This document provides background information on a management and visualization tool for text mining applications developed by Peishan Mao for her MSc project. It discusses natural language text classification and describes how suffix trees can be used to represent documents at a more granular level than traditional "bag-of-words" models. The document outlines the design of the tool, which aims to provide a flexible framework for text classification experiments and allow evaluation and refinement of classifiers. It also describes the implementation of the tool in C# with a Windows Forms interface and Access database.







![5 BACKGROUND
5.1 Written Text
Writing has long been an important means of exchanging information, ideas and
concepts from one individual to another, or to a group. Indeed, it is even thought to be
the single most advantageous evolutionary adaptation for species preservation [2]. The
written text available contains a vast amount of information. The advent of the internet
and on-line documents has contributed to the proliferation of digital textual data readily
available for our perusal. Consequently, it is increasingly important to have a systematic
method of organising this corpus of information.
Tools for textual data mining are proving to be increasingly important to our growing
mass of text based data. The discipline of computing science has provided significant
contributions to this area by means of automating the data mining process. To encode
unstructured text data into a more structured form is not a straightforward task. Natural
language is rich and ambiguous. Working with free text is one of the most challenging
areas in computer science.
This project aims to investigate how computer science can help to evaluate some of the
vast amounts of textual information available to us, and how to provide a convenient way
to access this type of unstructured data. In particular, the focus will be on the data
classification aspect of data mining. The next section will explore this topic in more
depth.
5.2 Natural Language Text Classification
5.2.1 Text Classification
F Sebastiani [3] described automated text categorisation as
“The task of automatically sorting a set of documents into categories (or classes, or
topics) from a predefined set. The task, that falls at the crossroads of information
retrieval, machine learning, and (statistical) natural language processing, has witnessed
a booming interest in the last ten years from researchers and developers alike.”
Classification maps data into predefined groups or classes. Examples of classification
applications include image and pattern recognition, medical diagnosis, loan approval,
detecting faults in industry applications, and classifying financial trends. Until the late
80‟s, knowledge engineering was the dominant paradigm in automated text
categorisation. Knowledge engineering consists of the manual definition of a set of rules
which form part of a classifier by domain experts. Although this approach has produced
results with accuracies as high as 90% [3], it is labour intensive and domain specific.
The emergence of a new paradigm based on machine learning which answers many of
the limitations with knowledge engineering has superseded its predecessor.
Machine learning encompasses a variety of methods that represent the convergence of
statistics, biological modelling, adaptive control theory, psychology, and artificial
8 of 93](https://image.slidesharecdn.com/msword556/85/msword-8-320.jpg)
![intelligence (AI) [11]. Data classification by machine learning is a two-phase process
(Figure 1). The first phase involves a general inductive process to automatically build a
model by using classification algorithm that describes a predetermined set of data
classes which are non-overlapping. This step is referred to as supervised learning
because the classes are determined before examining the data and the set of data is
known as the training data set. Data in text classification comes in the form of files and
each file is often described as documents. Classification algorithms require that the
classes are defined based on purely the content of the documents. They describe these
classes by looking at the characteristics of the documents in the training set already
known to belong to the class. The learned model constitutes the classifier and can be
used to categorise future corpus samples. In the second phase, the classifier
constructed in the phase one is used for classification.
Machine leaning approach to text classification is less labour intensive, and is domain
independent. Since the attribution of documents to categories is based purely on the
content of the documents effort is thus concentrated on constructing an automatic
builder of classifiers (also known as the learner), and not the classifier itself [3]. The
automatic builder is a tool that extracts the characteristics from the training set which is
represented by a classification model. This means that once a learner is built, new
classifiers can be automatically constructed from sets of manually classified documents.
Training Classification Classification
Set Algorithm Model
a)
Classification
Model
Test Set New
Documents
b)
Figure 1. a) Step One in Text Classification b) Step two in text classification
5.2.2 The Classifier
In general a text classifier comprises a number of basic components. As noted in the
previous section, the text classifier begins with an inductive stage. A classifier requires
some sort of text representation of documents. In order to build an internal model the
inductive step involves a set of examples used for training the classifier. This set of
examples is known as the training set and each document in the training set is assigned
to a class C = {c1, c2, … cn}. All the documents used in the training phase are
transformed into internal representations.
Currently, a dominant learning method in text classification is based on a vector space
model [5]. The Naïve Bayesian is one example and is often used as a benchmark in text
9 of 93](https://image.slidesharecdn.com/msword556/85/msword-9-320.jpg)
![classification experiments. Bayesian classifiers are statistical classifiers. Classification
is based on the probability that a given document belongs to a particular class. The
approach is „naïve‟ because it assumes that the contribution by all attributes on a given
class is independent and each contributed equally to the classification problem. By
analysing the contribution of each „independent‟ attribute, a conditional probability is
determined. Attributes in this approach are the words that appear in the documents of
the training set.
Documents are represented by a vector with dimensions equal to the number of different
words within the documents of the training set. The value of each individual entry within
the vector is set at the frequency of the corresponding word. According to this approach,
training data are used to estimate parameters of a probability distribution, and Bayes
theorem is used to estimate the probability of a class. A new document is assigned to
the class that yields the highest probability. It is important to perform pre-processing to
remove frequent words such as stop words before a training set is used in the inductive
phase.
The Naïve Bayesian approach has several advantages. Firstly, it is easy to use;
secondly only one scan of the training data is required. It can also easily handle missing
values by simply omitting that probability when calculating the likelihoods of membership
in each class. Although the Naïve Bayesian-based classifier is popular, documents are
represented as a „bag-of-words‟ where words in the document have no relationships with
each other. However words that appear in a document are usually not independent.
Furthermore, the smallest unit of representation is a word.
Research is continuously investigating how designs of text classifiers can be further
improved and Pampapathi et al [1] at Birkbeck College, London recently proposed a new
innovative approach to the internal modelling of text classifiers. They used a well known
data structure called a suffix tree [11] which allows for indexing the characteristics of
documents at a more granular level, with documents represented by substrings. The
suffix tree is a compact trie containing all the suffixes of strings represented. A trie is a
tree structure, where each node represents one character, and the root represents the
null string. Each path from the root represents a string, described by the characters
labelling the nodes traversed. All strings sharing a common prefix will branch off from a
common node. When strings are words over a to z, a node has at most 26 children, one
for each letter (or 27 children, plus a terminator). Suffix trees have traditionally been
used for complex string matching problems in matching string sequences (data
compression, DNA sequencing). Pampapathi et al‟s research is the first to apply suffix
trees to natural language text classification.
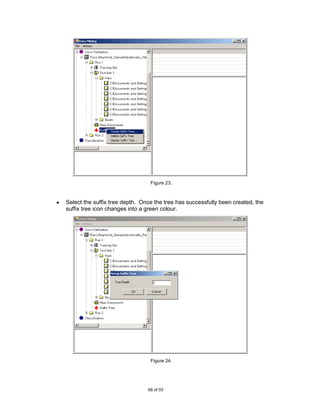
Pampapathi et al‟s method of constructing the suffix tree varies slightly from the
standard way. Firstly, the tree nodes are labelled instead of the edges in order to
associate directly the frequency with the characters and substrings. Secondly, a special
terminal character is not used as the focus is on the substrings and not the suffixes.
