Download as PDF, PPTX











![Copyright © 2019, Oracle and/or its affiliates. All rights reserved.
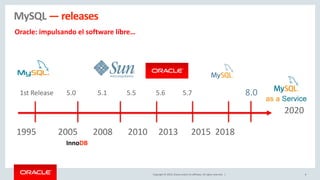
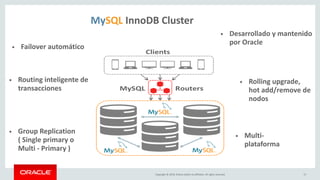
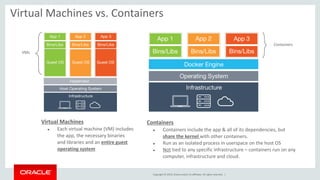
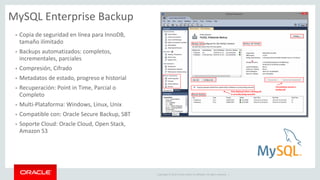
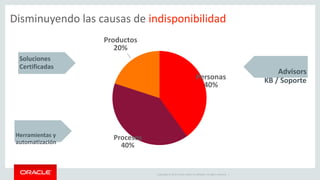
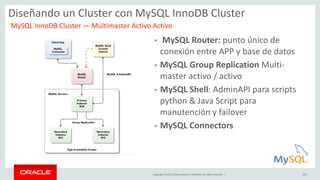
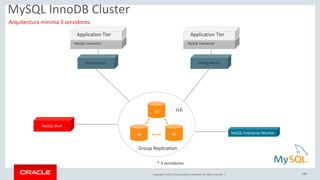
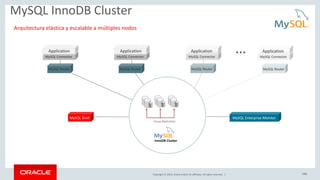
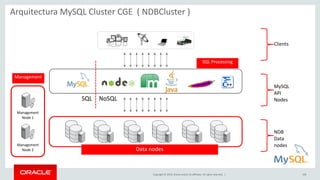
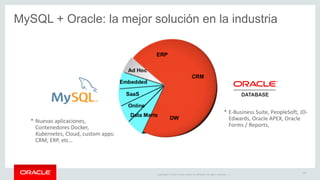
Relational Model vs Document Store Model
Relational Model
20
id name email city_id
3412 John Smith john@oracle.com 45
id city country_id
45 San Francisco US
customer
city
id id_customer date total
381 3412 2017-08-24 312.20
412 3412 2017-10-02 24.95
shop_order
Relational Model
id name email city_id
3412 John Smith john@oracle.com 45
id city country_id
45 San Francisco US
customer
city
id id_customer date total
381 3412 2017-08-24 312.20
412 3412 2017-10-02 24.95
shop_order
JSON Document Model
{
_id: 3412,
name: "John Smith",
email: john@oracle.com,
city: "San Francisco",
country: "US",
orders: [
{date: "2017-08-24", total: 312.20},
{date: "2017-10-02", total: 24.95}
]
}](https://image.slidesharecdn.com/mysql8-200429180210/85/MySQL-8-0-Introduction-to-NoSQL-SQL-20-320.jpg)



