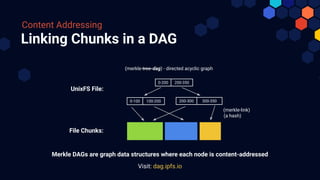
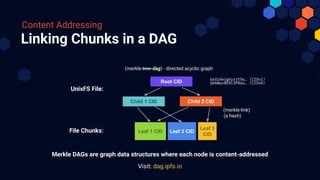
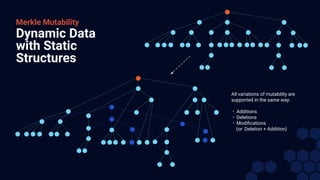
The document outlines the significance and functionality of Interplanetary Linked Data (IPLD) and its relationship with IPFS. It discusses fundamental concepts of IPLD such as Merkle DAGs, content addressing, and various coding formats designed for efficient data representation and traversal. Additionally, it highlights the potential of IPLD to facilitate complex, scalable, peer-to-peer data structures beyond traditional file-based systems.











![Git
Merkle Roots: Commit
Author + TS
Committer + TS
Message
Tree (hash)
Parent (hash)
Commit
Author + TS
Committer + TS
Message
Tree (hash)
Parent (hash)
Commit
Author + TS
Committer + TS
Message
Tree (hash)
Parent (hash)
Tree
Blob (hash)...
Tree (hash)...
Tree
Blob (hash)...
Tree
Blob (hash)...
Tree
Blob (hash)...
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]](https://image.slidesharecdn.com/moduleipld-210608114346/85/Module-InterPlanetary-Linked-Data-IPLD-13-320.jpg)
![Git
Merkle Roots: Commit
Author + TS
Committer + TS
Message
Tree (hash)
Parent (hash)
Commit
Author + TS
Committer + TS
Message
Tree (hash)
Parent (hash)
Commit
Author + TS
Committer + TS
Message
Tree (hash)
Parent (hash)
Tree
Blob (hash)...
Tree (hash)...
Tree
Blob (hash)...
Tree
Blob (hash)...
Tree
Blob (hash)...
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Root
e9c8097d...](https://image.slidesharecdn.com/moduleipld-210608114346/85/Module-InterPlanetary-Linked-Data-IPLD-15-320.jpg)
![Git
Merkle Roots: Commit
Author + TS
Committer + TS
Message
Tree (hash)
Parent (hash)
Commit
Author + TS
Committer + TS
Message
Tree (hash)
Parent (hash)
Commit
Author + TS
Committer + TS
Message
Tree (hash)
Parent (hash)
Tree
Blob (hash)...
Tree (hash)...
Tree
Blob (hash)...
Tree
Blob (hash)...
Tree
Blob (hash)...
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Root
3a8cb91d...
Root
e9c8097d...](https://image.slidesharecdn.com/moduleipld-210608114346/85/Module-InterPlanetary-Linked-Data-IPLD-16-320.jpg)
![Git
Merkle Roots: Commit
Author + TS
Committer + TS
Message
Tree (hash)
Parent (hash)
Commit
Author + TS
Committer + TS
Message
Tree (hash)
Parent (hash)
Commit
Author + TS
Committer + TS
Message
Tree (hash)
Parent (hash)
Tree
Blob (hash)...
Tree (hash)...
Tree
Blob (hash)...
Tree
Blob (hash)...
Tree
Blob (hash)...
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Root
9c2542a8...
Root
e9c8097d...
Root
3a8cb91d...](https://image.slidesharecdn.com/moduleipld-210608114346/85/Module-InterPlanetary-Linked-Data-IPLD-17-320.jpg)
![Git
Merkle Roots: Commit
Author + TS
Committer + TS
Message
Tree (hash)
Parent (hash)
Commit
Author + TS
Committer + TS
Message
Tree (hash)
Parent (hash)
Commit
Author + TS
Committer + TS
Message
Tree (hash)
Parent (hash)
Tree
Blob (hash)...
Tree (hash)...
Tree
Blob (hash)...
Tree
Blob (hash)...
Tree
Blob (hash)...
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Blob
byte
[...]
Root
9c2542a8...
Root
e9c8097d...
Root
3a8cb91d...](https://image.slidesharecdn.com/moduleipld-210608114346/85/Module-InterPlanetary-Linked-Data-IPLD-18-320.jpg)