Each suffix tree has a depth. The depth is described by the maximum number of levels
in the tree. A level is defined by the number of nodes away from the root node. For
example the suffix tree illustrated in Figure 2 has a depth of 4. Pampapathi et al‟s sets a
limit to the tree depth and each node of the suffix tree stores the frequency and the
character.
For example, to construct a suffix tree for the string S1 = “COOL”, the suffix tree in Figure
2 is created. The substrings are COOL; OOL; OL; and L.
10 of 93](https://image.slidesharecdn.com/msword556/85/msword-10-320.jpg)


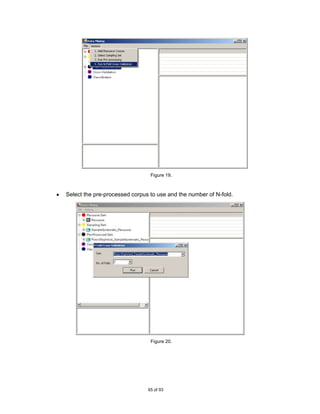
![partitioning the dataset (initial corpus) randomly into N equally sized non-overlapping
blocks/folds. Then the training-testing process is run N times, with a different test set.
For example, when N=3, we will have the following training and test sets.
Block 1 Train Test
Run 1 1, 2 3
Block 2
Run 2 1, 3 2
Block 3 Run 3 2, 3 1
Figure 5. 3-Fold Cross-Validation
For each cross-validation run the user will be able to use a training set to build the
classifier.
Stratified N-fold cross-validation is a recommended method for estimating classifier
accuracy due to its low bias and variance [13]. In stratified cross-validation, the folds are
stratified so that the class distribution of the samples in each fold is approximately the
same as that of the initial training set.
Preparing the training set data for classification using pre-processing can help improve
the accuracy, efficiency, and scalability of the evaluation of the classification. Methods
include stop word removal, punctuation removal, and stemming.
The use of the above techniques to prepare the data and estimate classifier accuracy
increases the overall computational time yet is useful for evaluating a classifier, and
selecting among several classifiers.
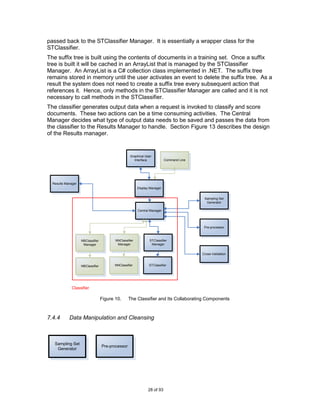
The current project aims to build a system which is a wrapper to a text classifier and
incorporates the suffix tree that was used in the research done by Pampapathi et al as
an example. The next section and beyond describes the project in detail.
13 of 93](https://image.slidesharecdn.com/msword556/85/msword-13-320.jpg)

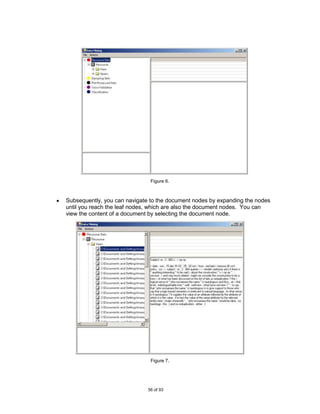
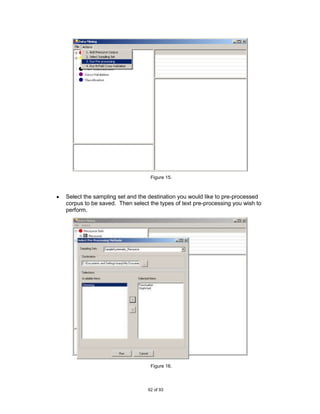
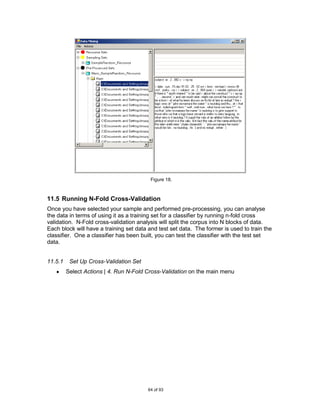
![6.1.2 Evaluate and Refine the Classifier
In research once a classifier has been built it is desirable to evaluate its effectiveness.
Even before the construction of the classifier the tool provides a platform for users to
perform a number of experiments and refinements on the source (training) data. Hence,
the second focus of the project is to provide a user-friendly front-end and a base
application for testing classification algorithms.
The user can load in a text based corpus and perform standard pre-processing functions
to remove noise and prepare the data for experimentation. There is also a choice of
sampling methods to use in order to reduce the size of the initial corpus making it more
manageable.
Sebastiani [2] notes that any classifier is prone to classification error, whether the
classifier is human or machine. This is due to a central notion to text classification that
the membership of a document in a class based on the characteristics of the document
and the class is inherently subjective, since the characteristics of both the documents
and class cannot be formally specified. As a result automatic text classifiers are
evaluated using a set of pre-classified documents. The accuracy of classifiers is
compared to the classification decision and the original category the documents were
assigned to. For experimentation and evaluation purpose, this set of pre-classified
documents is split into two sets: a training set and test set, not necessarily of equal
sizes.
The tool implements an extra level of experimentation using n-fold cross-validation.
When employing cross-validation in classification it must take into account that the data
is grouped by classes therefore this project will implement stratified cross-validation.
Once a classifier has been constructed, it is possible to perform data classification
experiments as well as other tasks such as single document analysis. For example, for
the implementation of a suffix tree-based classifier the user will be able to view the
structure of the suffix tree, as well, the documents in the test sets or load a new
document and obtain a full matrix of output data about it. The output data is persisted in
an information system which is subsequently used to perform analysis and visualisation
tasks.
6.2 Development and Technologies
Development was done in C#, using the .NET framework. The architect of the system
was designed to be an extensible platform to enable users and developers to leverage
the existing framework for future system upgrades. The tool was built from several
components and aims to be modular. There are a number of controller components to
provide functionalities for the tool. A set of libraries is used to provide the functionalities
for the suffix tree. Working closely with researchers from Birkbeck College on the
interface, these libraries for the suffix tree were provided by Birkbeck College.
The suffix tree data structure is built in memory and can become very large. One
solution to better utilise resources is to have the data structure physically stored as one
tree, although it is logically represented as individual trees for each class. Further
discussion can be found in subsequent sections.