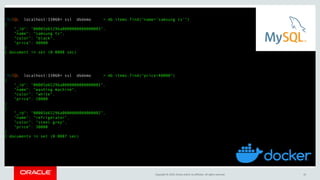
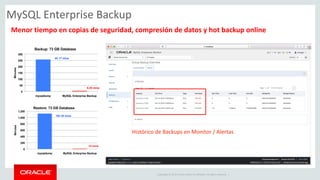
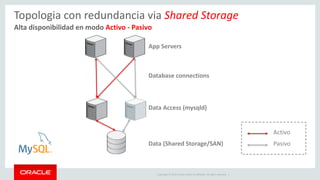
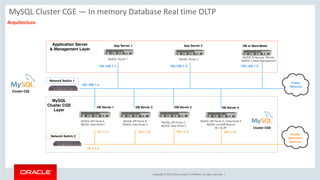
![Copyright © 2019, Oracle and/or its affiliates. All rights reserved. 25
Example : Modify JSON document
# create a schema to store the collection
db.items.modify("name = 'samsung tv'").set("price", 15000)
# view the newly modified items
db.items_table.find("name='samsung tv'")
[
{
"_id": "00005b6eba8e0000000000000003", "color": "black",
"name": "samsung tv",
"price": 15000
} ]](https://image.slidesharecdn.com/mysql8-200429180210/85/MySQL-8-0-Introduction-to-NoSQL-SQL-25-320.jpg)
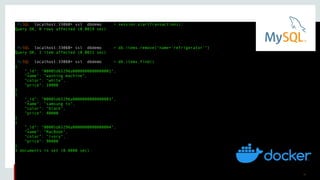
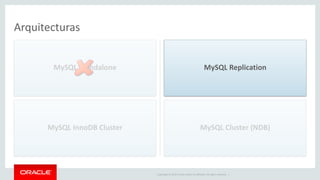
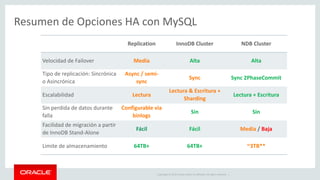
![Copyright © 2019, Oracle and/or its affiliates. All rights reserved. 27
Example : Delete JSON document
# delete document
db.items_table.remove("name='washing machine'")
# view document after deletion
db.items_table.find()
[{ } ] }, {
"_id": "00005b6eba8e0000000000000002", "color": "steel grey",
"name": "refrigerator",
"price": 30000
"_id": "00005b6eba8e0000000000000003", "color": "black",
"name": "samsung tv",
"price":](https://image.slidesharecdn.com/mysql8-200429180210/85/MySQL-8-0-Introduction-to-NoSQL-SQL-27-320.jpg)
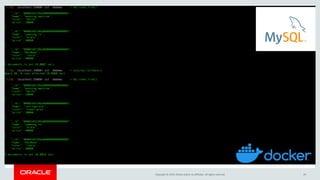
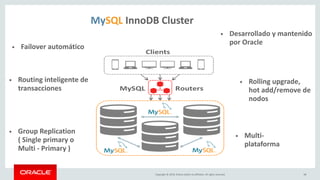
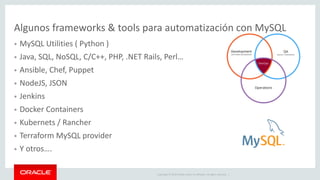
![Copyright © 2019, Oracle and/or its affiliates. All rights reserved. 28
Example : Read JSON document
# Search and list documents satisfying a condition
db.items_table.find("price>25000") [
{
"_id": "00005b6eba8e0000000000000002", "color": "steel grey",
"name": "refrigerator",
"price": 30000
}, {
} ]
"_id": "00005b6eba8e0000000000000004", "color": "ivory",
"name": "MacBook",
"price](https://image.slidesharecdn.com/mysql8-200429180210/85/MySQL-8-0-Introduction-to-NoSQL-SQL-28-320.jpg)


![Copyright © 2019 Oracle and/or its affiliates. All rights reserved.
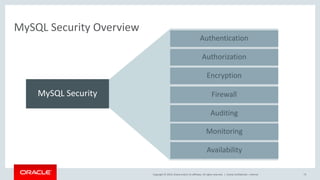
Docker — Innovating
• Docker is a set of platform-as-a-service (PaaS) products that use operating-
system-level virtualization to deliver software in packages called containers.
[5]
• Docker can package an application and its dependencies in a virtual
container that can run on any Linux server.
• All containers are run by a single operating-system kernel and are thus
more lightweight than virtual machines.[7]
• Other container runtime environments including CoreOS rkt, Mesos, lxc
https://en.wikipedia.org/wiki/Docker_(software)](https://image.slidesharecdn.com/mysql8-200429180210/85/MySQL-8-0-Introduction-to-NoSQL-SQL-32-320.jpg)

