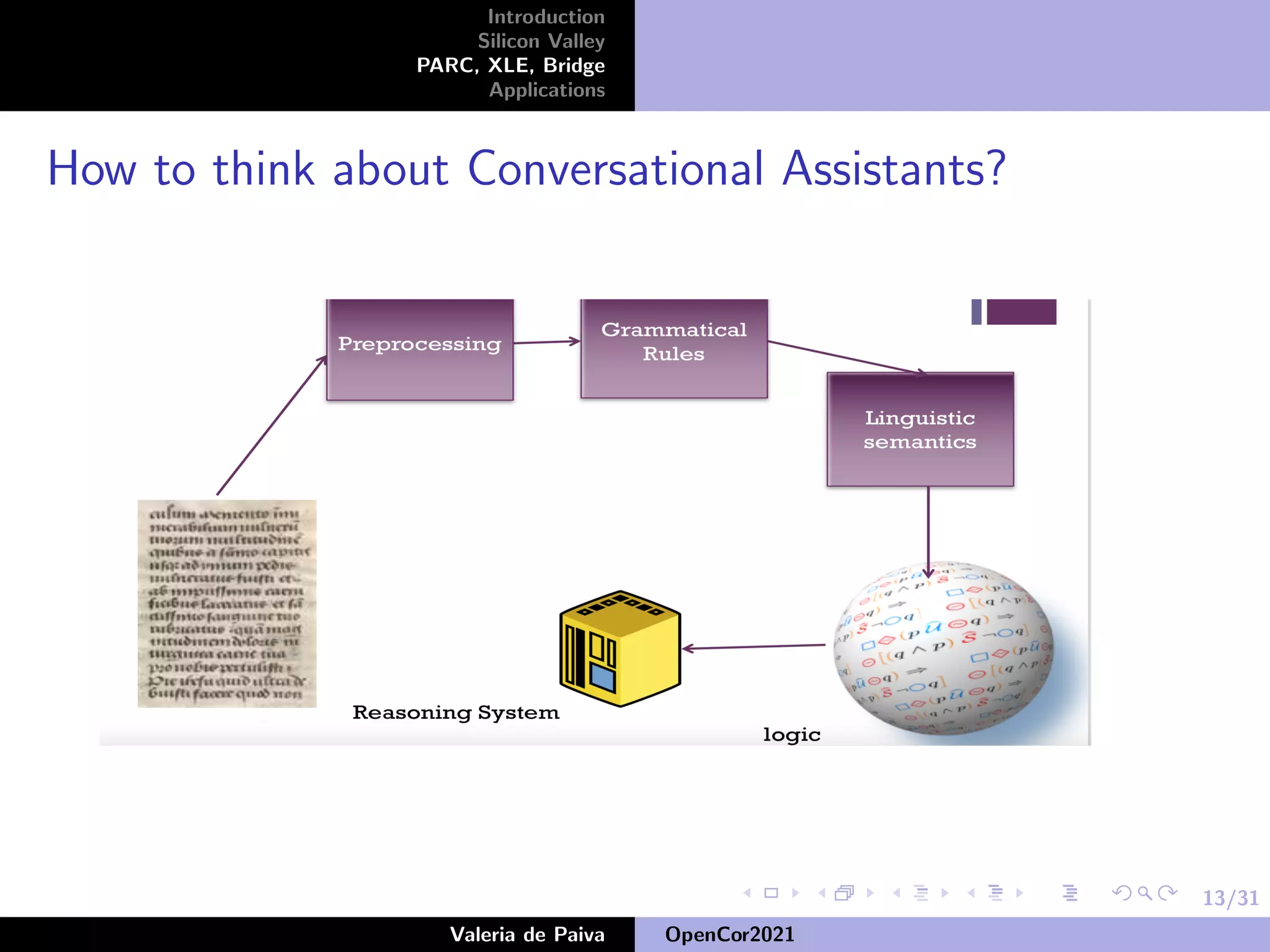
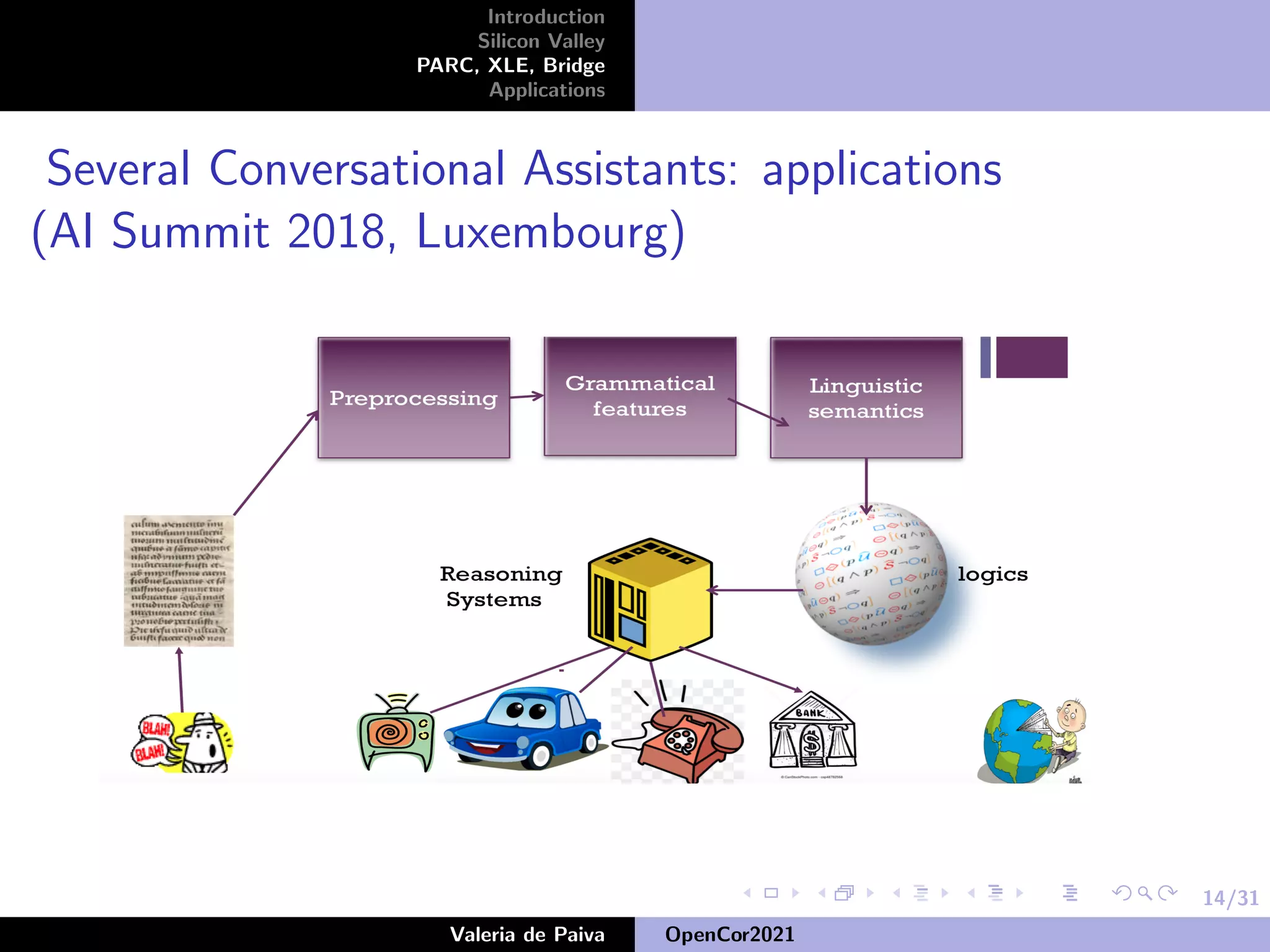
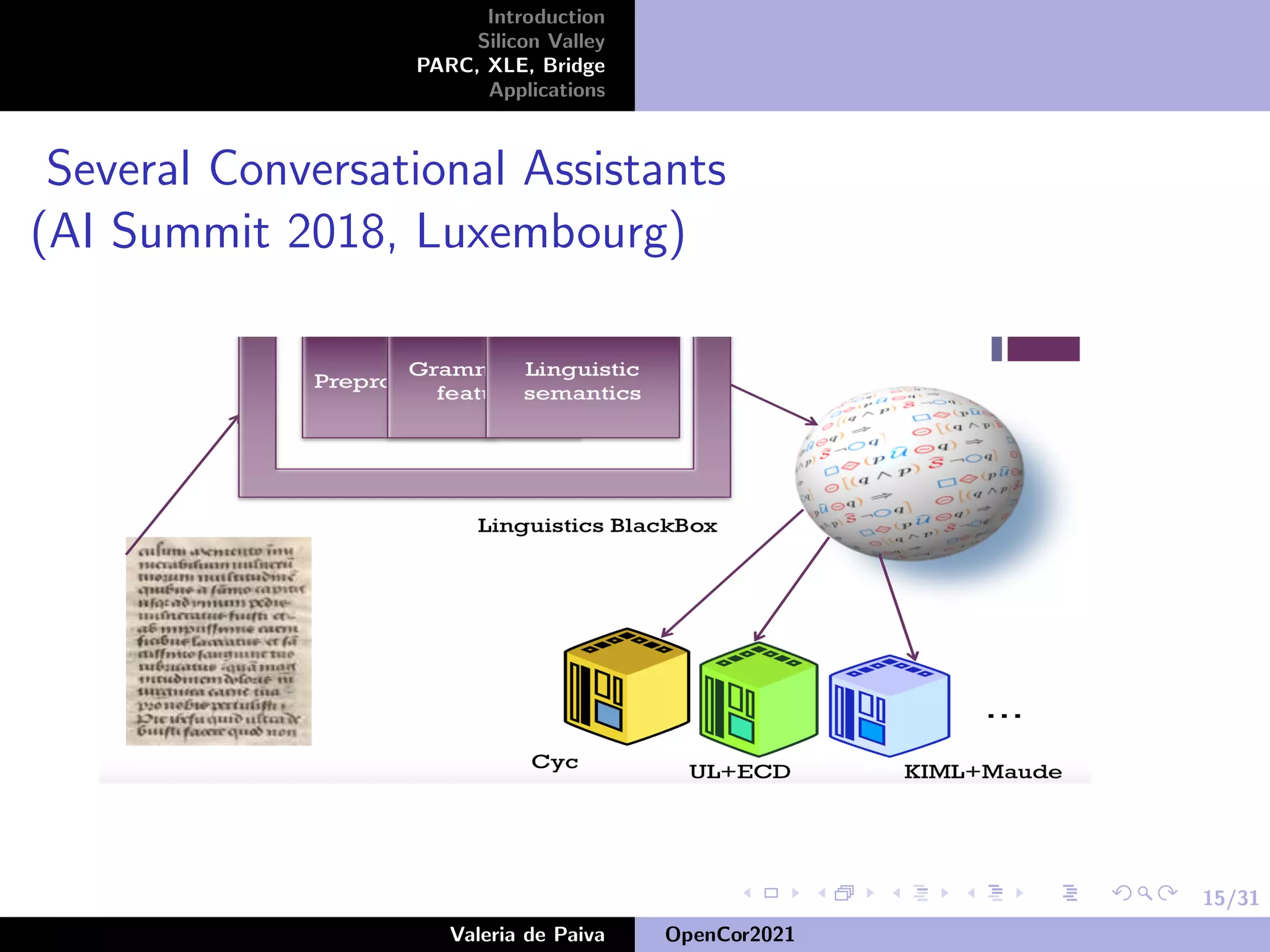


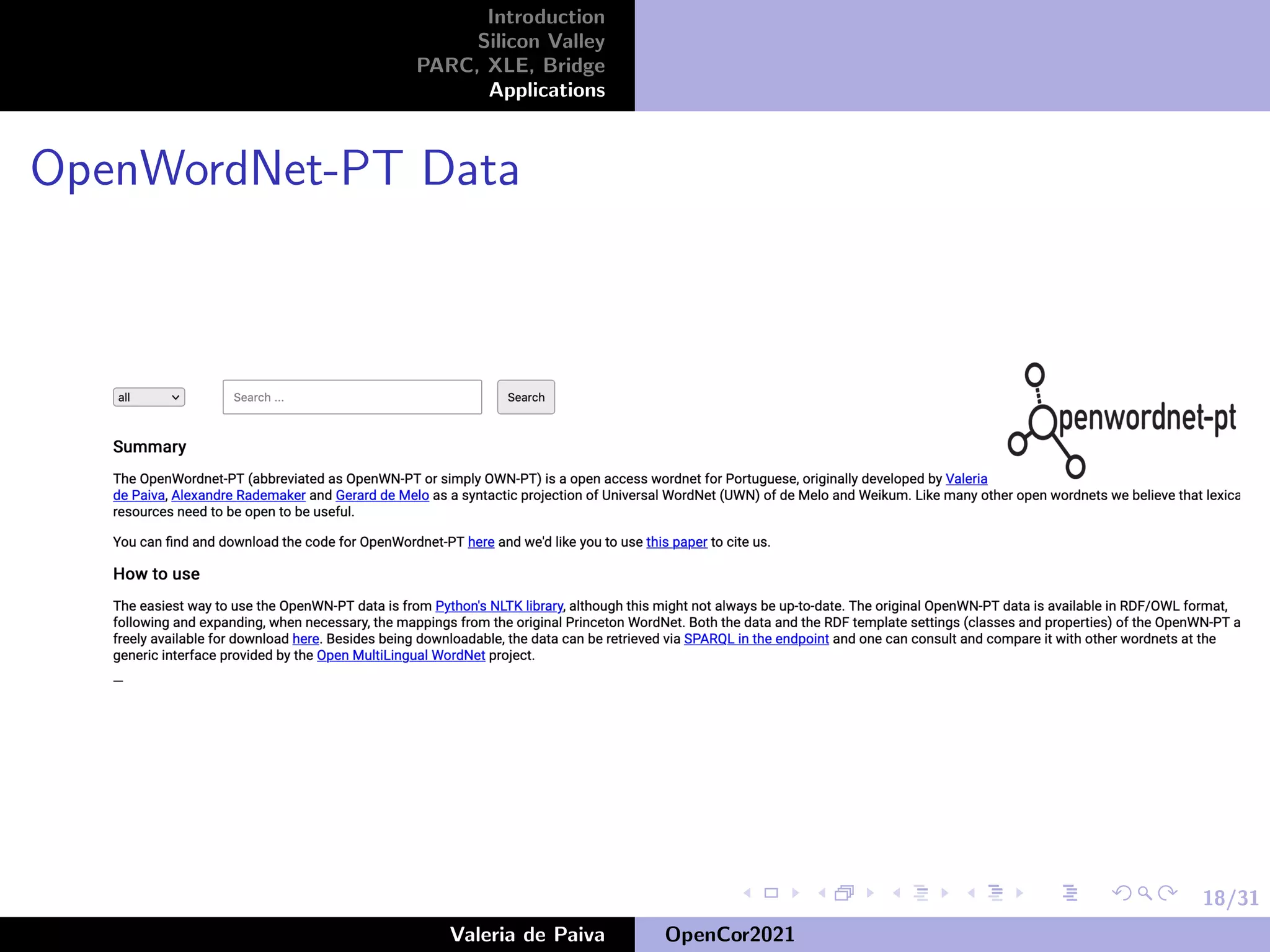



