Download to read offline


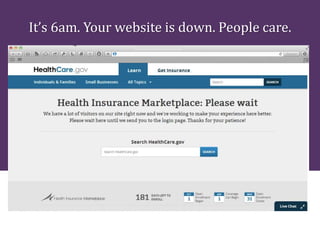







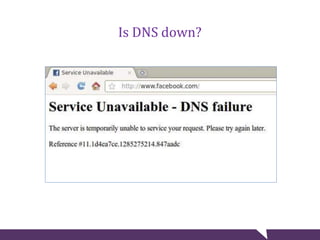



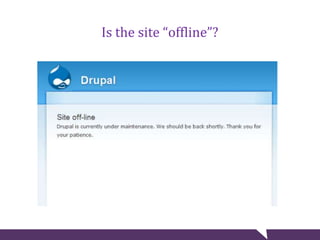






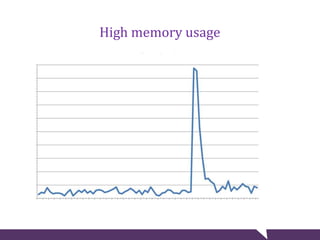

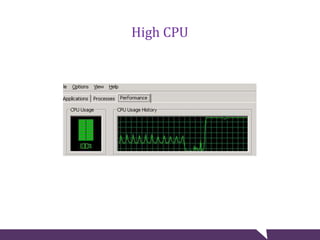



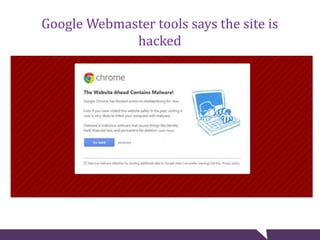

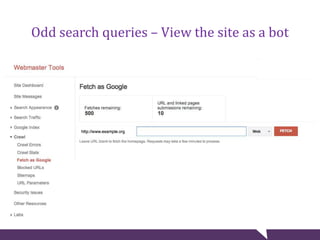





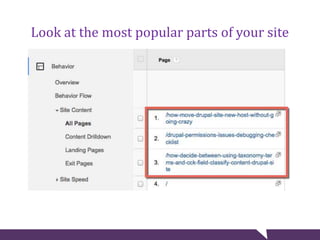

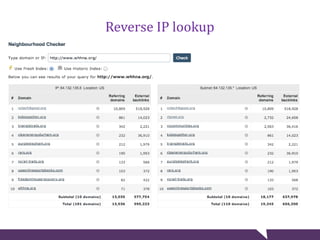




The document provides tips for troubleshooting website problems when a site goes down. It recommends checking for obvious causes like outages at the server, ISP, or DNS level. It also suggests using tools to check for server issues like high memory usage, full disk space, or outdated security patches. Finally, it advises interviewing staff, website visitors, and other sites sharing the same IP address to uncover any recent changes or unusual traffic that may have contributed to the problem. The overall goal is to find clues that help diagnose and avert a full-blown website crisis.




































