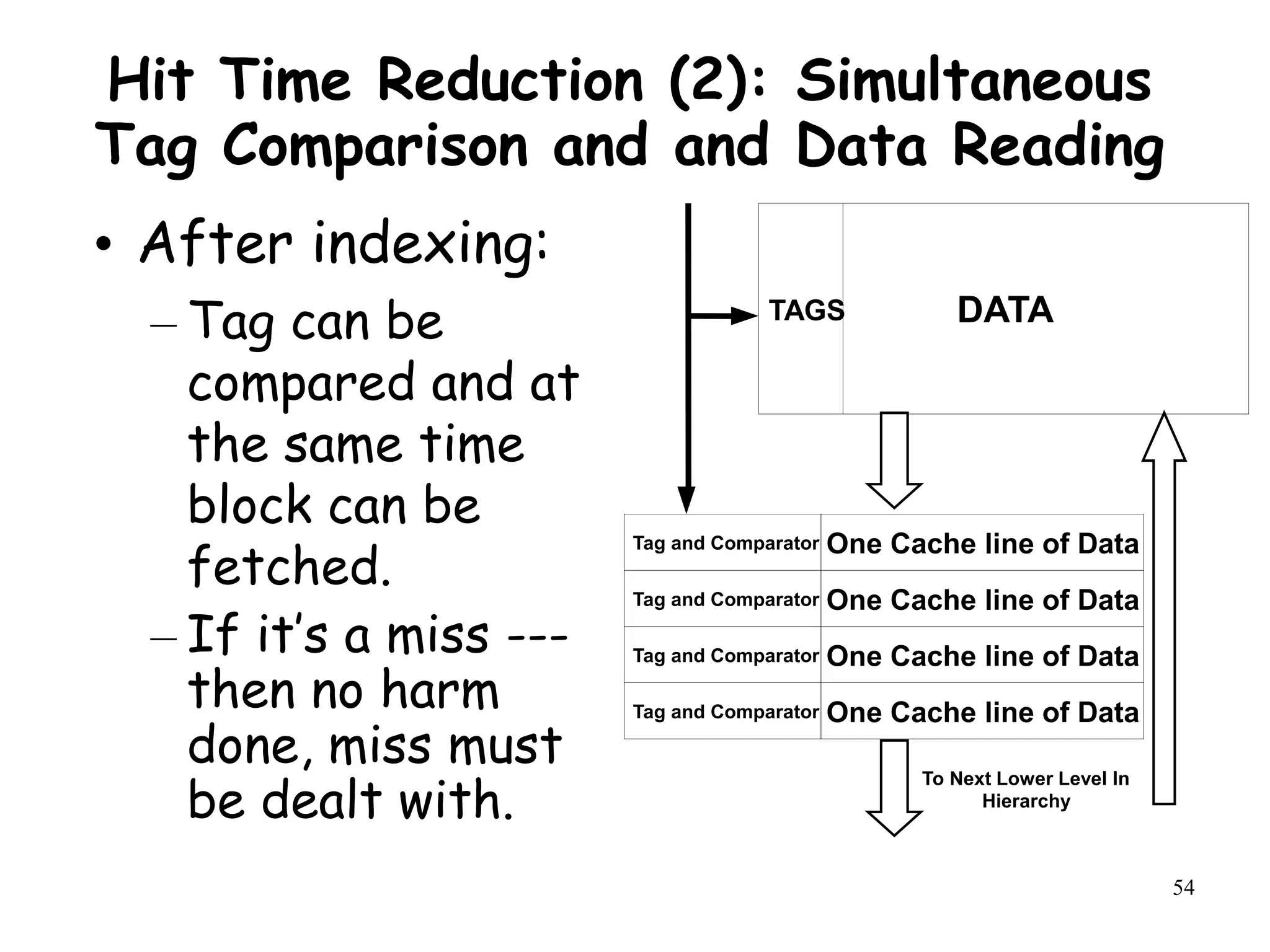
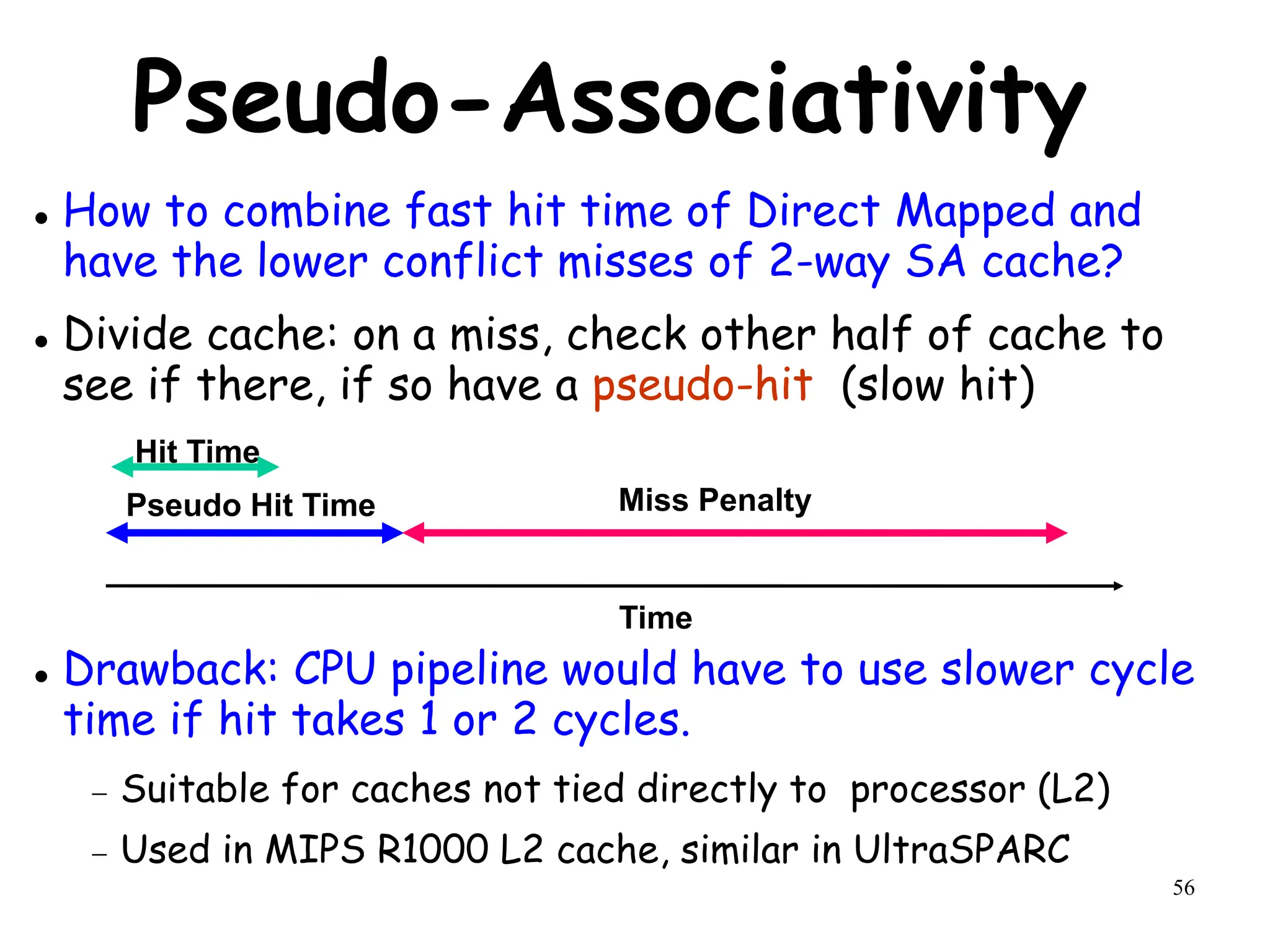
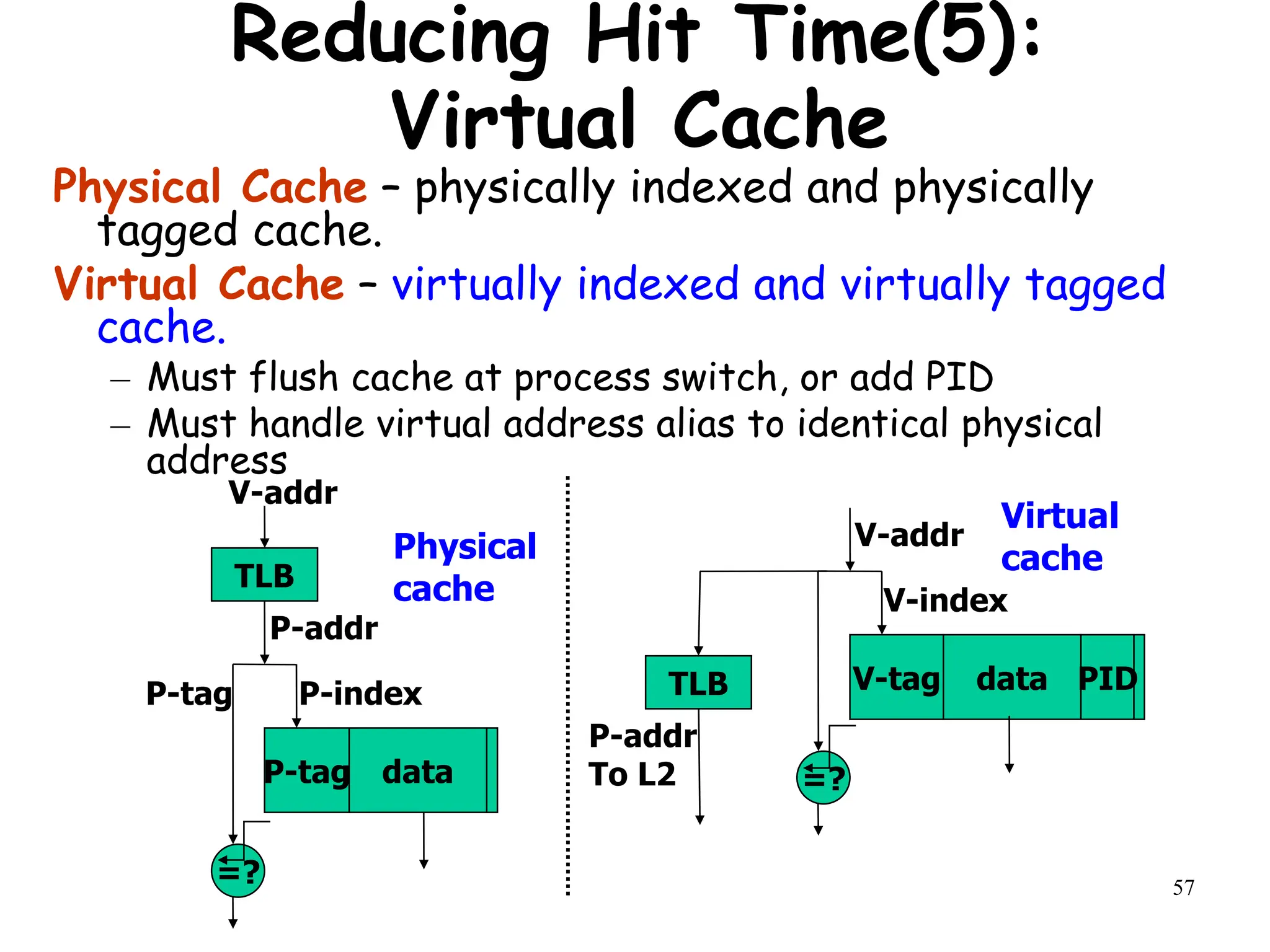
The document discusses techniques to improve memory hierarchy performance in computer systems. It covers cache organization and optimizations such as block placement, identification, and replacement strategies. It also discusses write policies, cache performance metrics like hit time and miss rate, and how they impact average memory access time (AMAT) and processor performance. Specific techniques are presented to reduce cache miss penalties, hit times, and miss rates to lower AMAT, such as using multiple cache levels, victim caches, and increasing cache size or associativity.