15 of 93](https://image.slidesharecdn.com/msword556/85/msword-15-320.jpg)


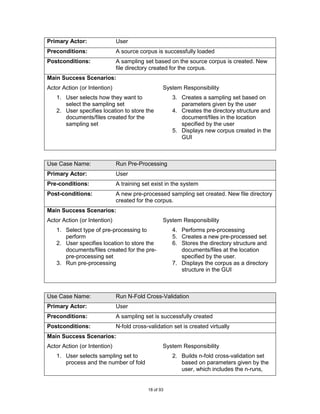










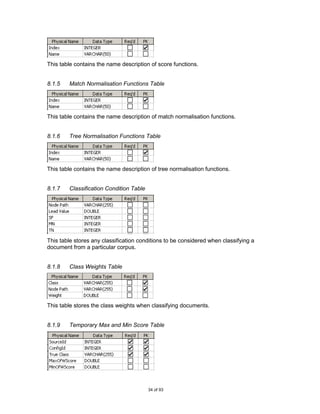
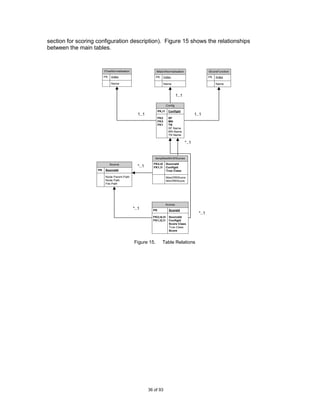
![7.5 Class Diagram
Figure 14 shows a class diagram of the main components of the system discussed above
Controllers::DisplayManager
MainForm
-nodeMgr : TreeViewNodeManager
-tvExplorer -classifier : CentralManager
-sTreeView -dbProvider : string
-rtxtView -dbUserId : string
-rtxtInfo -dbPassword : string
-mItemAddRCorpus_Click(in sender : object, in e) -dbName : string
-mitemSelectSampling_Click(in sender : object, in e) -Controlled By
-dbAccessMode : string 1
-mitemPreprocess_Click(in sender : object, in e) +AddNode(in destNode : TreeNode, in nodeNames : string[], in imageIdx : TreeImages, in selectedImageIdx : TreeImages)
-mitemCrossValidation_Click(in sender : object, in e) +FindNode(in selectedNode : TreeNode, in nodeName : string) : TreeNode
-CreateSTree_Click(in sender : object, in e) 1..*
+DisplayBlank()
-DeleteSTree_Click(in sender : object, in e) +DisplayFile(in filePathname : string)
-DisplaySuffixTree_Click(in sender : object, in e) +SelectSampleCorpus(in defaultCorpus : string, in sourceNode : TreeNode, in destNode : TreeNode)
-AddNewDoc_Click(in sender : object, in e) +AddNewClassificationSet(in treeStructure : TreeView, in sourceNode : TreeNode, in destRoot : string)
-AddClassificationSet_Click(in sender : object, in e) 1 +PerformPreprocessing(in defaultCorpus : string, in sourceNode : TreeNode, in destNode : TreeNode)
-ScoreAllDoc_Click(in sender : object, in e) -PerformCrossValidation(in defaultCorpus : string, in sourceNode : TreeNode, in destNode : TreeNode)
-ClassifyAllDocs_Click(in sender : object, in e) +SetupSTree(in defaultCorpus : string, in sourceFilesNode : TreeNode, in STreeNode : TreeNode)
+DisplayScoresByDoc(in displayView : ListView, in sourceNode : TreeNode, in filepath : string)
+ScoreAllDocuments(in sourceDataNode : TreeNode, in sTreeNodeName : string)
+ClassifyAllDocuments(in sourceDataNode : TreeNode, in sTreeNodeName : string)
+FlagMisClassifiedDocuments(in sourceNodePath : string, in sourceDataNode : TreeNode, in sf : int, in mn : int, in tn : int)
+DeleteScores(in parentPath : string)
+DeleteSTree(in STreeNode : TreeNode)
+DisplaySTree(in displayTxt : Label, in diplayView : TreeView, in defaultCorpus : string, in dataSource : TreeNode, in STreeNode : TreeNode) Controllers::SampleSetGenerator
+GetMatchInfo(in text : string, in STreeNode : TreeNode) : string -error : string
+CleanupDatabase() -Controls
-methodNames : string[] = new string[] {"Census", "Random", "Systematic"}
+ErrorMessage() : string
1 1 -CodeToName(in code : int) : string
+Run(in resourcePath : string, in destPath : string, in selectMethod : string)
1 -Controls +MethodNames() : string[]
Classifier::CentralManager
-sampler : SampleSetGenerator
-preprocessor : Preprocessor Controllers::CrossValidation
1 -crossValidator : CrossValidation -folds : Array[]
-dataModelMgr : SuffixTreeManager -noOfFolds : int
-outputMgr : DatabaseManager -minFold : int = 2
1
-error : string -maxFold : int = 10
1 -Controls
+Create(in key : string, in classNames : string[], in depth : int, in classFiles : FileInfo[][]) : bool -error : string
+Contains(in key : string) : bool -Performs 1 +ErrorMessage() : string
Output::DatabaseManager +Remove(in key : string) +CrossValidation(in folds : int)
+GetClassNames(in key : string) : string[] +Run(in path : string) : Array[]
-dbAccess : OLEDB +GetClassScores(in key : string, in className : string, in doc : string) : double[,,] 1
-dbProvider : string +FoldCount() : int
+ErrorMessage() : string
-dbUserId : string +CentralManager() -Controls
-dbPassword : string +GetModel(in key : string) : EMSTreeClassifier
-dbName : string +GetFrequency(in key : string, in matchText : string, in classIdx : int) : int Controllers::Preprocessor
-ScoresTable : string = "Scores" +Sampler() : SampleSetGenerator 1
-ConfigTable : string = "Config" -stopWordFile : string
+Preprocessor() : Preprocessor
-ClassWeightsTable : string = "ClassWeights" -punctuationFile : string
+CrossValidator() : CrossValidation
-ClassifiedTable : string = "qry3a_MaxWScoreClass" -methodNames : string[] = new string[methodCount]
+OutputManager() : DatabaseManager
-MisClassifyFiles : string = "qry2b_MisClassifiedByFile" -error : string
-MatchByClass : string = "zqry2b_matchByClass_Crosstab" +ErrorMessage() : string
-error : string 1 1 +Preprocessor()
-bOpen : bool -SetupMethodNames()
+ErrorMessage() : string -CodeToName(in code : int) : string
+DatabaseManager() +Run(in content : string, in type : string) : string
+SelectScoresByFile(in parentPathNode : string, in filePath : string) : OleDbDataReader +MethodNames() : string[]
+SelectMisClassifiedDocuments(in parentPathNode : string, in sf : int, in mn : int, in tn : int) : OleDbDataReader
+SelectClassifiedClass(in sourceNodePath : string, in filepath : string, in sf : int, in mn : int, in tn : int) : OleDbDataReader 1
+DeleteScores(in ParentNodePath : string)
+Provider() : string
+UserId() : string
+Password() : string 1 -Controls 1 -Has
+DatabaseName() : string
Classifier::SuffixTreeManager DataMining::StopWord
1
-createdSTreeList : SortedList -name : string
-error : string -stringList : ArrayList = new ArrayList()
1 -Access Database -error : string
+Create(in key : string, in classNames : string[], in depth : int, in classFiles : FileInfo[][]) : bool
