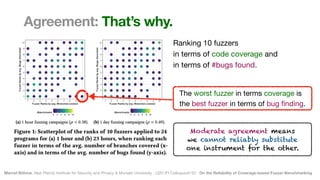
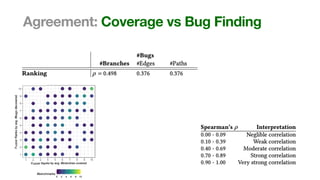
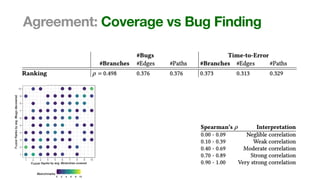
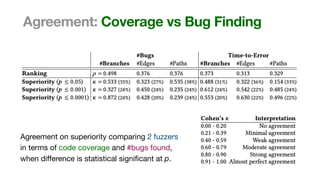
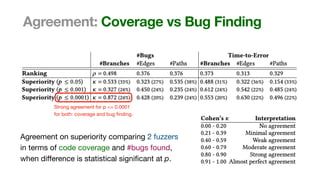
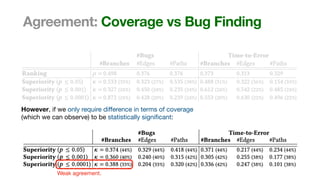
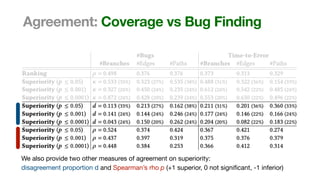
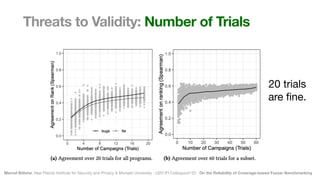
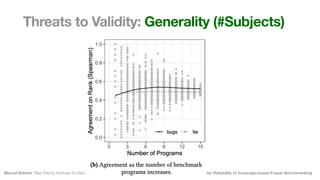
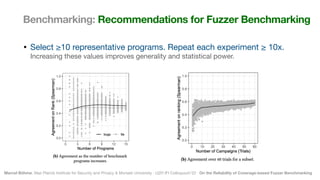
The document discusses the reliability of coverage-based fuzzer benchmarking, emphasizing the correlation between code coverage and bug finding effectiveness. It highlights that while higher code coverage typically leads to more bugs being found, this relationship can be overshadowed by the size of test suites. The study also explores issues of comparability between different fuzzers and the potential limitations of existing methodologies in accurately assessing fuzzer performance.





















































![Marcel Böhme, Max Planck Institute for Security and Privacy & Monash University · UZH IFI Colloquium’22 · On the Reliability of Coverage-based Fuzzer Benchmarking
Benchmarking: Challenges of Bug-Based Benchmarking
• Ground-truth-based evaluation
• Curate real bugs in a random, representative sample of programs.
• Economical, realistic bugs, objective ground truth.
• Problem: Many potential sources of bias.
• Post hoc bug based evaluation
• Maximize bug probability in a random, representative sample of programs.
• Identify and deduplicate bugs *after* the fuzzing campaign. Minimizes bias.
• Problem: Less economical (we did not
fi
nd bugs in 7/24 [30%] programs).](https://image.slidesharecdn.com/icse22-220512201358-aaf1a1ff/85/On-the-Reliability-of-Coverage-based-Fuzzer-Benchmarking-63-320.jpg)










































![[Keynote @ RAID'24] How to solve cybersecurity once and for all](https://cdn.slidesharecdn.com/ss_thumbnails/raidkeynote-241203090620-f08548a5-thumbnail.jpg?width=640&height=640&fit=bounds)
















![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)









