Download to read offline









![redpencil.io
In 60 seconds
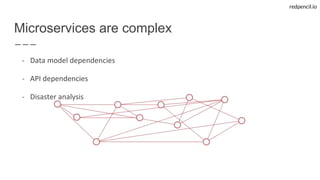
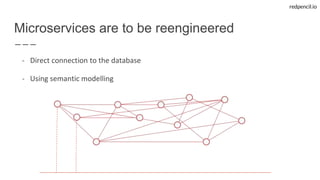
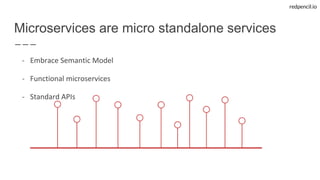
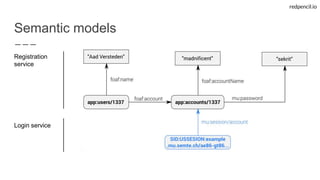
State-of-the-art web applications fuelled by Linked Data aware microservices
- User-facing microservices
- Easy deployment using Docker
- Single Page Apps using Ember.js
- Well known requirements
=> [HTTP+JSON+SPARQL]
https://github.com/mu-semtech/
https://mu.semte.ch](https://image.slidesharecdn.com/1200-1230sallehocaillemu-180313134751/85/mu-semte-ch-A-transitional-architecture-for-Linked-Data-12-320.jpg)










![redpencil.io
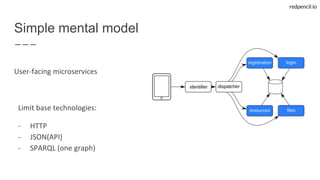
Base templates
CatalogsIndexRoute = Ember.Route.extend
ajax: Ember.inject.service()
model: () ->
@get('ajax').request('/hello')
Hello result: {{model.value}}
get '/hello/' do
counter = query( "SELECT COUNT (*) as ?counter" +
"WHERE {" +
" ?s ?p ?o." +
"}" ).first[:counter].to_i
status 200
{ value: counter }.to_json
end
FROM semtech/mu-ruby-template:2.0.0-ruby2.3
MAINTAINER Your Name <you@provider.com>
demo:
image: you/demo-service
links:
- db:database
dispatcher:
…
links:
- demo:demo
match "/hello/*path" do
Proxy.forward conn, path, "http://demo/hello/"
end
[mu-ruby-template]](https://image.slidesharecdn.com/1200-1230sallehocaillemu-180313134751/85/mu-semte-ch-A-transitional-architecture-for-Linked-Data-25-320.jpg)
![redpencil.io
Configurable services
(define-resource agendapunt ()
:class (s-prefix "besluit:Agendapunt")
:properties `((:titel :string ,(s-prefix "dct:title"))
(:beschrijving :string ,(s-prefix "dct:description"))
(:openbaar :boolean ,(s-prefix
"besluit:geplandOpenbaar"))
:has-many `((agendapunt :via ,(s-prefix "dct:references")
:as "referenties"))
:has-one `((agendapunt :via ,(s-prefix "besluit:aangebrachtNa")
:as "vorige-agendapunt")
(agenda :via ,(s-prefix "besluit:heeftAgendapunt")
:inverse t
:as "agenda"))
:resource-base (s-url "https://data.lblod.info/id/agendapunten/")
:on-path "agendapunten")
[mu-cl-resources]
Full JSONAPI from abstract description](https://image.slidesharecdn.com/1200-1230sallehocaillemu-180313134751/85/mu-semte-ch-A-transitional-architecture-for-Linked-Data-26-320.jpg)











The document outlines a transitional architecture for linked data by RedPencil.io, emphasizing the use of microservices and semantic modeling to create efficient, maintainable, and adaptable business solutions. It highlights the advantages of using Docker for easy deployment and the importance of a simple mental model in service development. Additionally, it discusses the future potential for reactive programming and performance improvements within microservice architectures.


















![Hybrid Cloud, Kubeflow and Tensorflow Extended [TFX]](https://cdn.slidesharecdn.com/ss_thumbnails/tfx-kfp-191031073013-thumbnail.jpg?width=640&height=640&fit=bounds)


































