+Contains(in key : string) : bool +Name() : string
Output::OLEDB +Remove(in key : string) +Run(in text : string) : string
-oleDbDataAdapter : OleDbDataAdapter +GetClassNames(in key : string) : string[] +ErrorMessage() : string
-oleDbConnection : OleDbConnection +GetClassScores(in key : string, in className : string, in doc : string) : double[,,] +StopWord(in filePathName : string)
-oleDbInsertCommand : OleDbCommand +ErrorMessage() : string +Add(in filePathName : string)
-oleDbDeleteCommand : OleDbCommand +SuffixTreeManager() -AddWord(in targetWord : string)
-oleDbUpdateCommand : OleDbCommand -AddSTreeToCache(in key : string, in sTree : EMSTreeClassifier) : bool +Clear()
-oleDbSelectCommand : OleDbCommand +GetModel(in key : string) : EMSTreeClassifier +Reset() 1 -Controls
+oleDbDataReader : OleDbDataReader +GetFrequency(in key : string, in matchText : string, in classIdx : int) : int +Contains(in word : string) : bool
-command : COMMAND +StringList() : ArrayList
-error : string 1
-bOpen : bool
+ErrorMessage() : string 1..* -Access
Controllers::TreeViewNodeManager
+IsOpen() : bool
+InsertCommand() : string -error : string
EMSTreeClassifier
+DeleteCommand() : string +ErrorMessage() : string
+UpdateCommand() : string -className : string[]
+ChildNameExist(in TargetNode : TreeNode, in matchName : string) : bool
+SelectCommand() : string -dictionary : string[]
+GetClassFiles(in classFileParent : TreeNode) : FileInfo[][]
+GetReader() : OleDbDataReader -dictionaryByClass : string[][]
+GetChildrenNodeNames(in targetNode : TreeNode) : string[]
+ExecuteCommand() : bool -mergedTree : EMSTreeClassifier.EMSTree
+GetTreeNode(in targetNodeName : string, in Parentnode : TreeNode) : TreeNode
-SelectReader() : OleDbDataReader +addToClass(in txt : string, in class : string) +DisplaySTree(in displayView : TreeView, in sTree : EMSTreeClassifier, in classFreqToDisplay : string[])
-UpdateReader() : OleDbDataReader +classIntToName(in classInt : int) : string +AddItemToTreeView(in root : TreeNode, in childNames : params string[]) : TreeNode
-InsertReader() : OleDbDataReader +classNameToInt(in className : string) : int +AddCrossValidationSetsToTreeView(in sourceNode : TreeNode, in content : Array[])
-DeleteReader() : OleDbDataReader +classScore(in example : string, in class : string, in nsf : int, in nmnf : int, in ntnf : int) : double[,,] -PopulateRunNode(in content : Array[], in testSetNum : int, in parentNode : TreeNode)
+OLEDB() +maxScore(in a : double[]) : static int -Combine(in array1 : FileInfo[][], in array2 : FileInfo[][]) : FileInfo[][]
+Open(in Provider : string, in UserID : string, in Password : string, in DatabaseName : string, in Mode : string) +setDepth(in d : int) +AddItem(in destNode : TreeNode, in newNodeName : string, in imageIdx : TreeImages) : TreeNode
+Close() +train(in classTrainingFiles : <unspecified>[][]) : bool -CreateNewNode(in nodeName : string, in imageIdx : TreeImages) : TreeNode
Figure 14. Class Diagram
32 of 93](https://image.slidesharecdn.com/msword556/85/msword-32-320.jpg)





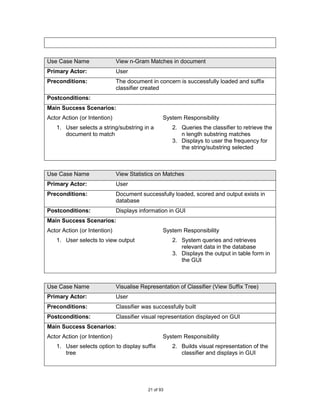
![Controllers::DisplayManager
-nodeMgr : TreeViewNodeManager
-classifier : CentralManager
-dbProvider : string
-dbUserId : string
-dbPassword : string
-dbName : string
-dbAccessMode : string
+AddNode(in destNode : TreeNode, in nodeNames : string[], in imageIdx : TreeImages, in selectedImageIdx : TreeImages)
+FindNode(in selectedNode : TreeNode, in nodeName : string) : TreeNode
+DisplayBlank()
+DisplayFile(in filePathname : string)
+SelectSampleCorpus(in defaultCorpus : string, in sourceNode : TreeNode, in destNode : TreeNode)
+AddNewClassificationSet(in treeStructure : TreeView, in sourceNode : TreeNode, in destRoot : string)
+PerformPreprocessing(in defaultCorpus : string, in sourceNode : TreeNode, in destNode : TreeNode)
-PerformCrossValidation(in defaultCorpus : string, in sourceNode : TreeNode, in destNode : TreeNode)
+SetupSTree(in defaultCorpus : string, in sourceFilesNode : TreeNode, in STreeNode : TreeNode)
+DisplayScoresByDoc(in displayView : ListView, in sourceNode : TreeNode, in filepath : string)
+ScoreAllDocuments(in sourceDataNode : TreeNode, in sTreeNodeName : string)
+ClassifyAllDocuments(in sourceDataNode : TreeNode, in sTreeNodeName : string)
+FlagMisClassifiedDocuments(in sourceNodePath : string, in sourceDataNode : TreeNode, in sf : int, in mn : int, in tn : int)
+DeleteScores(in parentPath : string)
+DeleteSTree(in STreeNode : TreeNode)
+DisplaySTree(in displayTxt : Label, in diplayView : TreeView, in defaultCorpus : string, in dataSource : TreeNode, in STreeNode : TreeNode)
+GetMatchInfo(in text : string, in STreeNode : TreeNode) : string
+CleanupDatabase()
Figure 18. DisplayManager Class Definition
9.3 Classifier Classes
The classifier components implemented are:
Central Manager class
IClassifierModel interface
STClassifierManager class
STClassifier class
At the lowest level of the classifier classes is the STClassifier class which performs
generic suffix tree operations such as create suffix tree, train suffix tree, add classes,
and score class. The STClassifierManager is a controller or it can also be seen as a
wrapper for the STClassifier class. This class contains methods to perform tasks that
are more specific to the system. In order to plug in a classifier model into the Central
Manager it must implement the IClassifierModel interface. The figures below show the
members and class interfaces for the classes.
