Download to read offline



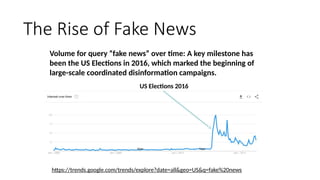















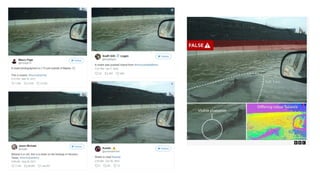

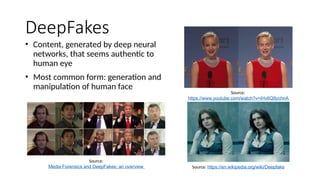




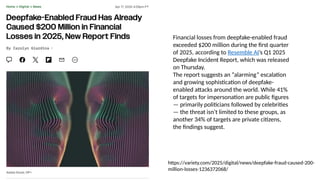
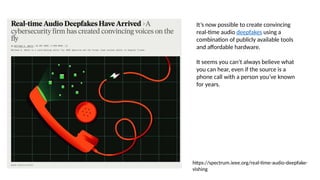
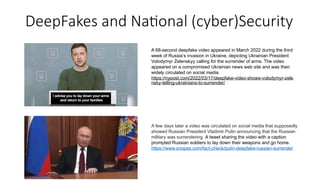

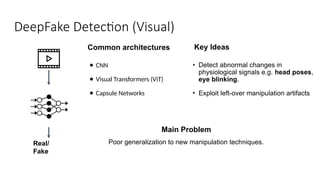








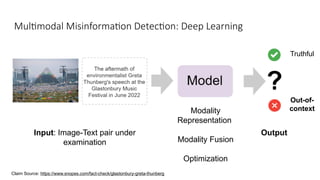

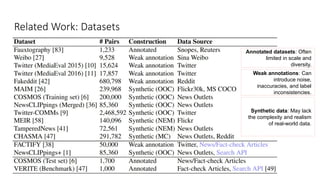

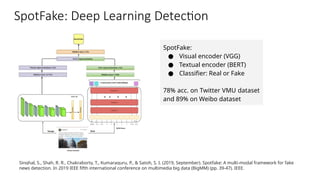
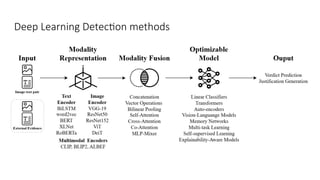
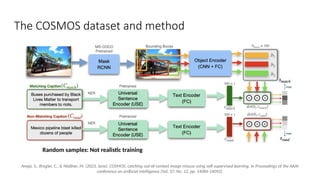


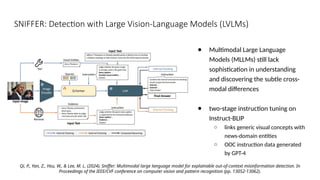

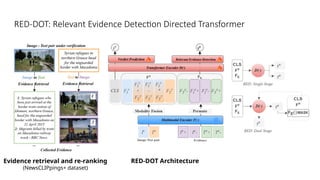






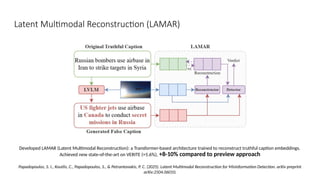
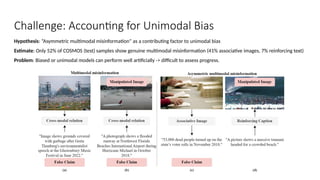

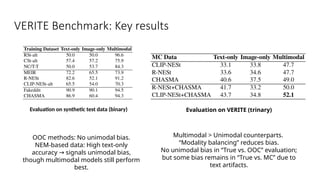


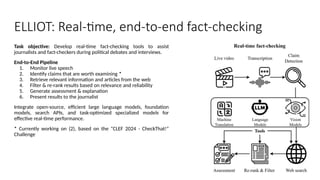
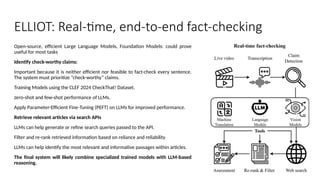




































Disinformation poses a critical threat to key societal values such as democracy, peace, health, and the economy. The rapid evolution of AI, particularly generative AI, has significantly amplified the creation and spread of disinformation, with deepfakes being a prime example. This talk will explore AI-driven approaches to counter disinformation, focusing on multimodal out-of-context misinformation detection and deepfake detection. We will also discuss the potential of Multimodal Foundation Models for fact-checking and highlight why technology alone is insufficient. Addressing disinformation effectively requires a multidisciplinary approach that considers human behavior, economic incentives, policy, and education.



































