![14
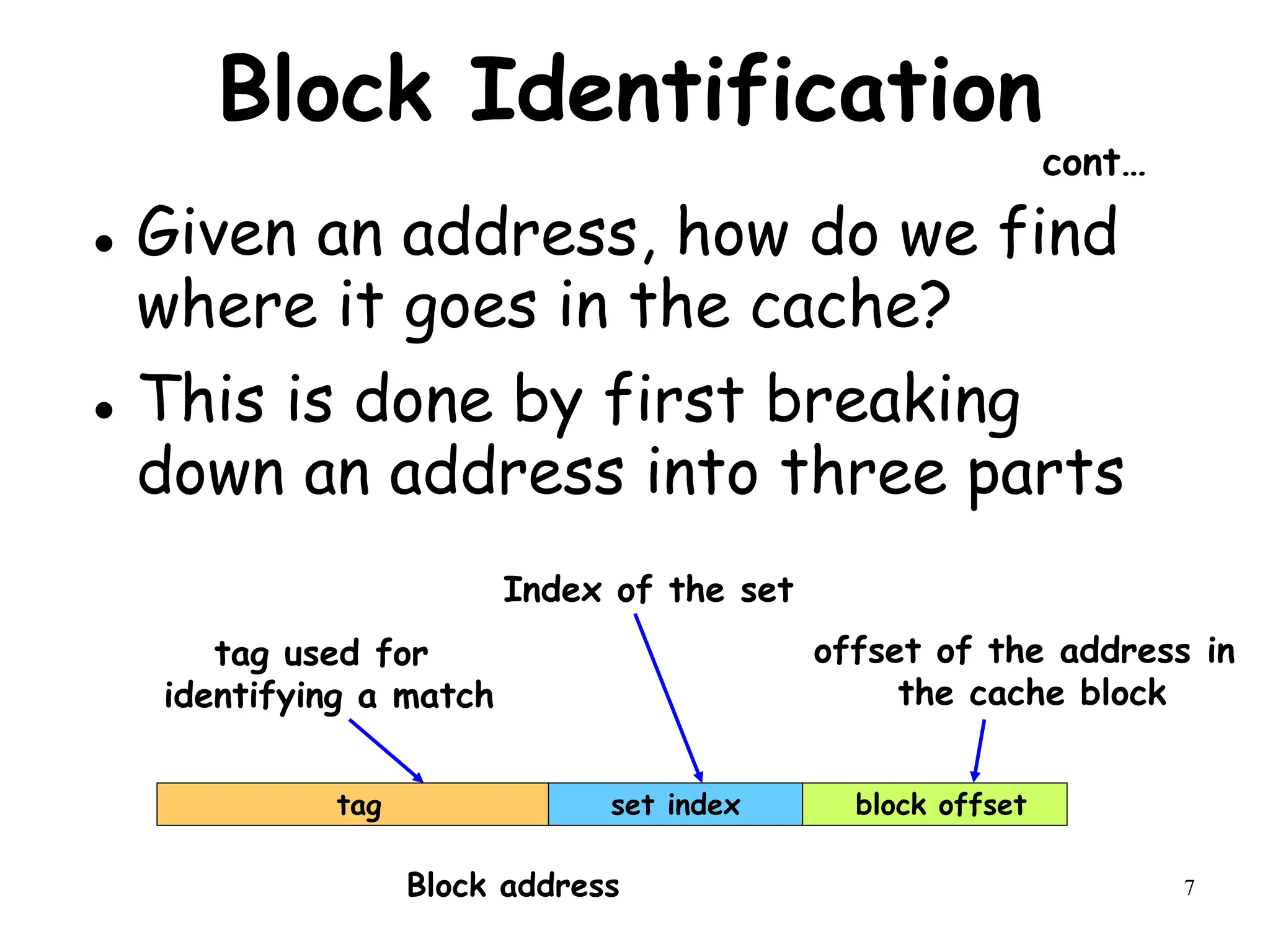
Write Allocate vs No-write Allocate
Assume a fully associative write-back cache with many cache entries that starts
empty. Below is a sequence of five memory operations :
Write Mem[100];
WriteMem[100];
Read Mem[200];
WriteMem[200];
WriteMem[100].
What are the number of hits and misses when using no-write allocate versus write
allocate?
Answer:
For no-write allocate,
the address 100 is not in the cache, and there is no allocation on write, so the first
two writes will result in misses. Address 200 is also not in the cache, so the read is
also a miss. The subsequent write to address 200 is a hit. The last write to 100 is still
a miss. The result for no-write allocate is four misses and one hit.