40 of 93](https://image.slidesharecdn.com/msword556/85/msword-40-320.jpg)
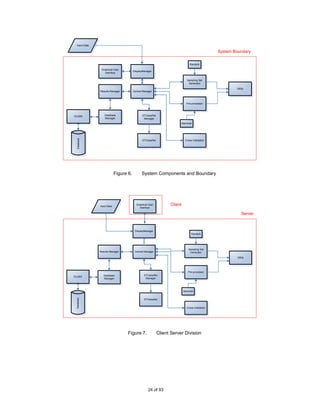
![Classifier::CentralManager
-sampler : SampleSetGenerator
-preprocessor : Preprocessor
-crossValidator : CrossValidation
-dataModelMgr : SuffixTreeManager
-outputMgr : DatabaseManager
-error : string
+Create(in key : string, in classNames : string[], in depth : int, in classFiles : FileInfo[][]) : bool
+Contains(in key : string) : bool
+Remove(in key : string)
+GetClassNames(in key : string) : string[]
+GetClassScores(in key : string, in className : string, in doc : string) : double[,,]
+ErrorMessage() : string
+CentralManager()
+GetModel(in key : string) : EMSTreeClassifier
+GetFrequency(in key : string, in matchText : string, in classIdx : int) : int
+Sampler() : SampleSetGenerator
+Preprocessor() : Preprocessor
+CrossValidator() : CrossValidation
+OutputManager() : DatabaseManager
Figure 19. CentralManager Class Definition
«interface»DataMining::IClassifierModel
+Create(in key : string, in classNames : string[], in depth : int, in classFiles : FileInfo[][]) : bool
+Contains(in key : string) : bool
+Remove(in key : string)
+GetClassNames(in key : string) : string[]
+GetClassScores(in key : string, in className : string, in doc : string) : double[,,]
Figure 20. IClassifierModel Interface Definition
Classifier::SuffixTreeManager
-createdSTreeList : SortedList
-error : string
+Create(in key : string, in classNames : string[], in depth : int, in classFiles : FileInfo[][]) : bool
+Contains(in key : string) : bool
+Remove(in key : string)
+GetClassNames(in key : string) : string[]
+GetClassScores(in key : string, in className : string, in doc : string) : double[,,]
+ErrorMessage() : string
+SuffixTreeManager()
-AddSTreeToCache(in key : string, in sTree : EMSTreeClassifier) : bool
+GetModel(in key : string) : EMSTreeClassifier
+GetFrequency(in key : string, in matchText : string, in classIdx : int) : int
Figure 21. SuffixTreeManager Class Definition
EMSTreeClassifier
-className : string[]
-dictionary : string[]
-dictionaryByClass : string[][]
-mergedTree : EMSTreeClassifier.EMSTree
+addToClass(in txt : string, in class : string)
+classIntToName(in classInt : int) : string
+classNameToInt(in className : string) : int
+classScore(in example : string, in class : string, in nsf : int, in nmnf : int, in ntnf : int) : double[,,]
+maxScore(in a : double[]) : static int
+setDepth(in d : int)
+train(in classTrainingFiles : <unspecified>[][]) : bool
Figure 22. EMSTreeClassitier Class Definition
9.4 Results Output Classes
41 of 93](https://image.slidesharecdn.com/msword556/85/msword-41-320.jpg)
![The output components implemented are:
IOutput interface
DatabaseManager class
OLEDB class
This project employed an Access database for its data storage component. At the
lowest level of the results output classes is the OLEDB class. This class has direct
access to the database and has methods to perform generic database commands such
as connect to database, close connection to database, insert, and SQL delete, update,
and select commands. The DatabaseManager class is a controller or it can also be
seen as a wrapper for the OLEDB class to call methods to perform tasks more specific
to the system. Notice that the IOutput interface has replaced the previously proposed
Output Manager class. It was found that there was no real need to have another class
between the Database Manager and the rest of the system, but instead to implement a
contract to ensure that the Database Manager would provide a minimum of certain
functionalities such as open a data store, close a data store, select, update, and delete.
The figures below illustrate the definitions of the components.
«interface»DataMining::IOutput
+Open()
+Close()
+InsertScores(in : double[,,], in : string, in : string, in : string, in : string, in : string)
+Select(in : string) : string
+Update(in : string)
+Delete(in : string)
+DeleteAll()
+IsOpen() : bool
Figure 23. IOutput Interface Definition
Output::DatabaseManager
-dbAccess : OLEDB
-dbProvider : string
-dbUserId : string
-dbPassword : string
-dbName : string
-ScoresTable : string = "Scores"
-ConfigTable : string = "Config"
-ClassWeightsTable : string = "ClassWeights"
-ClassifiedTable : string = "qry3a_MaxWScoreClass"
-MisClassifyFiles : string = "qry2b_MisClassifiedByFile"
-MatchByClass : string = "zqry2b_matchByClass_Crosstab"
-error : string
-bOpen : bool
+ErrorMessage() : string
+DatabaseManager()
+SelectScoresByFile(in parentPathNode : string, in filePath : string) : OleDbDataReader
+SelectMisClassifiedDocuments(in parentPathNode : string, in sf : int, in mn : int, in tn : int) : OleDbDataReader
+SelectClassifiedClass(in sourceNodePath : string, in filepath : string, in sf : int, in mn : int, in tn : int) : OleDbDataReader
+DeleteScores(in ParentNodePath : string)
+Provider() : string
+UserId() : string
+Password() : string
+DatabaseName() : string
Figure 24. DatabaseManager Class Definition
42 of 93](https://image.slidesharecdn.com/msword556/85/msword-42-320.jpg)
![Output::OLEDB
-oleDbDataAdapter : OleDbDataAdapter
-oleDbConnection : OleDbConnection
-oleDbInsertCommand : OleDbCommand
-oleDbDeleteCommand : OleDbCommand
-oleDbUpdateCommand : OleDbCommand
-oleDbSelectCommand : OleDbCommand
+oleDbDataReader : OleDbDataReader
-command : COMMAND
-error : string
-bOpen : bool
+ErrorMessage() : string
+IsOpen() : bool
+InsertCommand() : string
+DeleteCommand() : string
+UpdateCommand() : string
+SelectCommand() : string
+GetReader() : OleDbDataReader
+ExecuteCommand() : bool
-SelectReader() : OleDbDataReader
-UpdateReader() : OleDbDataReader
-InsertReader() : OleDbDataReader
-DeleteReader() : OleDbDataReader
+OLEDB()
+Open(in Provider : string, in UserID : string, in Password : string, in DatabaseName : string, in Mode : string)
+Close()
Figure 25. OLEDB Class Definition
9.5 Other Controller Classes
The SampleSetGenerator, Preprocessor, and CrossValidation classes have a fairly
simple class interface.
The most important method for each class is to execute the main task it is responsible
for. That is to create a sampling set/corpus for the SampleSetGenerator class, Perform
pre-processing for the Preprocessor class, and run cross-validation for the
CrossValidation class.
Controllers::SampleSetGenerator
-error : string
-methodNames : string[] = new string[] {"Census", "Random", "Systematic"}
+ErrorMessage() : string
-CodeToName(in code : int) : string
+Run(in resourcePath : string, in destPath : string, in selectMethod : string)
+MethodNames() : string[]
Figure 26. SampleSetGenerator
Controllers::Preprocessor
-stopWordFile : string
-punctuationFile : string
-methodNames : string[] = new string[methodCount]
-error : string
+ErrorMessage() : string
+Preprocessor()
-SetupMethodNames()
-CodeToName(in code : int) : string
+Run(in content : string, in type : string) : string
+MethodNames() : string[]
Figure 27. Preprocessor Class Definition
43 of 93](https://image.slidesharecdn.com/msword556/85/msword-43-320.jpg)
![Controllers::CrossValidation
-folds : Array[]
-noOfFolds : int
-minFold : int = 2
-maxFold : int = 10
-error : string
+ErrorMessage() : string
+CrossValidation(in folds : int)
+Run(in path : string) : Array[]
+FoldCount() : int
Figure 28. CrossValidation Class Definition
The SampleSetGenerator class and the Preprocessor class have additional
methodology classes plugged into them. As can be seen by each respective class, they
have a class member called methodNames. This is an array that stores the method
names each method implemented in the system.
The Preprocessor class implements three pre-processing methodologies: punctuation
removal, stop word removal, and stemming. Each method class has to implement the
IMethod interface.
Additional sampling methodologies that are plugged into the class can each be built as
new classes and has to implement the IMethod interface
The SampleSetGenerator class similarly implements three sampling methodologies:
census sampling, random sampling, and systematic sampling.
See appendix x for all class definitions. Below illustrates the IMethod interface definition
and example of the StopWord method that is plugged into the Preprocessor class.
