Downloaded 106 times












![Document / Model / Controller
Model (advertiser.js) Document
Haystack examples sent us in
wrong direction initially
exports.all = function(req, res) {!
! findQuery = { near: [ Number(req.query.lng), Number(req.query.lat) ],!
! ! maxDistance: Number(req.query.dist) };!
! Advertiser.geoSearch({kind:"pub"}, findQuery, !
! ! function (err, advertisers) {!
// error handling!
! !! res.jsonp(advertisers);!
! ! });!
}
13
{
name: ‘Long Hall’,
pos: [-6.265535, 53.3418364],
kind: “pub”
}
AdvertiserSchema = new Schema({!
name: { type: String,!
default: ‘’},!
pos: [Number],!
kind: { type: String,!
default: ‘place’},!
}); Controller (advertisers.js)](https://image.slidesharecdn.com/mongodbiotrefmeanlondon2014v3-141106090249-conversion-gate02/85/MongoDB-and-the-MEAN-Stack-13-320.jpg)





![To find out what’s happening - debug
We used Express passport-http to add Basic-
Digest auth (client id lookup)
It can be hard to figure out what a framework like
express/mongoose really does
Tip: mongoose.set('debug', true) - detailed logging
Console
Mongoose: clients.findOne({ _id: ObjectId(“…”) })!
Mongoose: advertisers.geoHaystack({…[-6.267765, 53.34087]})!
19](https://image.slidesharecdn.com/mongodbiotrefmeanlondon2014v3-141106090249-conversion-gate02/85/MongoDB-and-the-MEAN-Stack-19-320.jpg)





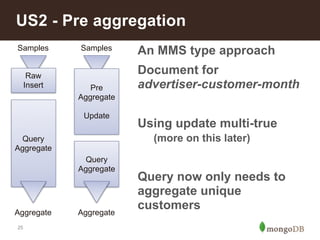

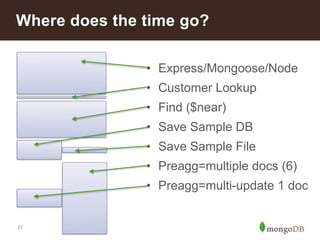

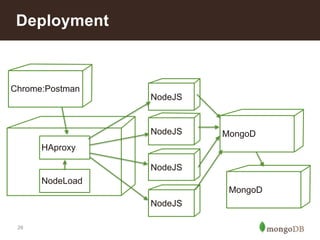
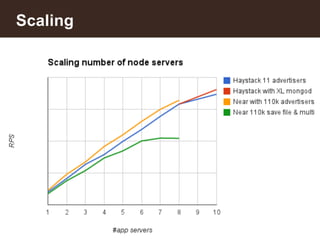


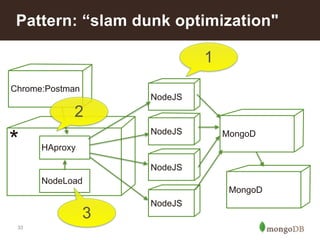



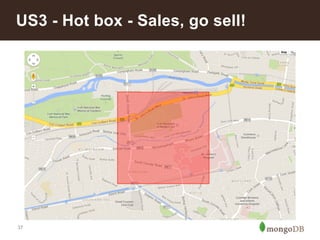



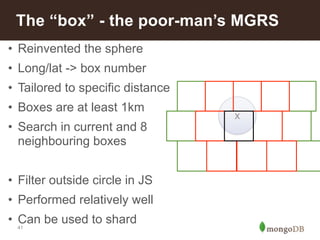
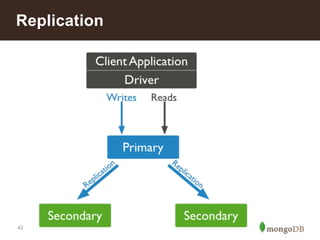
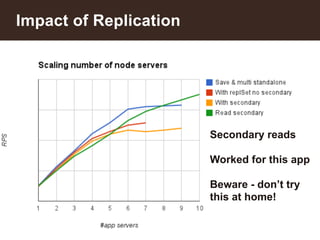









This document summarizes a presentation about building an IoT application using the MEAN stack. It discusses five key things they learned: performance depends on test data; MEAN is fast to develop with but frameworks can obscure what's happening so profiling is important; incremental aggregation works well for IoT; Node.js bottlenecks before MongoDB; and performance tuning patterns like identifying bottlenecks and slam-dunk optimizations. It also describes building user stories for an advertising application, modeling the data, initial measurements that guided prototyping, challenges of scaling, and using "boxes" to identify hot sales areas.


































































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)