![A Familiar Data Interface
The Data Model:
The Data Model includes the
common fundamentals available in
most programming languages.
const data = {
string: "☺ we can do strings!",
ints: 1337,
floats: 13.37,
booleans: true,
arrays: [1, 2, 3],
bytes: new Uint8Array([0x01, 0x03, 0x03, 0x07]),
links:
CID(bafyreidykglsfhoixmivffc5uwhcgshx4j465xwqntbmu43nb2dzqwfvae)
}](https://image.slidesharecdn.com/moduleipld-210608114346/85/Module-InterPlanetary-Linked-Data-IPLD-26-320.jpg)
![DAG-JSON
The Data Model:
DAG-JSON extends JSON, adding
determinism, a format for Bytes
and a format for Links
{
"arrays": [1, 2, 3],
"booleans": true,
"bytes": { "/":
{ "bytes": "AQMDBw" }
},
"floats": 13.37,
"ints": 1337,
"links": { "/":
"bafyreidykglsfhoixmivffc5uwhcgshx4j465xwqntbmu43nb2dzqwfvae"
},
"string": "☺ we can do strings!"
}](https://image.slidesharecdn.com/moduleipld-210608114346/85/Module-InterPlanetary-Linked-Data-IPLD-27-320.jpg)
![DAG-CBOR
The Data Model:
DAG-CBOR is a strict subset
of CBOR with determinism
and a special tag to identify
CIDs
a764696e74731905396562797465734401030307656c696e6b73d82a58250001711220785197229dc8bb115294
5da58e2348f7e279eeded06cc2ca736d0e879858b501666172726179738301020366666c6f617473fb402abd70
a3d70a3d66737472696e67781ae298baefb88f202077652063616e20646f20737472696e67732168626f6f6c65
616e73f5
a7 # map(7)
64 # string(4)
696e7473 # "ints"
19 0539 # uint(1337)
65 # string(5)
6279746573 # "bytes"
44 # bytes(4)
01030307 # "x01x03x03x07"
65 # string(5)
6c696e6b73 # "links"
d8 2a # tag(42)
58 25 # bytes(37)
0001711220785197229dc8bb1152945da58e2348f7 # "x00x01qx12 xQ"]¥#H÷"
e279eeded06cc2ca736d0e879858b501 # "âyîÞÐlÂÊsmx0e"
66 # string(6)
617272617973 # "arrays"
83 # array(3)
01 # uint(1)
02 # uint(2)
03 # uint(3)
66 # string(6)
666c6f617473 # "floats"
fb 402abd70a3d70a3d # float(13.37)
66 # string(6)
737472696e67 # "string"
78 1ae298baef # string(22)
e298baefb88f202077652063616e20646f2073747269 # "☺ we can do stri"
6e677321 # "ngs!"
68 # string(8)
626f6f6c65616e73 # "booleans"
f5 # true](https://image.slidesharecdn.com/moduleipld-210608114346/85/Module-InterPlanetary-Linked-Data-IPLD-28-320.jpg)
![Round-trip Through the Data Model
The Data Model:
IPLD’s Data Model is a stable
system for addressing,
constructing, encoding and
decoding data for a content
addressed world.
const data = {
string: "☺ we can do strings!",
ints: 1337,
floats: 13.37,
booleans: true,
arrays: [1, 2, 3],
bytes: new Uint8Array([0x01, 0x03, 0x03, 0x07]),
links:
CID(bafyreidykglsfhoixmivffc5uwhcgshx4j465xwqntbmu43nb2dzqwfvae)
}](https://image.slidesharecdn.com/moduleipld-210608114346/85/Module-InterPlanetary-Linked-Data-IPLD-29-320.jpg)


![Example: Super-large array
Scaling addressable datasets
[ e1, e2, e3, e4, e5 ]
● Single block with 5 elements and one CID
for that block](https://image.slidesharecdn.com/moduleipld-210608114346/85/Module-InterPlanetary-Linked-Data-IPLD-32-320.jpg)
![Example: Super-large array
[ e1, e2, e3, e4, e5 ] [ e6, e7, e8 ]
[ L1.1, L1.2 ]
Height: 2
Height: 1
● Three distinct content addressed blocks
● Three CIDs
● Two leaf nodes containing our data
● One root to address all content in the DAG](https://image.slidesharecdn.com/moduleipld-210608114346/85/Module-InterPlanetary-Linked-Data-IPLD-33-320.jpg)
![Example: Super-large array
[ e6, e7, e8, e9, e10] [ e11, e12, e13, e14, e15] [ e21, e22, e23, e24, e25 ]
[ e16, e17, e18, e19, e20]
[ e1, e2, e3, e4, e5 ]
[ L1.1, L1.2, L1.3, L1.4, L1.5 ]
Height: 2
Height: 1](https://image.slidesharecdn.com/moduleipld-210608114346/85/Module-InterPlanetary-Linked-Data-IPLD-34-320.jpg)
![Example: Super-large array
[ L2.1, L2.2 ]
[ L1.6 ]
[ L1.1, L1.2, L1.3, L1.4, L1.5 ]
[ e6, e7, e8, e9, e10] [ e11, e12, e13, e14, e15] [ e21, e22, e23, e24, e25 ] [ e26 ]
[ e16, e17, e18, e19, e20]
[ e1, e2, e3, e4, e5 ]
Height: 2
Height: 1
Height: 3](https://image.slidesharecdn.com/moduleipld-210608114346/85/Module-InterPlanetary-Linked-Data-IPLD-35-320.jpg)
![Example: Super-large array Algorithms for
“Advanced Data
Layouts”
[ L2.1, L2.2 ]
[ L1.6 ]
[ L1.1, L1.2, L1.3, L1.4, L1.5 ]
[ e6, e7, e8, e9, e10] [ e11, e12, e13, e14, e15] [ e21, e22, e23, e24, e25 ] [ e26 ]
[ e16, e17, e18, e19, e20]
class Node {
getElementAt (index) {
if (this.height > 1) {
const childIndex = Math.floor(index / (width ** (this.height-1)))
const newIndex = index % (width ** (this.height-1))
// load and traverse into a child
return this.getChildAt(childIndex).getElementAt(index)
}
// read directly from this node's data array
return this.elements[index]
}
}
[ e1, e2, e3, e4, e5 ]](https://image.slidesharecdn.com/moduleipld-210608114346/85/Module-InterPlanetary-Linked-Data-IPLD-36-320.jpg)















