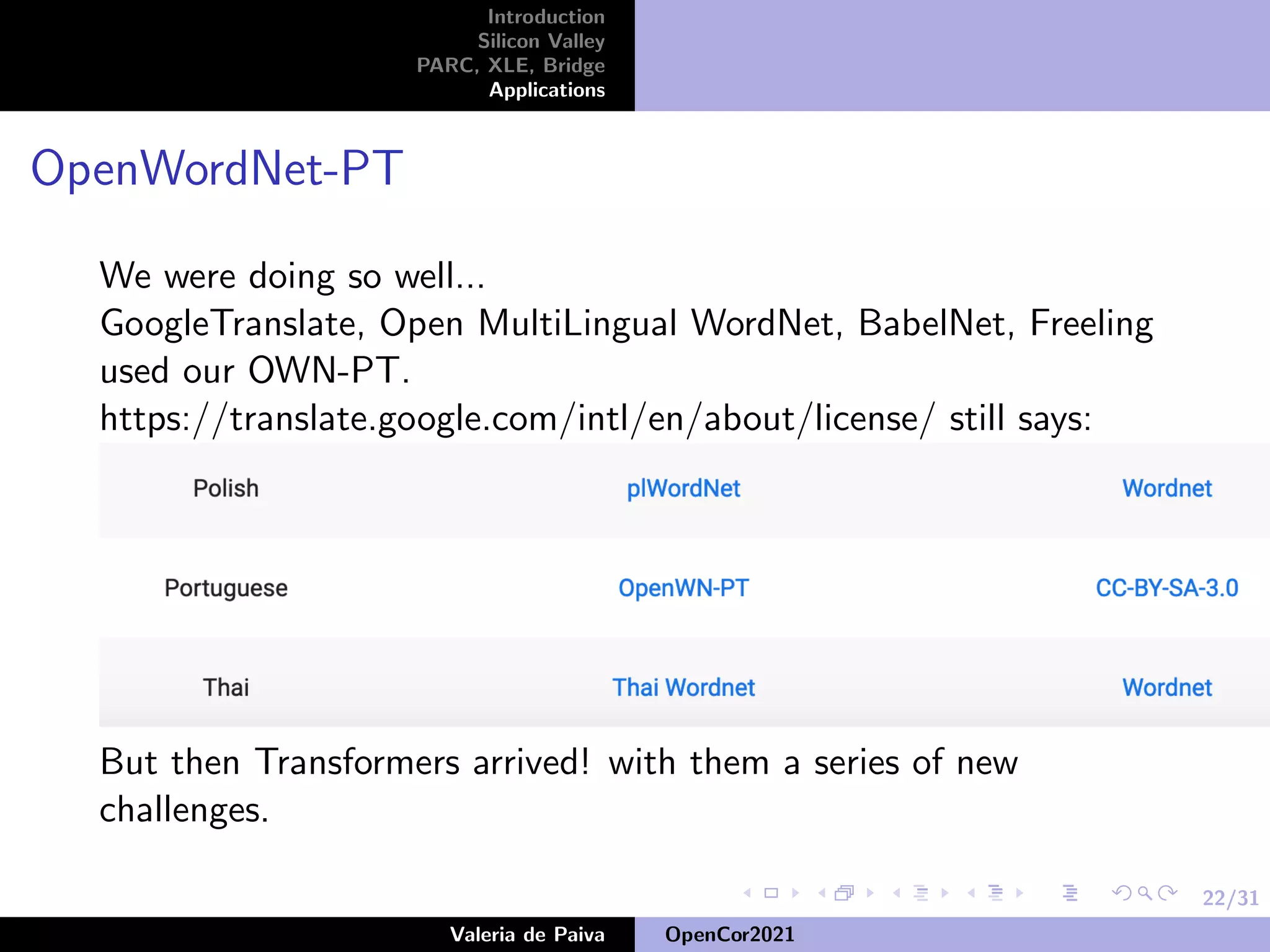









The document discusses the speaker's career in Silicon Valley applying mathematics to computing. It describes various roles at companies like Samsung Research America, Nuance Communications, and PARC where the speaker worked on projects involving knowledge representation, conversational assistants, and developing open source resources like OpenWordNet-PT for Portuguese. The speaker emphasizes the importance of open source datasets for languages beyond English and ongoing work to improve resources like UD-PT and SICK-BR.












































