«interface»
DataMining::IMethod
+Name() : string
+Run(in text : string) : string
Figure 29. IMethod Interface Definition
DataMining::StopWord
-name : string
-stringList : ArrayList = new ArrayList()
-error : string
+Name() : string
+Run(in text : string) : string
+ErrorMessage() : string
+StopWord(in filePathName : string)
+Add(in filePathName : string)
-AddWord(in targetWord : string)
+Clear()
+Reset()
+Contains(in word : string) : bool
+StringList() : ArrayList
Figure 30. StopWord Class Definition
9.6 TreeView Controller Class
During development it was discovered that it made sense to implement a separate
controller class to manage the nodes displayed in the interface of the tvExplorer control
44 of 93](https://image.slidesharecdn.com/msword556/85/msword-44-320.jpg)
![and the sTreeView control. The TreeViewNodeManager was implemented to handle
TreeView nodes operations. The class included methods to perform the following tasks:
Create a new TreeNode in a TreeView control
Add TreeNode to a TreeView control
Search for a TreeNode in a TreeView control
Get a child TreeNode
Controllers::TreeViewNodeManager
-error : string
+ErrorMessage() : string
+ChildNameExist(in TargetNode : TreeNode, in matchName : string) : bool
+GetClassFiles(in classFileParent : TreeNode) : FileInfo[][]
+GetChildrenNodeNames(in targetNode : TreeNode) : string[]
+GetTreeNode(in targetNodeName : string, in Parentnode : TreeNode) : TreeNode
+DisplaySTree(in displayView : TreeView, in sTree : EMSTreeClassifier, in classFreqToDisplay : string[])
+AddItemToTreeView(in root : TreeNode, in childNames : params string[]) : TreeNode
+AddCrossValidationSetsToTreeView(in sourceNode : TreeNode, in content : Array[])
-PopulateRunNode(in content : Array[], in testSetNum : int, in parentNode : TreeNode)
-Combine(in array1 : FileInfo[][], in array2 : FileInfo[][]) : FileInfo[][]
+AddItem(in destNode : TreeNode, in newNodeName : string, in imageIdx : TreeImages) : TreeNode
-CreateNewNode(in nodeName : string, in imageIdx : TreeImages) : TreeNode
Figure 31. TreeViewNodeManager Class Definition
9.7 Error Interface
The IErrorRecord simply returns an error message. This interface is implemented by all
the classes in the system apart from the MainForm class and the DisplayManager class.
«interface»DataMining::IErrorRecord
+ErrorMessage() : string
Figure 32. IErrorRecord Interface Definition
45 of 93](https://image.slidesharecdn.com/msword556/85/msword-45-320.jpg)


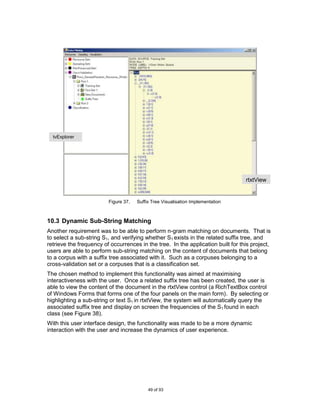


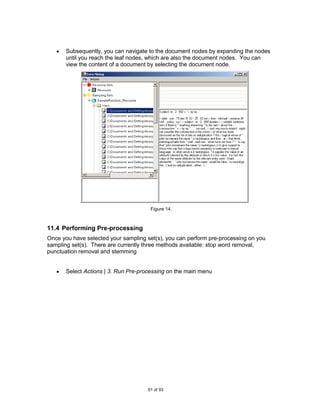
![Figure 4.
Then select the directory where your data is located and click [OK]. Note that the
input data has to be in the standard structure as explained in section x.
Figure 5.
Once you have selected the data, it will be displayed as two levels of child nodes
under the Resource Sets node. The system uses the same names for the child
nodes as the folder directory names used in the input data.
55 of 93](https://image.slidesharecdn.com/msword556/85/msword-55-320.jpg)










![14 BIBLIOGRAPHY
[1] Rajesh M. Pampapathi, Boris Mirkin, Mark Levene. A suffix Tree Approach to
Text Categorisation Applied to Spam Filtering. Available online:
http://arxiv.org/abs/cs.AI/0503030, February 2005.
[2] Donald P. Ryan. Ancient Languages and Scripts. Webpage (last accessed 10
August 2005): http://www.plu.edu/~ryandp/texts.html
[3] Fabrizio Sebastiani. Text Categorization. In Alessandro Zanasi (ed.), Text Mining
and its Applications, WIT Press, Southampton, UK, 2005, p109-129.
[4] Fabrizio Sebastiani. A Tutorial on Automated Text Categorisation. Istituto di
Elaborazione dell‟Informazione. Consiglio Nazionale delle Ricerche. Via S. Maria,
46-56126 Pisa (Italy), 1999.
[5] Joachims T. Text Categorization with Support Vector Machines: Learning with
Many Relevant Features. In Nedellec C & Rouveirol C (eds.) Proceedings of
ECML-98, 10th European Conference on Machine Learning. Lecture Notes in
Computer Science series, no. 1398 Heidelberg: Springer Verlag 1998. p137-142.
[6] Gill Benjerano and Golan Yona. Variations on Probabilistic Suffix Trees:
Statistical Modelling and Prediction of Protein Families School of Computer
Science and Engineering, Hebrew University, Jerusalem 91904, Israel and
Department of Structural Biology, Fairchild Bldg. D-109, Stanford University, CA,
94305, USA.
[7] Fabrizio Sebastiani. Machine Learning in Automated Text Categorization. ACM
Computing Surveys, 34(1), pp. 1-47, 2002.
[8] Yiming Yang. An Evaluation of Statistical Approached to Text Categorization.
Information Retrieval, vol. 1, No 1/2., Kluwer Academic Publishers pp. 69-90,
1999.
[9] C. Manning and H. Schutze. Foundations of Statistical Natural Language
Processing MIT Press, 1999.
[10] M. F. Porter. An algorithm for suffix stripping. In Readings in Information
Retrieval, pp 313-316. Morgan Kaufmann Publishers Inc, 1997.
86 of 93](https://image.slidesharecdn.com/msword556/85/msword-86-320.jpg)
![Note: the algorithm was originally described in Porter, M. F., 1980, An algorithm
for suffix stripping, Program, 14(3) : 130-137. It has since been reprinted in
Sparck Jones, Karen, and Peter Willet, 1997, Readings in Information Retrieval,
San Francisco: Morgan Kaufmann, ISBN 1-55860-454-4
[11] Dan Gusfield. Algorithms on Strings, Trees, and Sequences. Computer
Science and Computational Biology. Cambridge University Press. 1997.
[12] Jiawei Han. Data Mining: Concepts and Techniques. Morgan Kaufmann,
Academic Press. Lonond. 2001.
[13] Margaret H. Dunham. Data Mining and advance topics. Prentice Hall.
London. 2003.
[14] Craig Larman. Applying UML and Patterns, An Introduction to Object-
oriented Analysis and Design and the Unified Process (2nd Ed). Prentice Hall
PTR, US, 2002.
[15] Martin Fowler. UML Distilled, A Brief Guide to the Standard Object
Modeling Language (3rd ed). Pearson Education Inc, Boston, 2004.
[16] Dave Thomas, Agile Programming: design to accommodate Change. IEE
Software www.computer.org/software, vol. 22, No 3 May/June 2005.
[17] Peter Drayton, Ben Albahari and Ted Neward. C# in a nutshell: a desktop
quick reference. O‟Reilly & Associates. California. 2002.
[18] Jesse Liberty. Programming C#. O‟Reilly. Beijing Cambridge. 2003.