For write allocate,
the first accesses to 100 and 200 are misses, and the rest are hits since 100 and 200
are both found in the cache. Thus, the result for write allocate is two misses and
three hits.](https://image.slidesharecdn.com/module3-231227064532-51cac9f8/75/module3-ppt-14-2048.jpg)
![15
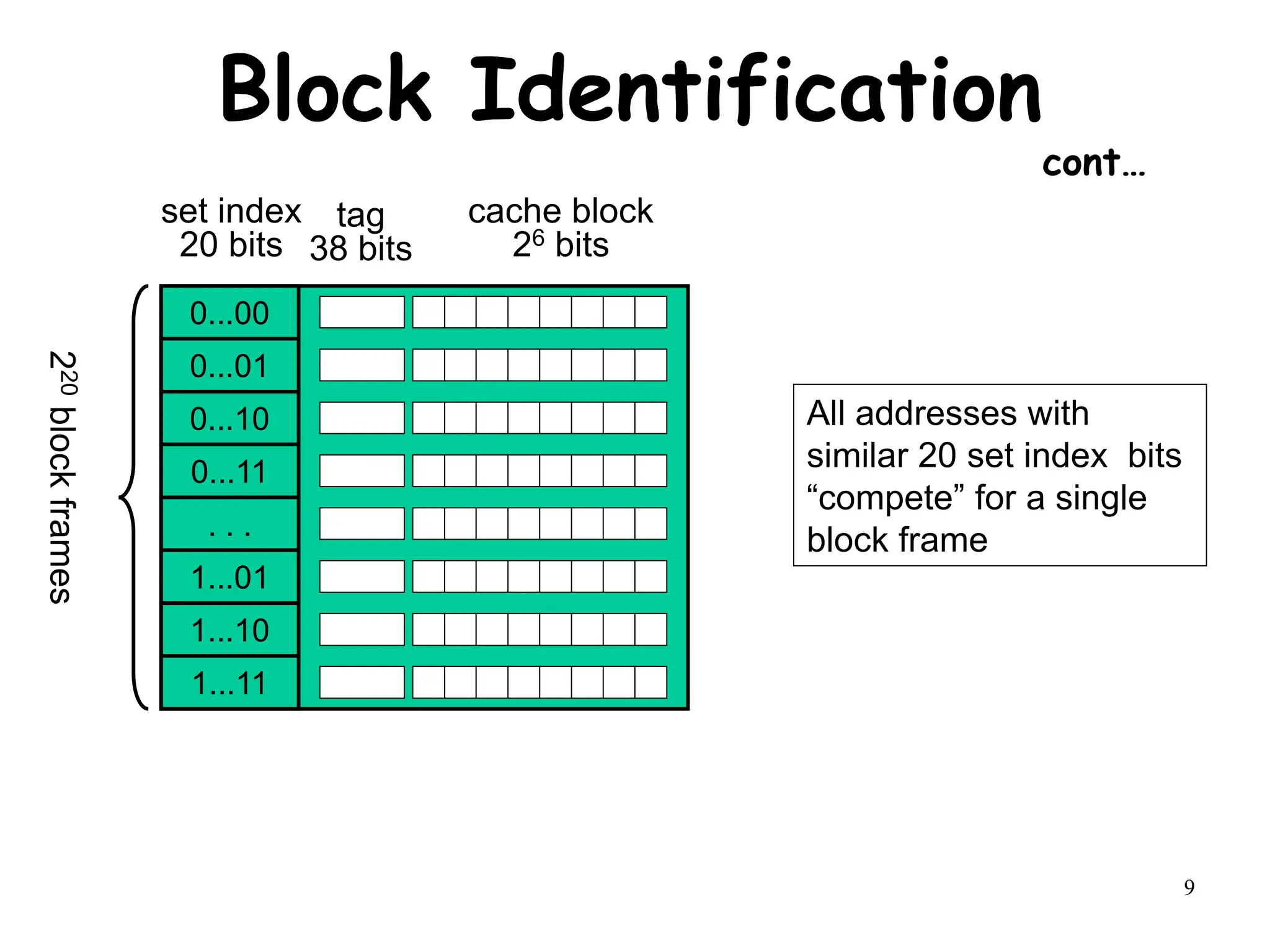
Write Allocate vs No-write Allocate
Assume a fully associative write back cache with many cache entries that starts empty.
Below is a sequence of 5 memory operations (the address is in square brackets).
WriteMem [100]
WriteMem [200]
ReadMem [300]
WriteMem [200]
WriteMem [300]
What are the numbers of hits and misses when using no-write allocate Vs write
allocate?
