Downloaded 22 times





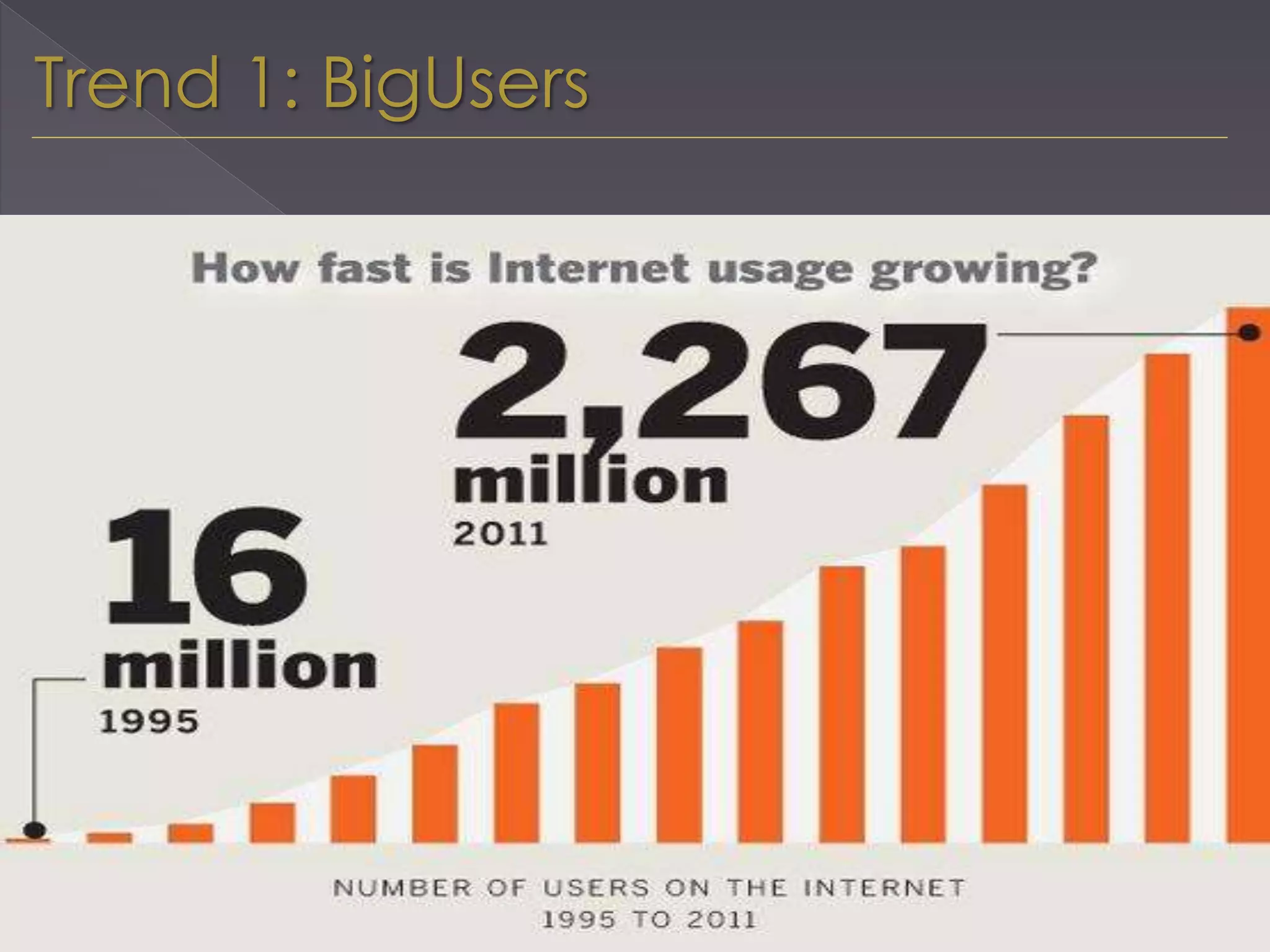
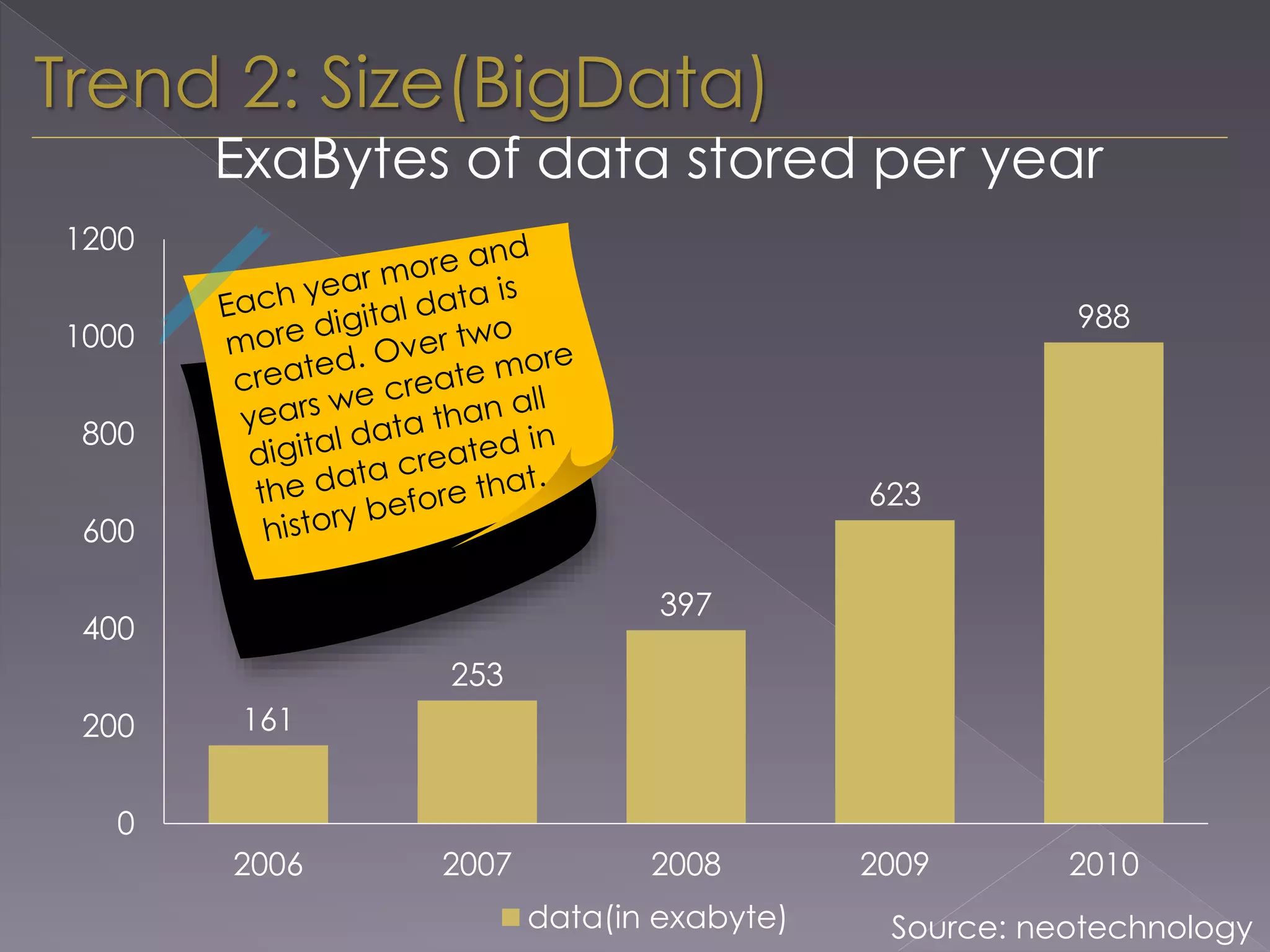
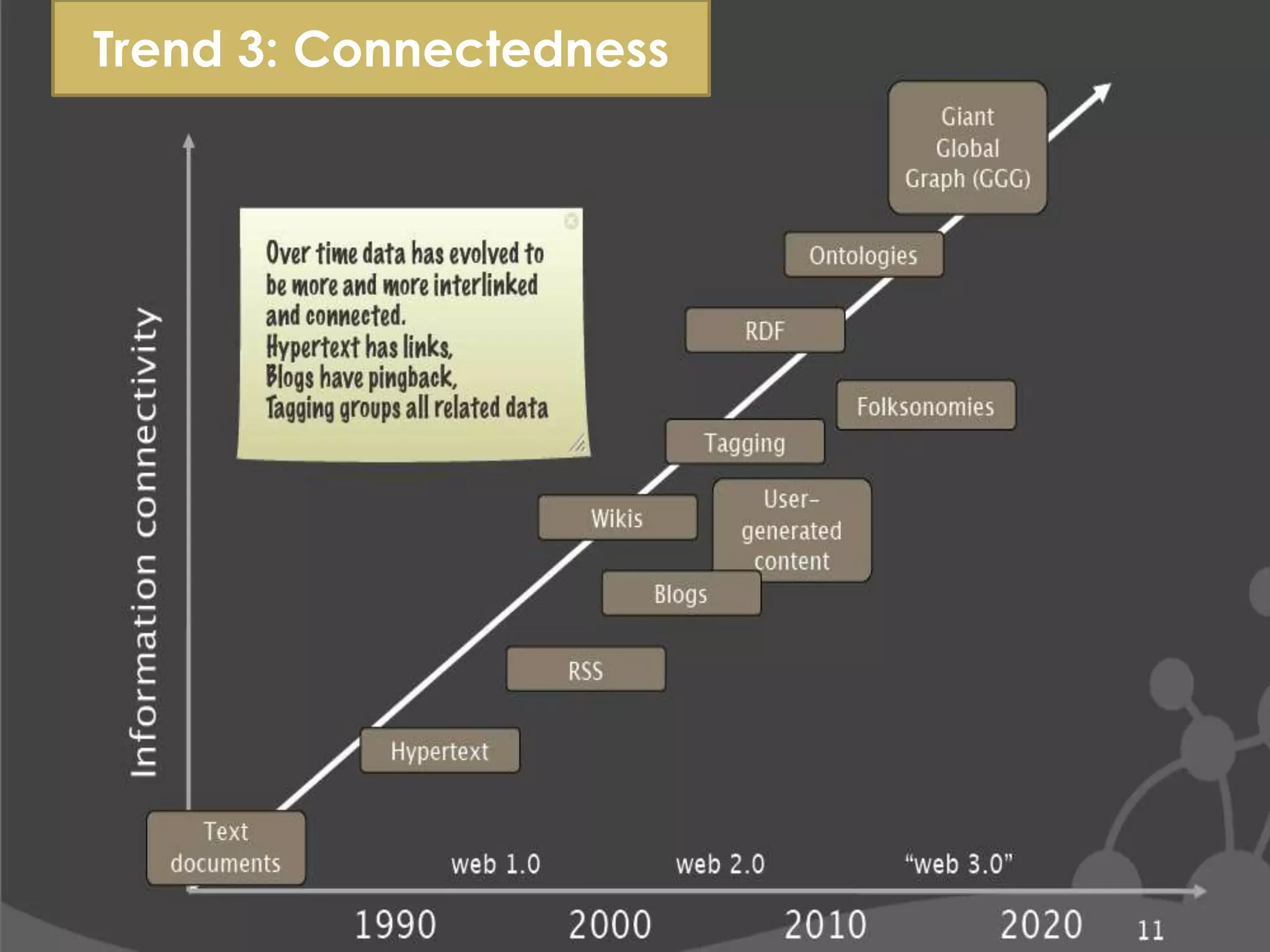

