Downloaded 96 times












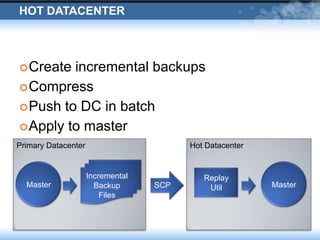

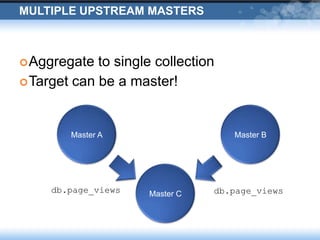
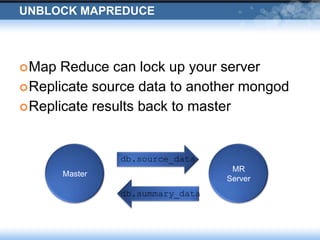
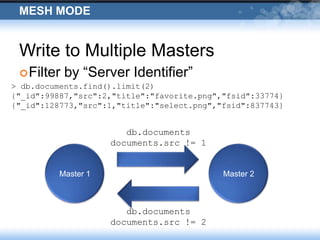


The presentation discusses Wordnik's use of MongoDB, highlighting its robust performance and necessary management strategies for maintaining large datasets. It covers various operational insights, including replication, incremental backups, and disaster recovery scenarios. The document emphasizes the importance of careful data handling and the collaborative efforts between engineering and IT operations.




















































