No-Write Allocate Write Allocate
WriteMem [100] Miss Miss
WriteMem [200] Miss Miss
ReadMem [300] Miss Miss
WriteMem [200] Miss Hit
WriteMem [300] Hit Hit](https://image.slidesharecdn.com/module3-231227064532-51cac9f8/75/module3-ppt-15-2048.jpg)






![22
Performance Example 1
cont…
CPI = ideal CPI + average stalls per
instruction = 1.1(cycles/ins) + [ 0.30
(DataMops/ins)
x 0.10 (miss/DataMop) x 50 (cycle/miss)]
+[ 1 (InstMop/ins)
x 0.01 (miss/InstMop) x 50 (cycle/miss)]
= (1.1 + 1.5 + .5) cycle/ins = 3.1
AMAT=(1/1.3)x[1+0.01x50]+(0.3/1.3)x[1+0.1x5
0]=2.54](https://image.slidesharecdn.com/module3-231227064532-51cac9f8/75/module3-ppt-22-2048.jpg)






















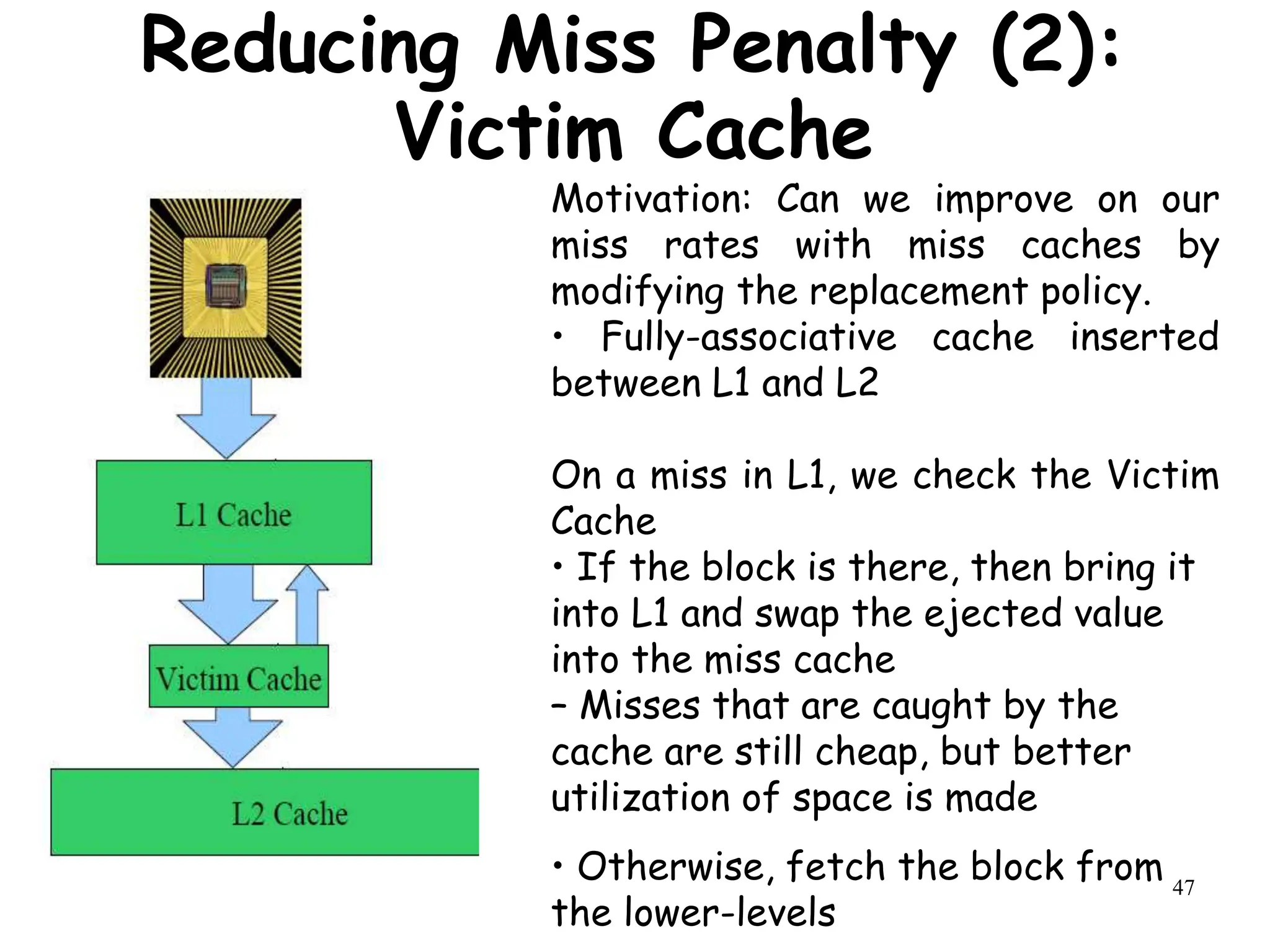
![46
Reducing Miss Penalty (2):
Victim Cache
How to combine fast hit time of direct
mapped cache:
yet still avoid conflict misses?
Add a fully associative buffer (victim
cache) to keep data discarded from cache.
Jouppi [1990]:
A 4-entry victim cache removed 20% to 95%
of conflicts for a 4 KB direct mapped data
cache.
AMD uses 8-entry victim buffer.](https://image.slidesharecdn.com/module3-231227064532-51cac9f8/75/module3-ppt-46-2048.jpg)