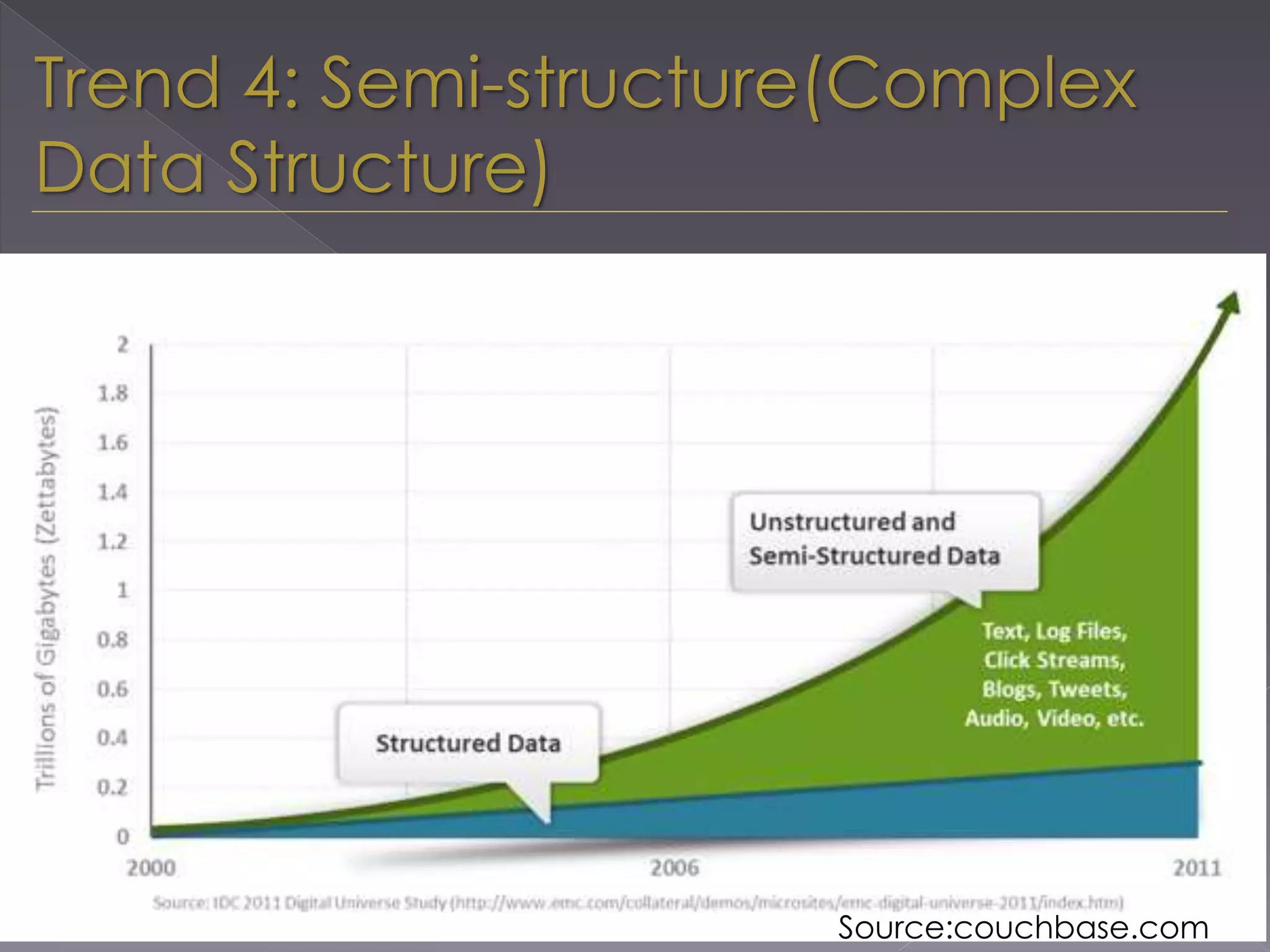
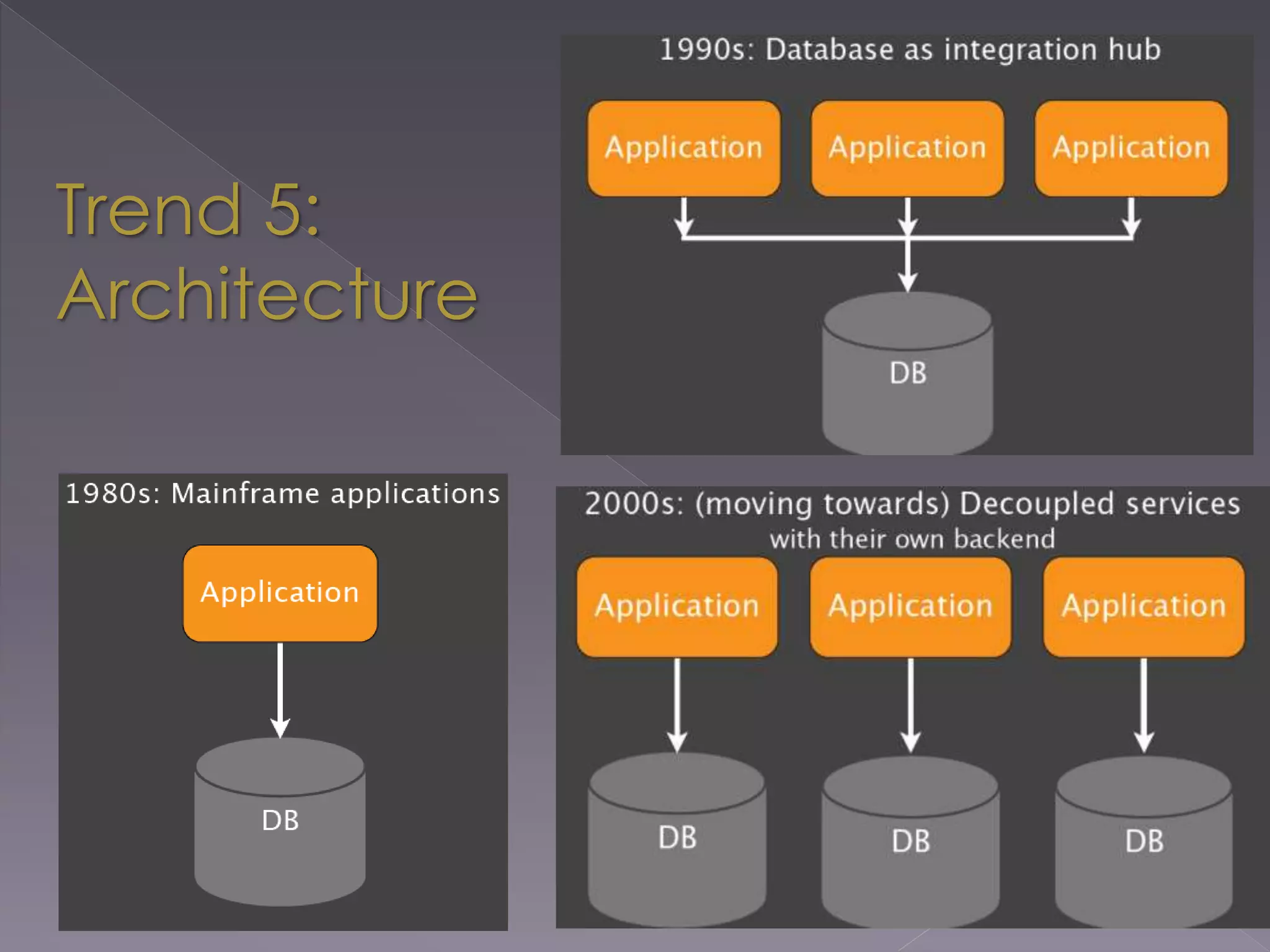


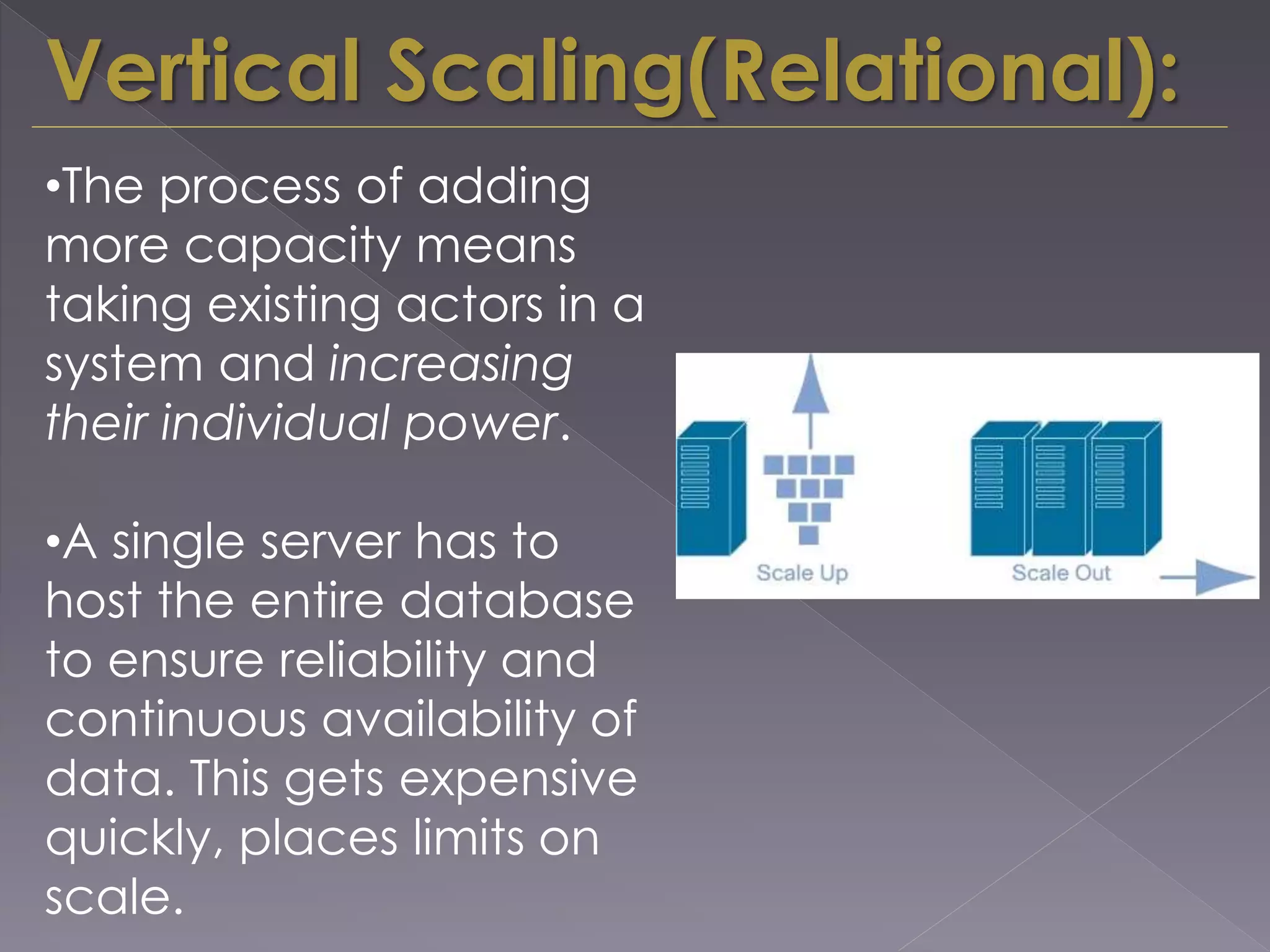















The document discusses the evolution from relational databases to NoSQL in response to challenges posed by big data, increased user demands, and the need for flexible data structures. It highlights key trends such as big data size, connectedness, semi-structured data, and the advantages of NoSQL, including horizontal scaling, dynamic schemas, sharding, replication, and integrated caching. These features support more agile development and continuous operation of applications while efficiently managing large volumes of data.
















































