[19] C
87 of 93](https://image.slidesharecdn.com/msword556/85/msword-87-320.jpg)
![15 APPENDIX A DATABASE
Last Score ID:
SELECT Max(Scores.ScoreId) AS MaxOfScoreId
FROM Scores;
Last Source ID:
SELECT Max(Source.SourceId) AS MaxOfSourceId
FROM Source;
Weighted Scores View Query:
SELECT Scores.ScoreId, Scores.SourceId, Scores.ConfigId, Scores.[Score Class],
Scores.[True Class], Scores.Score, [Score]*ClassWeights.Weight AS
WScore
FROM (
Source
INNER JOIN ClassWeights ON Source.[Node Parent Path] =
ClassWeights.[Node Path]) INNER JOIN Scores ON
Source.SourceId = Scores.SourceId
WHERE (((Scores.[Score Class])=[Class])
);
Maximum and Minimum Scores View Query:
SELECT MaxWTable.SourceId, MaxWTable.ConfigId, MaxWTable.[True Class],
MaxWTable.MaxOfWScore, MaxWTable.MinOfWScore
FROM (
SELECT ws2.SourceId, ws2.ConfigId, ws2.[True Class],
Max(ws2.WScore) AS MaxOfWScore,
Min(ws2.WScore) AS MinOfWScore
FROM WeightedScores AS ws2
GROUP BY ws2.SourceId, ws2.ConfigId, ws2.[True Class]
) AS MaxWTable
WHERE (
((MaxWTable.MaxOfWScore) Not In (
SELECT Count(ws3.WScore) AS CountOfWScore
FROM WeightedScores AS ws3
88 of 93](https://image.slidesharecdn.com/msword556/85/msword-88-320.jpg)
![GROUP BY ws3.SourceId, ws3.ConfigId, ws3.[True
Class], ws3.WScore
HAVING ( Count(ws3.WScore) >1)
))
);
Misclassified Documents:
SELECT Source.[Node Path], Source.[File Path], Config.SF, Config.MN,
Config.TN, t2.[True Class], t2.[Score Class], t2.WScore
FROM (
(qry2a_MaxMinLeadWScoresByFile AS t1
INNER JOIN qry2a_MaxMinLeadWScoresByFile AS t2 ON
(t1.SourceId = t2.SourceId)
AND (t1.ConfigId = t2.ConfigId)) INNER JOIN Source ON
t1.SourceId = Source.SourceId)
INNER JOIN Config ON t1.ConfigId = Config.ConfigId
WHERE (((t2.[True Class])<>[t2].[Score Class]) AND ((t1.[True
Class])=[t1].[Score Class]) AND ((t1.NScore)<[t2].[LeadDiff]));
89 of 93](https://image.slidesharecdn.com/msword556/85/msword-89-320.jpg)
![16 APPENDIX B CLASS DEFINITIONS
Intefaces:
«interface»DataMining::IClassifierModel «interface»
DataMining::IMethod
+Create(in key : string, in classNames : string[], in depth : int, in classFiles : FileInfo[][]) : bool
+Contains(in key : string) : bool +Name() : string
+Remove(in key : string) +Run(in text : string) : string
+GetClassNames(in key : string) : string[]
+GetClassScores(in key : string, in className : string, in doc : string) : double[,,]
«interface»DataMining::IOutput
+Open()
+Close()
+InsertScores(in : double[,,], in : string, in : string, in : string, in : string, in : string)
+Select(in : string) : string
+Update(in : string)
+Delete(in : string)
«interface»DataMining::IErrorRecord
+DeleteAll()
+IsOpen() : bool +ErrorMessage() : string
Data Types:
DataType::TreeNormalisation DataType::MatchNormalisation «enumeration»DataType::TreeImages
-averageFreq : string = "average frequency" -length : string = "length" +ResourceRoot = 3
-averageL1Freq : string = "average L1 frequency" -none : string = "none" +SamplingRoot = 4
-density : string = "density" -permutation : string = "permutation" +PreprocessRoot = 5
-none : string = "none" -itemCount : int = 3 +CrossValidationRoot = 6
-size : string = "size" -all : string[] = new string[itemCount] +ClassificationRoot = 7
-totalFreq : string = "total frequency" -GetAllItems() : string[] +Corpus = 13
-itemCount : int = 6 +All() : string[] +CorpusSel = 14
-all : string[] = new string[itemCount] +Length() : string +Class = 0
-GetAllItems() : string[] +None() : string +ClassSel = 1
+All() : string[] +Permutation() : string +Document = 2
+AverageFreq() : string +STreeNotCreated = 9
+AverageL1Freq() : string +STreeCreated = 10
+Density() : string +TestDocument = 11
+None() : string +NewDocument = 12
+Size() : string +NewDocumentAdded = 21
+TotalFreq() : string +MisClassifyDocument = 20
+ClassificationSet = 15
+SamplingSet = 16
DataType::ScoringFunctions +PreprocessingSet = 16
-constant : string = "constant" +ClassificationData = 17
-cosine : string = "cosine" +TestSet = 18
-linear : string = "linear" DataType::RootNodes +TrainingSet = 19
-logit : string = "logit" -resource_corpus : string = "Resource Sets"
-root : string = "root" -sampling_corpus : string = "Sampling Sets"
-sigmoid : string = "sigmoid" -preprocess_corpus : string = "Pre-Processed Sets"
-square : string = "square" -crossValidation_set : string = "Cross-Validation"
-itemCount : int = 7 -classification : string = "Classification"
-all : string[] = new string[itemCount] +ResourceName() : string
-GetAllItems() : string[] +ResourceIdx() : int
+All() : string[] +SamplingName() : string
+Constant() : string +SamplingIdx() : int
+Cosine() : string +PreprocessName() : string
+Linear() : string +PreprocessIdx() : int
+Logit() : string +CrossValidationName() : string
+Root() : string +CrossValidationIdx() : int
+Sigmoid() : string +ClassificationName() : string
+Square() : string +ClassificationIdx() : int
90 of 93](https://image.slidesharecdn.com/msword556/85/msword-90-320.jpg)
![User Interfaces:
UI::SelectScoringMethod UI::MainForm
-btCancel : Button -tvExplorer : TreeView
-fdrdialogDest : FolderBrowserDialog -mainMenu1 : MainMenu
-groupBox4 : GroupBox -mItemResources : MenuItem
-label1 : Label -mItemAddRCorpus : MenuItem
-txtLeadVal : TextBox -fdrdialogCorpus : FolderBrowserDialog
-components : Container = null -imageList1 : ImageList
-groupBox1 : GroupBox -components : IContainer
+lstScoringFunc : ListBox -mitemVisualise : MenuItem
-groupBox2 : GroupBox -mitemCreateSTree : MenuItem
+lstMatchNorm : ListBox -cmenu : ContextMenu
-groupBox3 : GroupBox -splitter1 : Splitter
+lstTreeNorm : ListBox -sTreeView : TreeView
-btOK : Button -pnlSTreeView : Panel
-datagridClassWeights : DataGrid -lblSTreeDetail : Label
-openFileDialog1 : OpenFileDialog -splitter2 : Splitter
-dataTable : DataTable -openFileDialog1 : OpenFileDialog
-dataSet : DataSet -AddClassificationSet : MenuItem
-sqlClassWeightList : string[] -pnltxtView : Panel
-sqlScoreLead : string -toolTip1 : ToolTip
-sourceParentPath : string -listView1 : ListView
-sourcePath : string -splitter3 : Splitter
-nCount : int -rtxtView : RichTextBox
+SQLWeightList() : string[] -ClassifyAllDocs : MenuItem
+SQLScoreLead() : string -RemoveFile : MenuItem
-SourcePath() : string -ScoreAllNewDocs : MenuItem