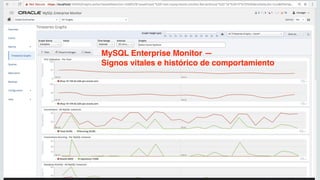
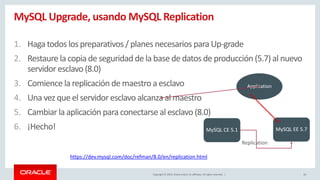
![Copyright © 2019, Oracle and/or its affiliates. All rights reserved.
1. Download the Image ( Enterprise or Community )
manuel$ docker load -i mysql-enterprise-server-8.0.17.tar
b87942114db6: Loading layer [==================================================>] 124.2MB/124.2MB
a1dffbe20d07: Loading layer [==================================================>] 223.7MB/223.7MB
581e09cb3fe0: Loading layer [==================================================>] 8.704kB/8.704kB
09fda90e0255: Loading layer [==================================================>] 2.048kB/2.048kB
Loaded image: mysql/enterprise-server:8.0
Nota: MySQL Enterprise Docker Images available in support.oracle.com
2. List Docker Images
manuel$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
mysql/enterprise-server 8.0 43aee7bd77e7 2 months ago 341MB
3. Run Docker Container
manuel$ docker run --name=mysql -d mysql/enterprise-server:8.0
9d14c41411281691cbe1902a4f657fe90f7964b117c2b48600ef6dcd7272bf04
4. docker ps
manuel$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS
NAMES
9d14c4141128 mysql/enterprise-server:8.0 "/entrypoint.sh mysq…" About a minute ago Up About a minute (healthy) 3306/tcp, 33060/tcp
mysql
39
MySQL on Docker Containers](https://image.slidesharecdn.com/mysql8-200429180210/85/MySQL-8-0-Introduction-to-NoSQL-SQL-39-320.jpg)
![Copyright © 2019, Oracle and/or its affiliates. All rights reserved.
5. Reading Docker mysql LOG error ( root password )
manuel$ docker logs mysql |more
[Entrypoint] No password option specified for new database.
[Entrypoint] A random onetime password will be generated.
2019-08-27T13:00:11.417971Z 0 [System] [MY-013169] [Server] /usr/sbin/mysqld (mysqld 8.0.17-commercial) initializing of
server in progress as process 20
2019-08-27T13:00:27.078318Z 0 [System] [MY-010931] [Server] /usr/sbin/mysqld: ready for connections. Version: '8.0.17-
commercial' socket: '/var/lib/mysql/mysql.sock' port: 3306 MySQL Enterprise Server - Commercial.
2019-08-27T13:00:27.194504Z 0 [System] [MY-011323] [Server] X Plugin ready for connections. Socket: '/var/run/mysqld/
mysqlx.sock' bind-address: '::' port: 33060
[Entrypoint] MySQL Docker Image 8.0.17-1.1.12
[Entrypoint] Initializing database
[Entrypoint] Database initialized
[Entrypoint] GENERATED ROOT PASSWORD: xEkUz#oszedH0cyJ1uDog8EMiP]
[Entrypoint] ignoring /docker-entrypoint-initdb.d/*
[Entrypoint] Server shut down
[Entrypoint] Setting root user as expired. Password will need to be changed before database can be used.
[Entrypoint] MySQL init process done. Ready for start up.
[Entrypoint] Starting MySQL 8.0.17-1.1.12
40
MySQL on Docker Containers
<— MySQL Root password](https://image.slidesharecdn.com/mysql8-200429180210/85/MySQL-8-0-Introduction-to-NoSQL-SQL-40-320.jpg)



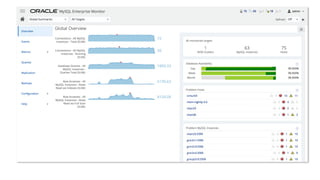
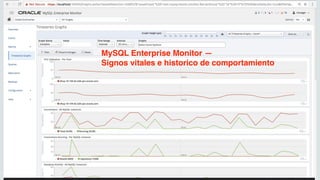
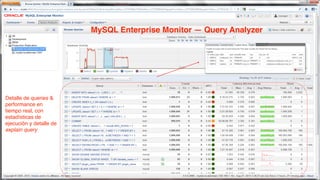
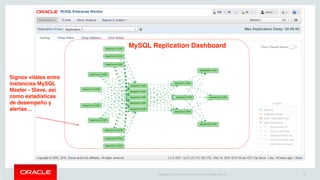






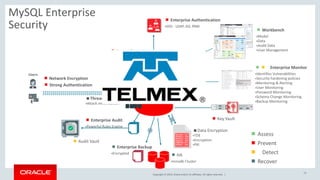

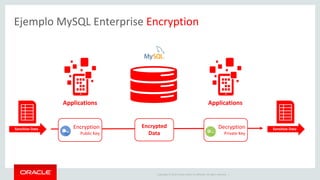
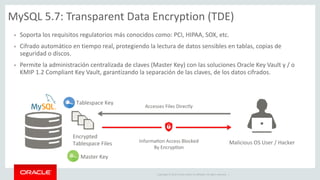











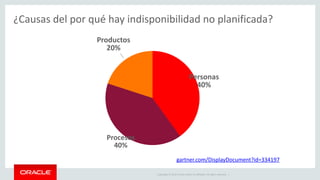


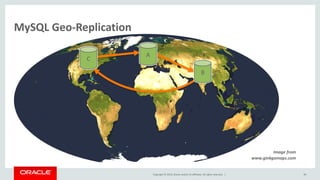
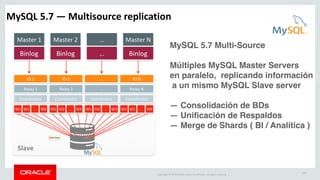
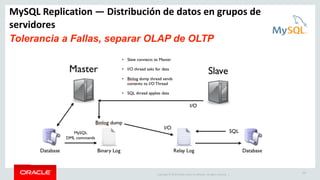















The document outlines Oracle's MySQL features and advancements, particularly focusing on the capabilities of MySQL 8.0, including support for JSON data types, enhanced performance, and improved security. It also discusses multi-source replication, high availability, and the integration of SQL and NoSQL functionalities. Additionally, the document describes Docker's use for deploying MySQL containers and managing databases efficiently.


















































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)