-SourceParentPath() : string -ClassifyAllNewDocuments : MenuItem
-Count() : int -pnlExplorerTree : Panel
+SelectScoringMethod(in reader : OleDbDataReader, in leadVal : string, in sourceParentNodePath : string, in sourceNodePath : string, in ScoringFunctions : string[], in matchNormalisations : string[], in treeNormalisations : string[]) -splitter4 : Splitter
-PopulateClassWeightBox(in reader : OleDbDataReader) -rtxtInfo : RichTextBox
#Dispose(in disposing : bool) -centralMgr : DisplayManager
-InitializeComponent() -mitemSelectSampling : MenuItem
-btOK_Click(in sender : object, in e : EventArgs) -mitemPreprocess : MenuItem
-BuildUpdateScoreLeadSQL() -mitemCrossValidation : MenuItem
-BuildUpdateClassWeightsSQL() -menuItem1 : MenuItem
-mItemExit : MenuItem
-msg : ToolTip
+MainForm()
UI::SelectChoiceDialog #Dispose(in disposing : bool)
-fdrdialogDest : FolderBrowserDialog -InitializeComponent()
+cbSystematic : ComboBox -Main()
-components : Container = null -MainForm_Load(in sender : object, in e : EventArgs)
-btCreateSampleCorpus : Button -mItemAddRCorpus_Click(in sender : object, in e : EventArgs)
-lblSelType : Label -tvExplorer_AfterSelect(in sender : object, in e : TreeViewEventArgs)
-btCancel : Button -mitemSelectSampling_Click(in sender : object, in e : EventArgs)
+SelectChoiceDialog(in formName : string, in labelName : string, in list : ArrayList) -mitemPreprocess_Click(in sender : object, in e : EventArgs)
#Dispose(in disposing : bool) -mitemCrossValidation_Click(in sender : object, in e : EventArgs)
-InitializeComponent() -cmenu_Popup(in sender : object, in e : EventArgs)
-btCancel_Click(in sender : object, in e : EventArgs) -CreateSTreeMenuItems()
-CreateSTree_Click(in sender : object, in e : EventArgs)
-DeleteSTree_Click(in sender : object, in e : EventArgs)
-DisplaySuffixTree_Click(in sender : object, in e : EventArgs)
UI::SelectionDialog UI::SelectTextDialog -GetDataSourceNode(in sTreeNode : TreeNode) : TreeNode
-groupBox1 : GroupBox -fdrdialogDest : FolderBrowserDialog -AddNewDoc_Click(in sender : object, in e : EventArgs)
-btEditPunctuation : Button -components : Container = null -AddClassificationSet_Click(in sender : object, in e : EventArgs)
-btRun : Button -btCreateSampleCorpus : Button -rtxtView_MouseUp(in sender : object, in e : MouseEventArgs)
-btCancel : Button -lblType : Label -rtxtView_MouseEnter(in sender : object, in e : EventArgs)
+txtDest : TextBox +txtValue : TextBox -ScoreAllDoc_Click(in sender : object, in e : EventArgs)
-btBrowseDest : Button -btCancel : Button -ClassifyAllDocs_Click(in sender : object, in e : EventArgs)
-fdrdialogDest : FolderBrowserDialog -ClassifyAllNewDocuments_Click(in sender : object, in e : EventArgs)
+SelectTextDialog(in formName : string, in labelName : string)
+lblSelType : Label -RemoveFile_Click(in sender : object, in e : EventArgs)
#Dispose(in disposing : bool)
+cbSelTypeOptions : ComboBox -mItemExit_Click(in sender : object, in e : EventArgs)
-InitializeComponent()
-lstAvail : ListBox
-btCancel_Click(in sender : object, in e : EventArgs)
+lstSelected : ListBox
-txtValue_TextChanged(in sender : object, in e : EventArgs)
-btSelect : Button
-btRemove : Button
-label1 : Label
-label2 : Label
-grpDest : GroupBox
-components : Container = null
-centralMgr : DisplayManager UI::CrossValidationDialog
-systematicStep : string -btRun : Button
-randonRatio : string -btCancel : Button
+SystematicStep() : string -fdrdialogDest : FolderBrowserDialog
+RandonRatio() : string +lblSelType : Label
+SelectionDialog(in d : DisplayManager, in formName : string, in baseType : string, in itemList : string[], in defaultItem : string, in destEnable : bool, in selectionsAvail : string[]) -components : Container = null
-PopulateListBox(in selectionsAvail : string[]) +cbTypeOptions : ComboBox
#Dispose(in disposing : bool) -label1 : Label
-InitializeComponent() +cbFolds : ComboBox
-btBrowseDest_Click(in sender : object, in e : EventArgs) -centralMgr : DisplayManager
-btRun_Click(in sender : object, in e : EventArgs) +CrossValidationDialog(in d : DisplayManager, in formName : string, in baseType : string, in itemList : string[], in defaultItem : string)
-btSelect_Click(in sender : object, in e : EventArgs) #Dispose(in disposing : bool)
-btRemove_Click(in sender : object, in e : EventArgs) -InitializeComponent()
Methods:
DataMining::Stemmer DataMining::Punctuation
-name : string -name : string
-error : string -stringList : ArrayList = new ArrayList()
-b : char[] -error : string
-i : int +Name() : string
-i_end : int +Run(in text : string) : string
-j : int +ErrorMessage() : string
-k : int +Punctuation(in filePathName : string)
-INC : int = 50 +Add(in filePathName : string)
+Name() : string -AddWord(in targetWord : string)
+Run(in text : string) : string +Clear()
+ErrorMessage() : string +Reset()
+Stemmer() +Contains(in word : string) : bool
+add(in ch : char) +StringList() : ArrayList
+add(in w : char[], in wLen : int)
+ToString() : string
+getResultLength() : int
+getResultBuffer() : char[]
-cons(in i : int) : bool
DataMining::StopWord
-m() : int
-vowelinstem() : bool -name : string
-doublec(in j : int) : bool -stringList : ArrayList = new ArrayList()
-cvc(in i : int) : bool -error : string
-ends(in s : string) : bool +Name() : string
-setto(in s : string) +Run(in text : string) : string
-r(in s : string) +ErrorMessage() : string
-step1() +StopWord(in filePathName : string)
-step2() +Add(in filePathName : string)
-step3() -AddWord(in targetWord : string)
-step4() +Clear()
-step5() +Reset()
-step6() +Contains(in word : string) : bool
+stem() +StringList() : ArrayList
91 of 93](https://image.slidesharecdn.com/msword556/85/msword-91-320.jpg)
![Utility:
IO::FileSystem
-dir : DirectoryInfo
+GetDirName(in dirPath : string) : string
+GetDirRoot(in dirPath : string) : string
+CopyDirectory(in src : string, in dest : string, in maxDepth : int, in level : int)
Utility::CommonDivisor
+GetCommonDivisors(in numbers : int[]) : ArrayList
-FindCommonDivisors(in numsToCheck : ArrayList, in nums : ArrayList) : ArrayList
Utility::RandomNumberGenerator
-r : Random = new Random((int)DateTime.Now.Ticks)
+Next(in bound : int) : int
92 of 93](https://image.slidesharecdn.com/msword556/85/msword-92-320.jpg)

























































